.png)


AI cloud bills don’t behave like your EC2 or RDS bills. A single inference endpoint can double in cost overnight with no infrastructure change. A training run can consume $30,000 and produce nothing usable if a data bug surfaces at step 80,000. GPU capacity you reserved six months ago may already be the wrong hardware for the model you are running today.
FinOps for AI is the practice that closes this gap. It applies financial accountability to GPU compute, token-based APIs, model training, and inference infrastructure, using cost frameworks and KPIs that were built for how AI spend actually behaves, not how traditional cloud spend behaves.
This guide covers the full practitioner playbook: what FinOps for AI is, why traditional FinOps breaks on AI workloads, the KPIs that matter, the GPU commitment strategy most teams get wrong, and how to build the practice from scratch in 60-90 days.
What Is FinOps for AI?
FinOps for AI is the discipline of applying cloud financial management: visibility, accountability, and optimization, specifically to AI and machine learning workloads. It introduces AI-native metrics (cost per token, cost per inference, GPU utilization rate) and governance frameworks designed for probabilistic, GPU-bound, token-priced cost behavior that traditional FinOps tools and processes cannot handle.
Defined by the FinOps Foundation, it adapts the standard Inform-Optimize-Operate lifecycle to the specific cost drivers of AI: GPU hardware scarcity, token-based billing, model training economics, and inference infrastructure that scales with user adoption rather than provisioning decisions.
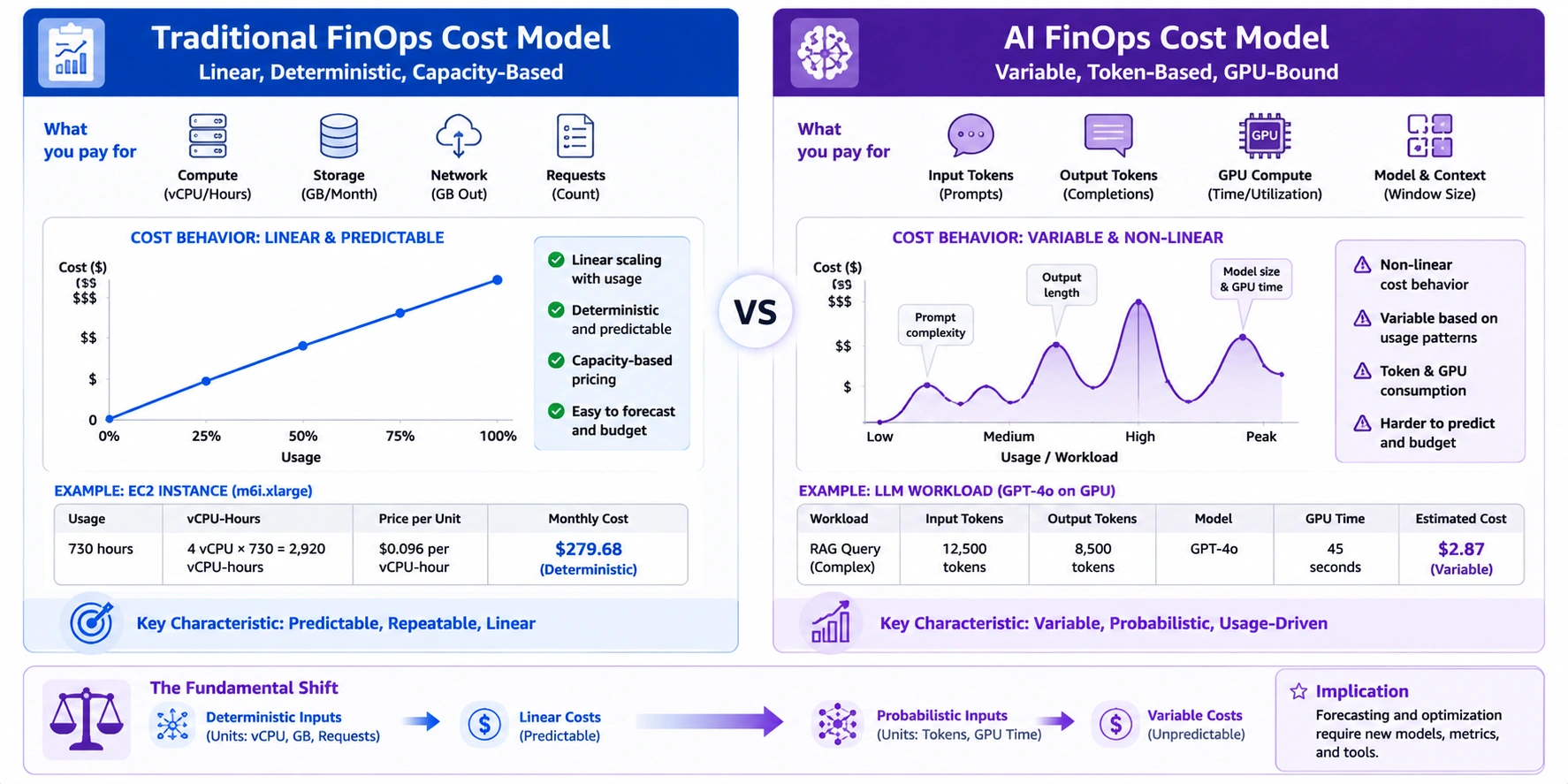
Traditional cloud FinOps tracks predictable, deterministic costs. You provision a VM, pay for it by the hour, right-size it, reserve it. The cost model is linear and bounded. AI workloads break every assumption that model relies on.
