.png)


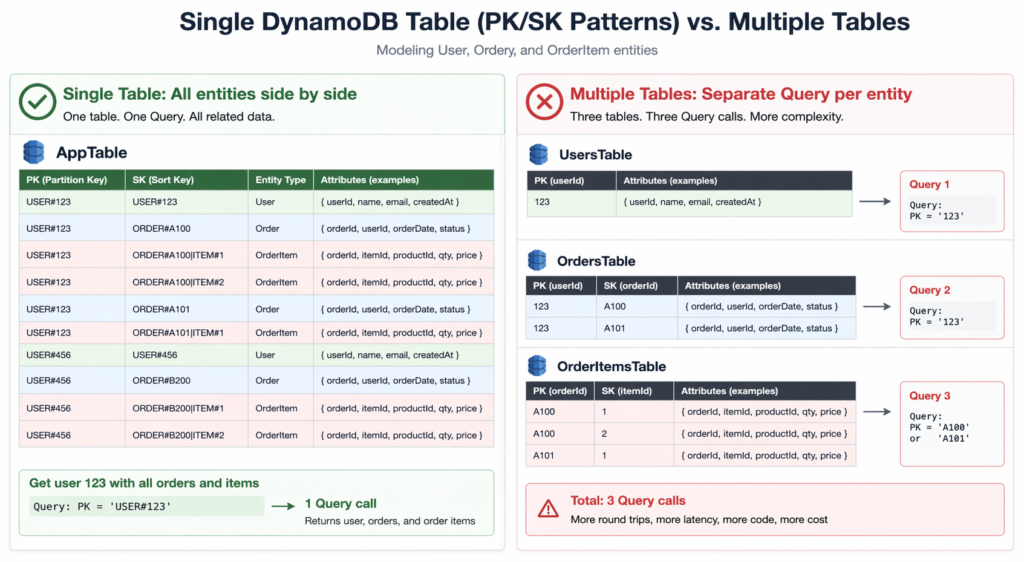
DynamoDB single-table design reduces read costs by fetching related entities in a single Query instead of multiple GetItem calls. For a typical e-commerce workload that fetches a user, their orders, and order items, a single-table design reduces the number of read operations from 3 to 1, reducing RCU consumption by roughly 67%.
At on-demand pricing of $0.25 per million RRU, that translates to real savings on read-heavy workloads. But the story does not end there. Single-table design also increases item size through denormalization, introduces GSI write amplification, and adds operational complexity.
Whether it actually saves you money depends on your capacity mode, read-to-write ratio, and item size distribution.
%2021%20(32).svg)
Where Does DynamoDB Single-Table Design Actually Save Money?
Single-table design produces measurable cost savings in exactly two areas: reduced read operations and shared provisioned capacity.
Savings Area 1: Fewer Read Operations
The primary DynamoDB single-table design cost advantage comes from item co-location. Items with the same partition key are stored on the same partition. A single Query on PK = “USER#123” with SK begins_with = “ORDER#” returns the user record and all their orders in one API call, consuming RCU based on the total data returned (rounded up to the nearest 4 KB for eventually consistent reads).
Without a single-table design, fetching the same data requires at least 2 API calls: one GetItem for the user, one Query on a separate orders table. Each call has its own RCU cost.
Worked example: Fetching a user (1 KB) plus their 10 most recent orders (1 KB each) = 11 KB total. Single-table design: 1 Query returning 11 KB = 3 RCU (eventually consistent, rounded up to 12 KB / 4 KB = 3). Multi-table design: 1 GetItem (1 KB, 0.5 RCU) + 1 Query (10 KB, 1.5 RCU) = 2 RCU total.
In this specific case, the multi-table design is actually cheaper per fetch because each operation’s RCU is calculated independently, while the single-table design pays for the full result set. The single-table advantage only appears when you would otherwise need 3+ separate API calls for deeply nested entity graphs.
Savings Area 2: Shared Provisioned Capacity Buffer
With provisioned capacity, each table needs its own WCU and RCU allocation. Teams typically over-provision by 20-30% as a safety buffer. With 8 separate tables, you over-provision 8 times. With 1 table, you over-provision once.
The buffer savings are real but modest: for 8 tables each provisioned at 50 RCU with a 25% buffer (totaling 500 RCU), consolidating to 1 table at 400 RCU with a 25% buffer (500 RCU) saves approximately 0-100 RCU depending on traffic correlation across entity types. At $0.00013/RCU-hour, that is $0 to $9.49/month. On on-demand tables, this savings disappears entirely because there is no provisioned buffer to share.
Also read: DynamoDB Reserved Capacity: Pricing for Read & Write Throughput
Where Does DynamoDB Single-Table Design Increase Costs?