A single GPT-4 API call can cost $0.03 or $0.45 depending on prompt length and output tokens. A training run can consume $50,000 in GPU hours and produce nothing usable if a bug surfaces at step 90,000. A 64-GPU inference cluster running production traffic can hit $50,000 per month — with no native cost-per-feature attribution to explain the bill.
FinOps for AI is the discipline that applies the core FinOps principles (visibility, accountability, optimization) to these workloads, with frameworks and KPIs purpose-built for GPU scarcity, token pricing, and probabilistic cost behavior.
The FinOps Foundation defines FinOps for AI as a practice that adapts the standard Inform-Optimize-Operate lifecycle to handle new cost drivers: GPU hardware constraints, token-based billing, model training economics, and inference infrastructure scaling.
FinOps for AI vs. AI for FinOps: What Is the Difference?
These two terms are often conflated. They describe opposite directions of the same relationship.
FinOps for AI means applying financial governance to AI workloads. Your organization is building or running AI and you need to track, attribute, forecast, and optimize what that costs. This is the focus of this guide.
AI for FinOps means using AI tools to improve traditional cloud cost management. This includes anomaly detection models that flag unusual spend, LLM-powered cost dashboards that answer natural language queries, and agentic workflows that automate RI/SP purchasing recommendations.
Both matter. But the organizational challenge in 2026 is primarily FinOps for AI, teams are deploying AI at scale without the cost governance infrastructure to match.
Why AI Costs Break Traditional Cloud Financial Management
The cost is probabilistic, not allocated
Standard cloud costs map to discrete, allocated resources. You pay for 8 vCPUs and 32GB RAM. You can predict the monthly bill from first principles.
AI costs do not behave this way. API billing ties to token counts that vary per request, prompt engineering choices, model selection, and whether prompt caching is active. Two identical user-facing actions can produce wildly different costs depending on context window state. Traditional cost forecasting models built around resource allocation do not generalize to token consumption.
Also read: What is Cloud Cost Management? A Comprehensive Guide
GPU scarcity forces premature commitment
High-performance NVIDIA H100 and A100 instances remain supply-constrained across all major cloud providers. Teams running serious training workloads often must commit to GPU capacity weeks or months in advance, before their usage patterns are stable enough to inform a rational commitment decision. This creates the opposite of the standard FinOps workflow, where you observe usage before committing.
Training runs create binary cost outcomes
A failed training run consumes the same compute as a successful one. Infrastructure-level cost attribution cannot distinguish a $30,000 training run that produced a deployable model from one that failed at 80% completion due to a data pipeline error. Traditional FinOps KPIs that measure waste against provisioned capacity miss this entirely.
Inference cost compounds indefinitely
Training is a one-time cost. Inference is permanent. Once a model ships to production, its serving cost accumulates every hour, every day, without a natural endpoint. A 70B parameter model serving 1,000 daily users at 1,000 requests each generates millions of token operations per day. That cost scales with adoption, not with your infrastructure refresh cycle.
Industry analysis published in 2026 estimates that 55-80% of enterprise AI GPU spend now goes to inference rather than training, reversing the ratio from 2022-2023. Inference is where most organizations will find their largest optimization opportunity.
The FinOps for AI Framework: Inform, Optimize, Operate
The FinOps Foundation structures AI cost governance around the same three-phase lifecycle used in traditional FinOps, with AI-specific actions at each stage.
Phase 1 — Inform: Visibility and Metrics
You cannot optimize what you cannot measure. The Inform phase for AI requires building visibility infrastructure that most organizations do not have on day one.