Single-table design introduces three cost-increasing factors that most guides fail to quantify.
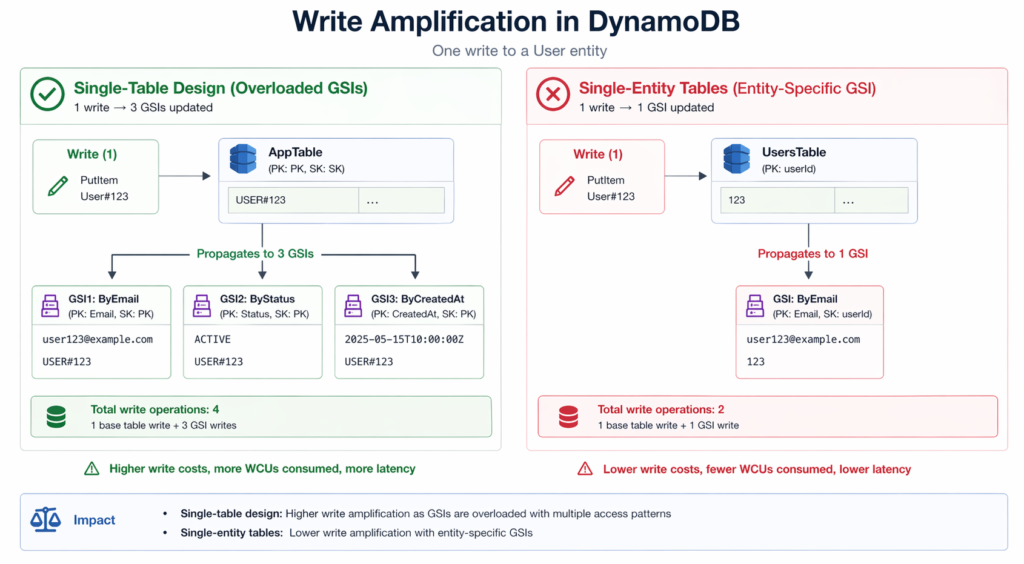
Cost Increase 1: GSI Write Amplification
A single-table design with 3 GSIs means every write to any entity in the table potentially propagates to all 3 GSIs, even if only 1 GSI is relevant to that entity type. DynamoDB writes to a GSI whenever the item contains the GSI’s key attributes. In a well-designed single-table, you use sparse GSIs (only items that contain the GSI key attributes are indexed), which mitigates this.
But many implementations index generic attributes like GSI1PK/GSI1SK across all entity types, causing every write to propagate to that GSI.
Worked example: 10 million writes/month to a single table with 3 GSIs where each GSI indexes all entity types = 10M base writes + 30M GSI writes = 40M total WRU. On-demand cost: 40M x $1.25/M = $50.00.
With multi-table design and entity-specific GSIs (1 GSI per table, only relevant entities indexed): 10M base writes + 10M GSI writes = 20M total WRU. On-demand cost: 20M x $1.25/M = $25.00. The DynamoDB GSI cost doubles in the single-table scenario because of unnecessary write amplification.
Cost Increase 2: Inflated Item Sizes from Denormalization
Single-table design requires adding generic key attributes (PK, SK, GSI1PK, GSI1SK, etc.) to every item. These attributes consume storage and increase the billable size of each read and write operation. A typical single-table item adds 50-150 bytes of key overhead compared to a dedicated table where the key is the natural entity identifier.
For 100 million items, 100 extra bytes per item = 10 GB of additional storage. At $0.25/GB-month, that is $2.50/month. Modest, but it compounds: each read and write also costs more because the item is larger. A 900-byte item that crosses 1 KB after adding 150 bytes of key overhead now costs 2 WRU per write instead of 1. That doubles the per-write cost for those items.
Cost Increase 3: Scan Costs for Analytics and Exports
A single table containing all entity types means a Scan operation reads every item in the table, regardless of entity type. If you need to export only Order entities and they represent 20% of the table, you still pay for scanning 100% of the data.
With separate tables, you scan only the Orders table. For a 50 GB single table, a full Scan costs approximately 12,500 RCU (50 GB / 4 KB). If you only needed 10 GB of Orders data, the multi-table Scan costs 2,500 RCU, an 80% reduction. Use DynamoDB Export to S3 for large analytics workloads to avoid this cost entirely ($0.10/GB regardless of table design).
Also read: DynamoDB Contributor Insights Pricing: Monitoring Hot Keys at a Cost
What Is the Net DynamoDB Single-Table Design Cost Impact?
The honest answer: it depends on your capacity mode, read-to-write ratio, and GSI design. Here is a worked comparison for a mid-scale e-commerce workload.
Assumptions: 50 million reads/month, 10 million writes/month, 25 GB storage, 3 entity types (Users, Orders, Products), 3 access patterns requiring GSIs. All prices US East, on-demand mode, April 2026.
| Cost Dimension | Single-Table Design | Multi-Table (3 tables) | Difference | Winner |
| Read operations | 35M RRU ($8.75) | 50M RRU ($12.50) | -$3.75 | Single-Table |
| Write operations (base) | 10M WRU ($12.50) | 10M WRU ($12.50) | $0.00 | Tie |
| GSI write propagation | 30M WRU ($37.50) | 10M WRU ($12.50) | +$25.00 | Multi-Table |
| Storage | 27 GB ($6.75) | 25 GB ($6.25) | +$0.50 | Multi-Table |
| Total monthly cost | $65.50 | $43.75 | +$21.75 | Multi-Table |
The net impact range: DynamoDB single-table design cost is anywhere from $5-10/month cheaper (with sparse GSIs) to $20-30/month more expensive (with overloaded GSIs) for a mid-scale workload. At enterprise scale (1 billion+ requests/month), multiply these differences by 20x.
Which DynamoDB Best Practices for Cost Saving Actually Move the Bill?
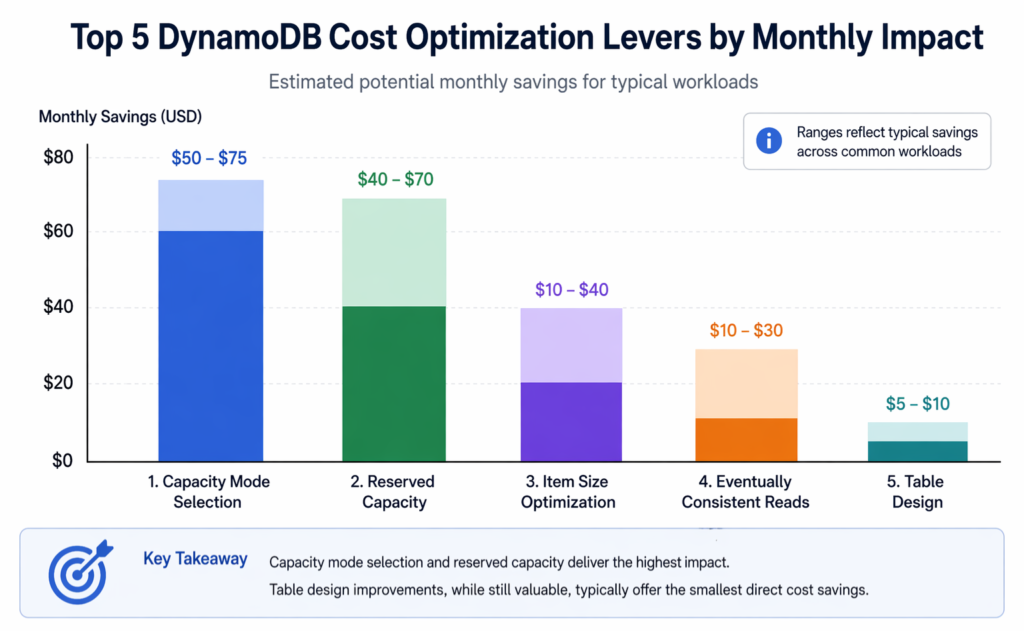
Table design (single vs multi) is a second-order cost lever. Here are the first-order levers, ranked by dollar impact.
1. Capacity Mode Selection (5-6x cost impact)
Provisioned mode at 70% utilization costs 3-4x less per request than on-demand. Switching from on-demand to provisioned for a steady 100M request/month workload saves approximately $50-75/month. This single decision has more cost impact than any table design choice.
2. Reserved Capacity (53-77% additional savings)
After choosing provisioned mode, reserved capacity saves another 53% (1-year) to 77% (3-year) on the provisioned rate. For 500 RCU + 100 WCU provisioned, reserved capacity saves approximately $40-70/month depending on the term. This stacks on top of the provisioned vs on-demand savings.
3. Item Size Optimization (1-3x cost multiplier)
DynamoDB bills reads in 4 KB blocks and writes in 1 KB blocks. An item at 1.1 KB costs 2 WRU per write, the same as a 2.0 KB item. Trimming attribute names, removing unused attributes, and compressing large text fields can drop items below the next billing threshold. Reducing average item size from 2.5 KB to 0.9 KB cuts per-write cost by 67%.
4. Eventually Consistent Reads (50% read cost reduction)
Eventually consistent reads consume 0.5 RCU per 4 KB versus 1.0 RCU for strongly consistent. If your application tolerates eventual consistency (most read-heavy UIs do), switching halves your read capacity consumption immediately.