- Tag every AI resource at submission time. Every training job, inference endpoint, prompt pipeline, and data ingestion bucket needs three tags minimum: model name, use-case ID, and team or cost center. Tags applied retroactively are incomplete. The tagging rule must be enforced at resource creation, not after the fact.
- Measure token economics, not just GPU hours. GPU-hour spend tells you how much you paid for capacity. Token-per-hour throughput tells you how efficiently you used it. The gap between those two numbers is your optimization target.
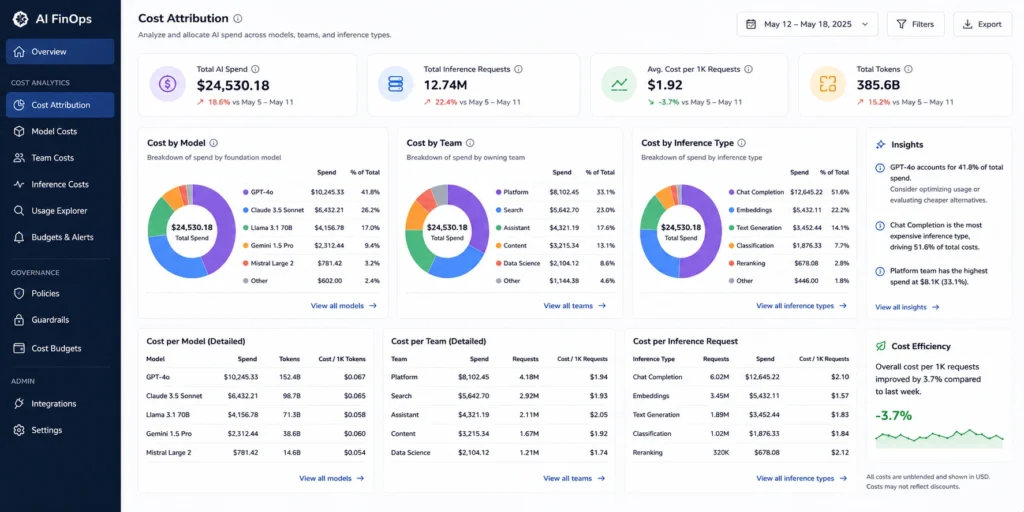
- Build unit economics from the start. Map costs to business outcomes rather than infrastructure categories. The question is not “what did we spend on p4d.24xlarge instances last month?” The question is “what did each inference request cost, and what revenue or user action did it support?”
- Implement budget alerts at 80%, not 100%. By the time you hit 100% of a monthly AI budget, corrective action takes days to weeks to propagate through model routing and caching layers. An 80% trigger gives you operational runway.
Phase 2 — Optimize: Architecture and Purchasing
- Route by model size, not default. Running a 70B parameter model to handle a simple classification task that a 7B model could answer correctly is a direct and measurable cost overhead. Implement request routing that matches query complexity to the smallest model that meets your quality threshold. This is the highest-leverage optimization most teams have not systematically implemented.
- Implement prompt caching. Major cloud providers now offer prompt caching for repeated prefixes in inference workloads. For workloads with shared system prompts or high semantic overlap between requests, prompt caching can reduce inference cost by 40-80% on the cached portion. AWS, GCP, and Azure each implement this differently — verify current rates and caching mechanics at their respective pricing pages before modeling savings.
- Use spot/preemptible instances for training, reserved for inference. Training workloads are interruptible if checkpointing is configured correctly. Spot instances on AWS GPU families (G5, P4d, P5) typically save 50-70% compared to on-demand rates (verify at aws.amazon.com/ec2/pricing — rates change). Inference workloads require consistent latency and should use reserved capacity where usage is predictable and stable enough to commit.
- Commit to GPU compute only after usage stabilizes. The mistake teams make is committing to GPU Reserved Instances or Savings Plans during the experimental phase, when usage patterns are still too volatile to inform a rational commitment. Wait for 60-90 days of stable production usage data before applying commitment discounts to AI infrastructure.
- Quantize where quality permits. Moving from FP32 to FP16 or INT8 inference reduces memory footprint and increases throughput on a fixed GPU footprint. For many production inference workloads, quality degradation is below human-detectable thresholds. Quantization is not a quality tradeoff, it is an infrastructure efficiency decision that should be evaluated empirically per model and use case.
Phase 3 — Operate: Governance and Collaboration
- Form a cross-functional AI cost council. Effective AI cost governance requires data science, MLOps, platform engineering, and finance in the same room. Each function sees a different part of the cost picture. Data science controls model selection and prompt design — two of the highest-leverage cost variables. Finance controls budget allocation and chargeback. Platform engineering controls infrastructure provisioning. Without structured collaboration, each team optimizes locally and creates global inefficiency.
- Deploy API consumption quotas per team. Without quotas, a single runaway inference loop or a misconfigured batch job can exhaust a monthly budget in hours. Per-team quotas with automatic throttling at defined thresholds prevent unbounded spend from individual workloads.
- Use automated showback reports. Transparent cost attribution to individual teams and projects changes behavior more reliably than any policy document. When teams see their own cost-per-inference numbers, they self-optimize. Showback reports (showing costs without chargeback enforcement) are the appropriate starting point for organizations early in AI cost maturity.
- Establish weekly review cadence for inference, monthly for training. Inference costs move fast. A regression in prompt efficiency or a traffic spike from a viral feature can double inference spend within days. Weekly reviews catch these patterns before they compound into a quarterly budget problem.
FinOps for AI KPIs: What to Track and Why
Traditional cloud FinOps KPIs measure resource utilization against provisioned capacity. AI FinOps KPIs measure economic efficiency at the workload level.
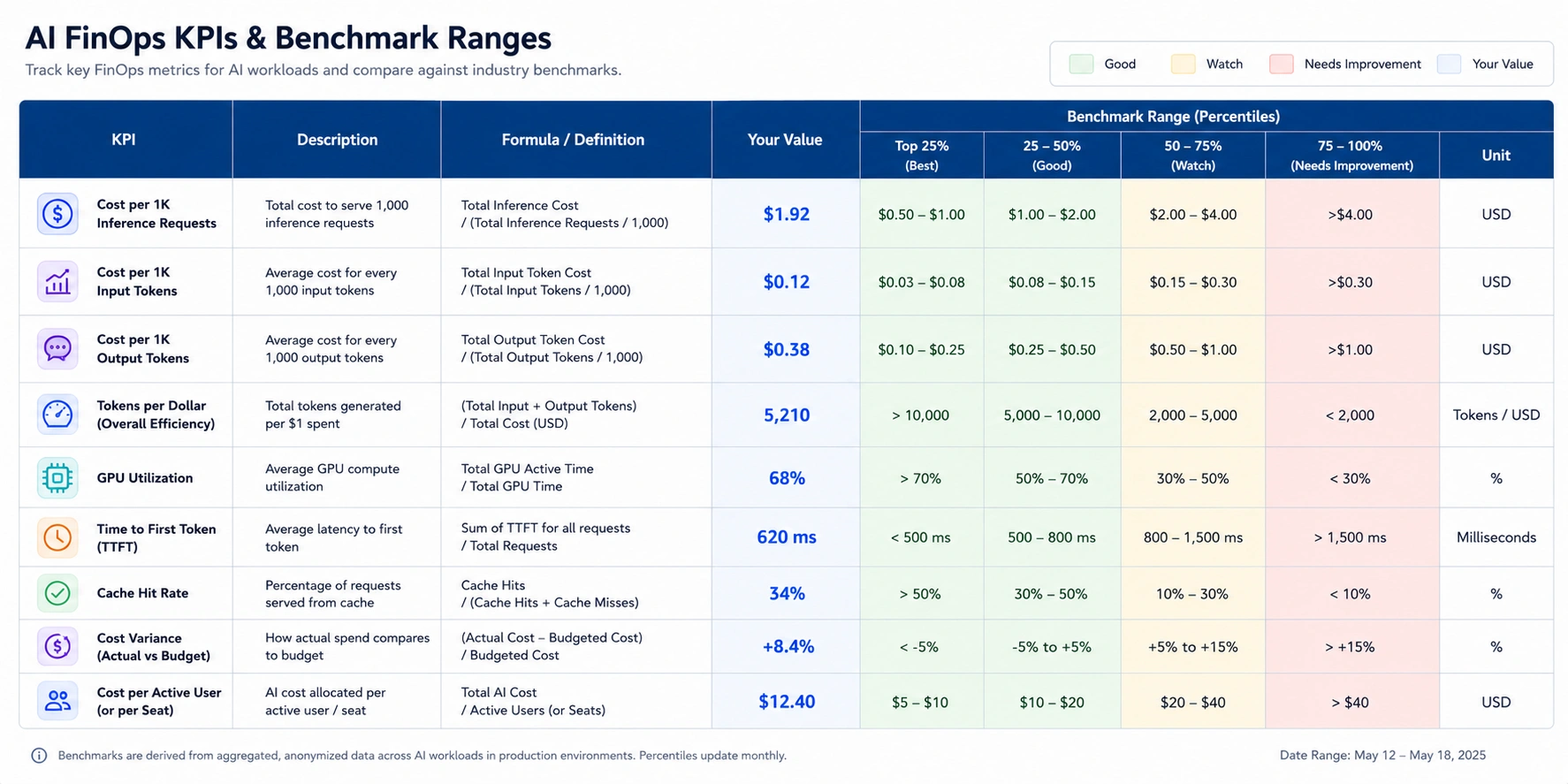
| KPI | Formula | Target | Why It Matters |
| Cost per Inference | Total inference cost / number of inference requests | Set per use case | The unit economic metric for production AI |
| Cost per 1,000 Tokens (CPT) | Total token spend / (total tokens / 1,000) | Benchmark against provider on-demand rate | Normalizes across models and providers |
| GPU Utilization Rate | GPU compute time / GPU allocated time | 70%+ for training, 50%+ for inference | Below 50% means you are paying for idle hardware |
| Cost per Training Run | Total compute cost for one training iteration | Set per model type | Tracks training efficiency improvement over time |
| Commitment Coverage Rate | GPU hours on reserved/committed capacity / total GPU hours | 60-80% for stable workloads | Low coverage means on-demand premium on stable spend |
| Inference Latency per $ | P95 latency / cost per request | Set per user experience requirement | Balances cost against user-facing quality |
| Budget Alert Response Time | Time from 80% budget trigger to corrective action | Under 48 hours | Prevents end-of-month overage surprises |
The FinOps Foundation’s official guidance on AI cost forecasting identifies GPU utilization under 100% as a primary waste signal, alongside cost per 100K tokens as the core unit economics metric for API-based AI spend. (Source: finops.org/wg/how-to-forecast-ai-services-costs-in-cloud — verify for current guidance as the working group updates regularly.)