5. Table Design: Single vs Multi (marginal impact)
As shown in the worked example above, single-table design produces savings of $5-10/month for a mid-scale workload when implemented correctly with sparse GSIs. When implemented poorly with overloaded GSIs, it costs more. The impact is 10-20x smaller than the capacity mode and reserved capacity decisions.
How Does DynamoDB Cost Optimization Change After You Pick the Right Table Design?
Once your table design is set (whether single or multi-table), the ongoing DynamoDB cost optimization shifts entirely to the capacity management layer: choosing between on-demand and provisioned, right-sizing provisioned capacity, and purchasing reserved capacity for stable baselines.
Usage.ai automates this capacity optimization through its Flex Reserved Instances product for DynamoDB. The platform monitors consumed read and write capacity across all your tables (single-table or multi-table), identifies stable baselines, and purchases reserved capacity blocks where utilization justifies the commitment. Usage.ai refreshes its analysis every 24 hours versus AWS Cost Explorer’s 72+ hour cycle. If a reservation becomes underutilized because workload patterns shift, Usage.ai provides cashback and credits on the unused portion. The fee is a percentage of realized savings only.
See how much you can save on DynamoDB with Usage.ai
Should You Refactor an Existing Multi-Table Design to a Single-Table?
Refactoring an existing multi-table DynamoDB deployment to single-table design is expensive in engineering time and carries migration risk. For the cost impact we have quantified ($5-10/month savings on a mid-scale workload), the return on engineering investment is rarely positive.
Refactor to single-table when: You are building a new service from scratch and have well-defined, stable access patterns. You have 5+ entity types that are routinely fetched together in the same API call. Your read-to-write ratio exceeds 10:1, maximizing the read operation savings.
Keep multi-table when: Your entity types scale independently (one entity type grows 10x while others stay flat). You need separate encryption keys, PITR settings, or table class configurations per entity type. Your team has limited DynamoDB modeling experience and the operational complexity of single-table design introduces migration risk.
%2024%20(22).svg)
Frequently Asked Questions
1. What are the advantages of DynamoDB single-table design?
Single-table design reduces read operations by co-locating related entities under the same partition key, enabling one Query to fetch data that would otherwise require multiple API calls. It also simplifies provisioned capacity management by consolidating traffic into one table, reducing over-provisioning buffers. These advantages are strongest for read-heavy workloads with well-defined access patterns.
2. Does DynamoDB single-table design save money on on-demand tables?
Minimal to zero savings on the table consolidation itself. On-demand pricing is per request, not per table. You do not pay less by having 1 table versus 8 tables. The only on-demand savings come from reduced read operations (fewer API calls), which single-table design can provide if it eliminates multi-table fetch patterns.
3. How much does a DynamoDB table cost?
A DynamoDB table has no fixed monthly fee. You pay for provisioned or on-demand read/write capacity, storage ($0.25/GB-month Standard class), and optional features (backups, Streams, GSIs). An empty, idle on-demand table costs $0.00/month. Storage and throughput charges scale with usage.
4. What is the difference between single-table and multi-table design in DynamoDB?
Single-table design stores all entity types (Users, Orders, Products) in one table using composite PK/SK keys. Multi-table design uses separate tables for each entity type. Single-table optimizes for read co-location and fewer API calls. Multi-table optimizes for independent scaling, simpler schemas, and per-entity configuration.
5. Does single-table design reduce DynamoDB GSI costs?
Not necessarily. Single-table design can reduce the number of GSIs if you reuse generic GSIs across entity types. But overloaded GSIs that index all entity types cause write amplification: every write propagates to every GSI, even for entity types that do not use that index. Sparse GSIs (where only relevant items contain the GSI key attributes) mitigate this cost.
6. What is the biggest DynamoDB cost optimization lever?
Capacity mode selection. Switching from on-demand to provisioned at 70% utilization saves 3-4x on per-request costs. Adding reserved capacity on top saves another 53-77%. These two decisions together can reduce your DynamoDB bill by 80-90% for stable workloads. Table design has 10-20x less cost impact than capacity mode selection.
7. Can you mix single-table and multi-table design?
Yes. Many production architectures use single-table design for tightly coupled entity groups (a user and their orders) and separate tables for independent entity types (analytics events, audit logs). This hybrid approach captures the read co-location benefit for related entities while keeping independent entities in their own tables for separate scaling and configuration.
8. How does DynamoDB single-table design affect DynamoDB Streams cost?
DynamoDB Streams on a single table captures changes to all entity types in one stream. If you only need to process changes for one entity type, you still pay to read the full stream. A Lambda consumer must filter out irrelevant entity types, consuming Streams read request units ($0.02 per 100,000 reads) for records it discards. Multi-table design avoids this by producing entity-specific streams.