FinOps for AI Maturity Model
Organizations do not implement AI cost governance all at once. The FinOps Foundation outlines a three-stage maturity progression. Here is how it maps to AI-specific capabilities.
| Maturity Stage | Operational Focus | AI-Specific Actions |
| Crawl | Baseline cost visibility | Manual API endpoint tracking, basic spike alerts, cost awareness training for ML teams |
| Walk | Architecture and guardrails | Prompt caching implementation, multi-model routing evaluation, per-team API quotas, automated tagging |
| Run | Continuous automation | Agentic cost routing, automated commitment purchasing for stable GPU workloads, real-time cost-per-inference dashboards |
Most organizations with active AI deployments sit somewhere between Crawl and Walk in 2026. The jump from Walk to Run requires investment in tooling and process that few teams have made at this point.
GPU Commitment Strategy for AI Workloads
The GPU commitment decision is the highest-stakes financial call in AI infrastructure management. Get it wrong and you are either overpaying for on-demand compute or locked into committed capacity that your workloads stop using.
When to reserve GPU compute
Reserved Instances and Savings Plans for GPU families offer meaningful discounts over on-demand rates. AWS P5 instances saw pricing reductions of up to 45% in June 2025; spot instances across GPU families typically save 50-70% (verify current rates at aws.amazon.com/ec2/pricing — rates change). But those discounts only deliver value if your GPU usage is predictable enough to commit to.
The test: if your GPU usage in the last 30 days shows less than 20% variance week-over-week, you have a stable enough baseline to evaluate commitment discounts. If variance is higher, the commitment risk outweighs the discount.
Also read: How to Save on RDS Reserved Instances: A Quick Guide
Training vs. inference commitment strategy
Training workloads are bursty and project-driven. They are poor candidates for long-term reserved capacity unless you have a continuous pipeline of training runs that maintains steady GPU demand. Use spot or preemptible instances for training with checkpointing enabled.
Inference workloads for production models have much more predictable demand patterns, especially after a model has been in production for 60+ days. These are the right candidates for Reserved Instances or Savings Plans — after the usage pattern stabilizes.
The lock-in problem in GPU commitments
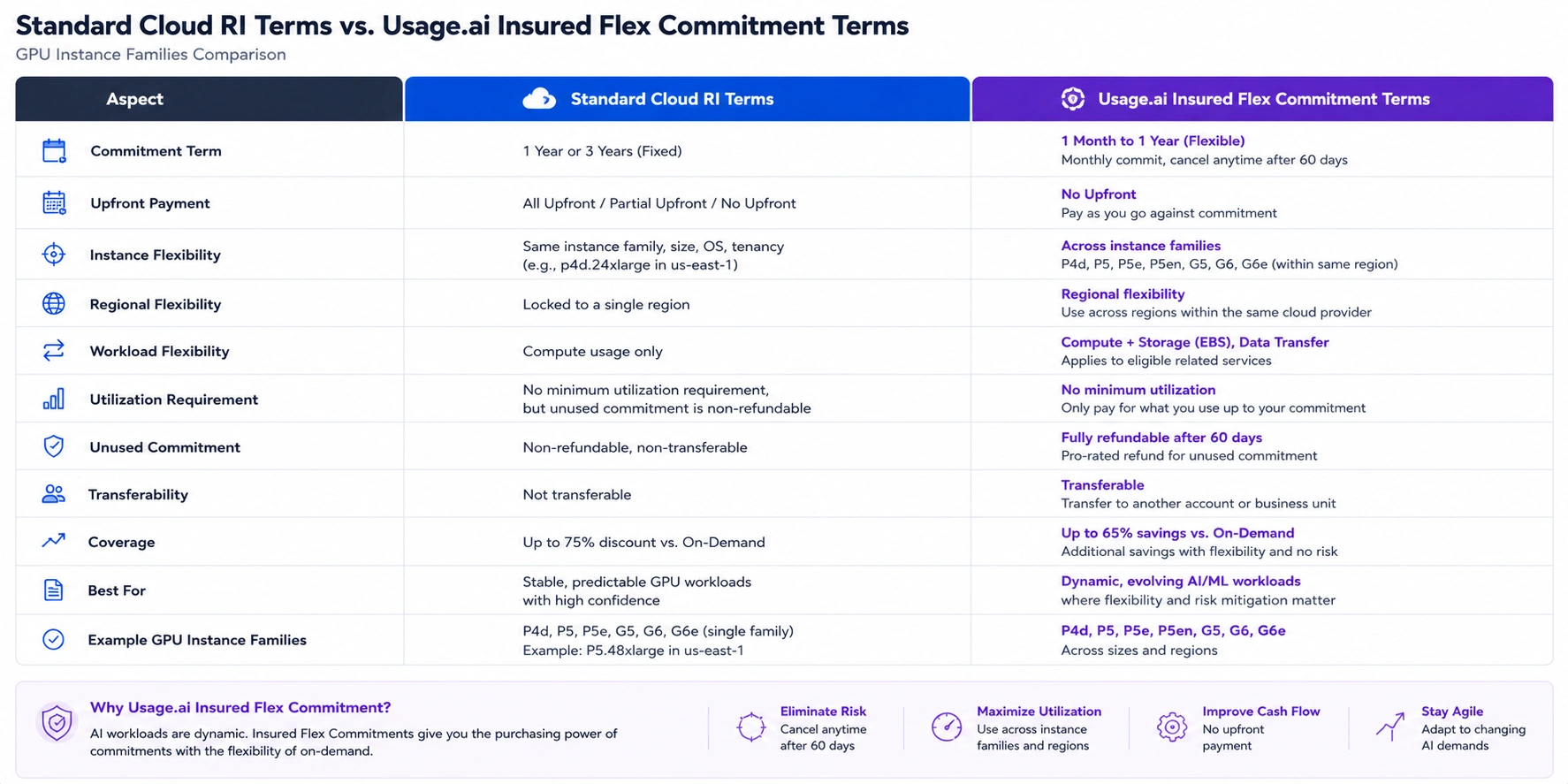
Standard cloud-native GPU reservations carry 1-3 year terms with no third-party buyback mechanism. If your model is replaced, your team downsizes, or your architecture shifts to a different instance family, you are paying for unused capacity with no exit.
This is a real financial risk for AI teams, where the model landscape and hardware optimization options change faster than in traditional infrastructure. Teams managing significant GPU committed capacity should evaluate platforms that offer flexible commitment terms with underutilization protection — the economics of a locked commitment on hardware that becomes obsolete within the term are materially different from a traditional RI on a stable compute workload.
Usage.ai’s Insured Flex Commitments apply to GPU instance families including the AWS p3, p4d, and g4dn families. Insured Flex Commitments deliver SP/RI-equivalent discounts of 30-60% without requiring multi-year lock-in or upfront payment. If usage patterns shift — a model is replaced, a team scales down, or architecture changes — commitments adjust quarterly. Underutilized portions return as cashback (real money, not credits), not forfeited spend. That distinction matters for AI teams buying GPU capacity in a market where hardware and model economics shift faster than traditional infrastructure.
Usage.ai Insured Flex Commitments carry no multi-year lock-in. Commitments adjust quarterly. Scale down? No penalty. Underutilized? Cashback paid in real money — not credits.
AI for FinOps: How AI Tools Are Changing Cloud Cost Management
The second half of the equation, i.e., using AI to manage cloud costs is evolving rapidly. This matters to FinOps practitioners because it changes what automated tooling can do.
Anomaly detection. AI models trained on historical spend patterns can identify unusual cost behavior hours or days before it would show up in a standard billing review. A 40% spike in RDS read costs triggered by an application regression that launched at 2 AM on a Tuesday gets flagged by an anomaly model before the morning standup. Rule-based alerting misses this unless someone defined the exact threshold in advance.
Natural language cost queries. LLM-powered cost dashboards allow finance and engineering teams to ask questions in plain language: “Which three services drove the most cost increase last month?” “What would our bill have been if we had reserved the top 10 instance types?” This lowers the barrier for non-technical stakeholders to engage with cost data.
Automated commitment recommendations. Recommendation engines that analyze usage patterns and suggest optimal commitment coverage are not new — AWS Cost Explorer has offered this since 2019. What has changed is the quality of those recommendations when built on top of richer models, multi-cloud data, and more frequent refresh cycles. AWS Cost Explorer refreshes recommendations every 72+ hours. Tools that refresh every 24 hours catch spend pattern changes 3 days earlier — at $6-12K/day in uncovered spend for a large AWS footprint, that lag compounds.
Agentic purchasing workflows. The next frontier is AI agents that do not just recommend commitments but execute them autonomously, within defined guardrails. This requires trusting automated systems with real financial decisions — a governance question as much as a technical one.
FinOps for AI: Common Mistakes and How to Avoid Them
Mistake 1: Applying traditional RI/SP purchasing logic to GPU workloads without adjusting for AI volatility.
Traditional compute workloads have 3-5 year lifecycles. GPU hardware and model architectures evolve on 12-18 month cycles. A 3-year GPU commitment made on 2024 hardware against 2024 model architectures may be significantly suboptimal by 2026. Shorten commitment terms or use flexible commitment structures for AI infrastructure.
Mistake 2: Measuring GPU cost without measuring GPU utilization.
A team reporting $200K/month in GPU spend has given you no information about whether that spend is efficient. GPU utilization below 50% on inference infrastructure means you could deliver the same throughput with half the fleet. Always pair cost numbers with utilization rates.
Mistake 3: Skipping tagging until after the bill arrives.
Retroactive tagging of AI resources is expensive and incomplete. Large training jobs create dozens of ephemeral child resources, none of which inherit tags automatically unless the tagging policy is applied at job submission. Build tagging into your ML pipeline tooling, not as a post-billing cleanup task.
Mistake 4: Over-reserving training infrastructure.
Training workloads are bursty. A team that runs one major training cycle per quarter does not need reserved GPU capacity year-round. Reserve for inference; use spot or on-demand for training.
Mistake 5: No showback for AI teams.
Engineering teams that do not see their AI cost-per-inference metrics have no feedback loop for prompt engineering decisions, model selection, or batching strategy. Showback reports change behavior. Silence does not.
How to Build a FinOps for AI Practice: Where to Start
If your organization is running AI workloads without structured cost governance, the following sequence is where to begin.
Week 1-2: Establish tagging.
Audit every active AI workload. Define a mandatory tagging schema: model name, team, use-case, environment. Apply it going forward via infrastructure-as-code or ML pipeline tooling. Do not try to back-fill historical resources — start clean from a known date.
Week 3-4: Build your baseline KPIs.
Calculate cost per inference (or cost per 1,000 tokens for API-based workloads), GPU utilization rate, and current commitment coverage rate. Even rough numbers from a single export of your cloud billing data are more useful than no baseline.
Week 5-6: Implement budget alerts.
Set alerts at 80% of monthly AI budget across each team. Route them to both the engineering lead and the finance stakeholder. The goal is response time under 48 hours from trigger to corrective action.
Also read: Reduce AWS Costs: 9 Proven Strategies That Actually Move the Needle
Month 2: Evaluate prompt caching and model routing.
Review your top 10 inference endpoints by cost. Identify which have high repetition rates (candidates for prompt caching) and which are using larger models than the task requires (candidates for routing to smaller models).
Month 3: Make your first AI commitment decision.
By month 3, if a production inference workload has shown less than 20% week-over-week variance in GPU usage for 60+ consecutive days, you have enough data to evaluate a commitment. At this point, compare standard cloud RI/SP terms against flexible alternatives and model the break-even against on-demand.
FinOps for AI Tools: What the Market Looks Like
The AI cost management tooling landscape is still forming. No vendor has a complete, purpose-built solution for FinOps for AI across all dimensions as of mid-2026. What exists falls into three categories.
- Cloud-native tooling (AWS Cost Explorer, Azure Cost Management, GCP FinOps Hub). Best for visibility and basic recommendations within a single cloud. Refresh rates are slower (72+ hours for AWS Cost Explorer), and AI-specific KPIs like cost per token are not natively surfaced. Good starting point, poor ceiling.
- Dedicated cloud cost platforms (CloudZero, Vantage, Apptio). Stronger cost attribution and unit economics capabilities, better multi-cloud support, some offer AI-specific cost allocation. Generally do not automate commitment purchasing.
- Commitment automation platforms (Usage.ai, ProsperOps, Spot by NetApp). Specialize in automated commitment purchasing — Reserved Instances, Savings Plans, Committed Use Discounts — across AWS, Azure, and GCP. The differentiators are recommendation frequency, commitment flexibility, and what happens when commitments go underutilized.
For teams managing significant GPU committed capacity on AWS, the commitment automation layer matters most. GPU Reserved Instances are expensive enough that the difference between a flexible commitment with a buyback guarantee and a standard locked 3-year RI is a material financial risk, not a marginal optimization.
Usage.ai operates across AWS, Azure, and GCP, covers GPU instance families including p3, p4d, and g4dn, and charges as a percentage of realized savings only. Zero fee if no savings are delivered. Setup takes 30 minutes with billing-layer access only — no infrastructure changes required.
See exactly what you’re overpaying in under 60 seconds. Try our Calculator for free →

Frequently Asked Questions
1. What is FinOps for AI?
FinOps for AI is the application of cloud financial management principles to AI and machine learning workloads. It covers GPU compute costs, token-based API billing, model training economics, and inference infrastructure. The core difference from traditional FinOps is that AI costs are probabilistic, they vary by prompt length, model selection, and context state requiring AI-specific KPIs like cost per token, GPU utilization rate, and cost per inference rather than standard resource allocation metrics.
2. What KPIs should I track for AI workloads?
The four most important KPIs are: (1) Cost per inference — total inference cost divided by number of requests; (2) Cost per 1,000 tokens — normalizes spend across models and providers; (3) GPU utilization rate — targets of 70%+ for training, 50%+ for inference; and (4) Commitment coverage rate — the share of GPU hours on reserved capacity versus on-demand. All four numbers together give you the picture traditional cloud dashboards do not surface.
3. How is FinOps for AI different from traditional cloud FinOps?
Traditional cloud FinOps manages deterministic, allocated resources (VMs, storage, databases) with predictable hourly rates. AI FinOps manages probabilistic costs — token counts that vary per request, GPU scarcity that forces premature commitment decisions, and training runs that can fail with no recoverable asset. The metrics, governance frameworks, and commitment strategies are different at every layer.
4. Should I use Reserved Instances or Savings Plans for GPU compute?
Only after your GPU usage has been in production for 60-90 days with less than 20% week-over-week variance. Training workloads are too bursty for long-term reservation; use spot instances with checkpointing. Inference workloads with stable demand are good commitment candidates. Be aware that standard 1-3 year GPU commitments carry significant lock-in risk given the rate at which model architectures and hardware generations are changing. Flexible commitment structures with underutilization protection are materially lower-risk for AI infrastructure.
5. What happens if my committed GPU capacity goes underutilized?
With standard AWS Reserved Instances or Savings Plans, you pay regardless of utilization — there is no third-party buyback option and credits do not offset the unused commitment. Platforms like Usage.ai offer a buyback guarantee on Insured Flex Commitments — underutilized portions return as cashback (real money, not credits), and commitments adjust quarterly as usage patterns change.
6. What is the FinOps Foundation’s guidance on AI cost management?
The FinOps Foundation’s AI working group recommends tracking GPU utilization, cost per token, and commitment coverage as core KPIs. Their official guidance emphasizes that AI workloads require different cost allocation strategies than traditional cloud resources, particularly for shared GPU infrastructure. The 2026 State of FinOps report found 98% of practitioners now manage AI spend — up from 63% in 2025 and 31% in 2024. (Source: data.finops.org — verify for latest data.)
7. How do I start building a FinOps for AI practice?
Start with tagging. Define a mandatory schema (model name, team, use-case) and enforce it at resource creation through your ML pipeline tooling. Build baseline KPIs from your next billing export. Set budget alerts at 80% of monthly AI spend. Then move into optimization, prompt caching evaluation, model routing by task complexity, and commitment decisions for stable inference workloads. The crawl-walk-run sequence takes 60-90 days to reach meaningful optimization with a committed team.


