.png)


GKE cost conversations usually start in the wrong place. Someone looks at the Compute Engine line in their GCP bill, notices it’s large, and starts trying to optimize VM sizes. That’s not wrong, but it’s the fourth thing to think about, not the first. The first thing is understanding the cost structure of GKE itself: the cluster management fee, the mode of operation (Autopilot vs Standard), how Committed Use Discounts now apply to Kubernetes workloads, and which workloads can run on Spot capacity.
This guide covers all four levers in the order they make the most practical impact. It also covers a commitment model change that happened in 2025 and 2026 that many teams running GKE have not yet absorbed: GKE Autopilot CUDs are no longer available for new purchases. If you are trying to buy an Autopilot CUD, you will not find that option. The correct path is Compute Flexible CUDs, which now cover Autopilot, Standard, and Compute Engine VMs under one commitment.
%2013%20(7).svg)
Lever One: The Cluster Management Fee You’re Paying Per Cluster
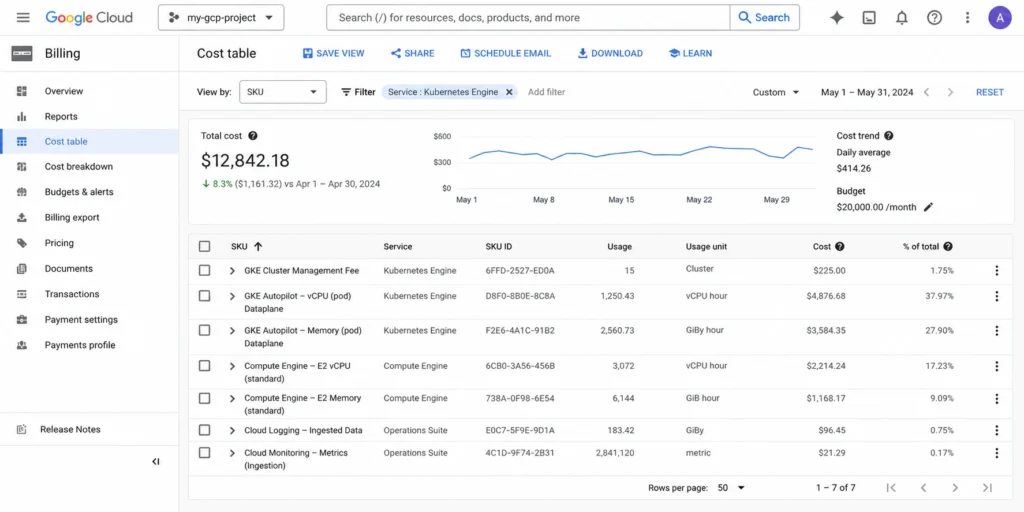
A flat cluster management fee of $0.10 per cluster per hour applies to all GKE clusters regardless of the mode of operation, cluster size, or topology. Whether it is a single-zone cluster, multi-zonal cluster, regional cluster, or Autopilot cluster, they all accrue the same flat fee per cluster. Source: cloud.google.com/kubernetes-engine/pricing DIRECT QUOTE.
$0.10 per hour sounds small. But it compounds quickly in multi-cluster architectures. Ten clusters running continuously for a month is $720 in management fees before a single pod runs. Fifty clusters — common at organizations using per-team or per-environment cluster isolation — is $3,600 per month in management fees alone.
GKE provides a free tier: $74.40 in monthly credits per billing account, which is equivalent to one free Autopilot or zonal Standard cluster per month. Free tier credits apply only to zonal and Autopilot clusters and cannot be applied to compute charges or to the cluster fee for regional clusters. Unused free tier credits are not rolled over. Source: cloud.google.com/kubernetes-engine/pricing DIRECT.
The cost implication: if you are running more than one cluster in an account, you are paying cluster management fees on every cluster beyond the first. For organizations with many small, purpose-built clusters (one per environment, one per team, one per project), the aggregate management fee is worth auditing. Consolidating workloads into fewer, larger clusters with namespace-based isolation reduces the management fee contribution to total GKE cost.
The counter-argument is blast radius: larger clusters concentrate failure risk. The right answer is specific to your architecture and risk tolerance. But knowing that each cluster adds $0.10 per hour to your bill is the prerequisite for making that trade-off consciously rather than by default.
Lever Two: How GKE Autopilot and Standard Actually Bill
Autopilot mode: billing on pod resource requests
In Autopilot mode, you are charged based on the CPU, memory, and ephemeral storage resources that your running pods request, not the capacity of the underlying nodes. You do not manage or pay for nodes directly. GKE provisions and manages the infrastructure automatically. Source: cloud.google.com/kubernetes-engine/pricing.
The billing model for Autopilot general-purpose workloads uses per-second increments with no minimum duration (beyond the cluster management fee, which runs continuously). If a pod requests 2 vCPU and 4 GB memory for 10 minutes, you pay for exactly 10 minutes of 2 vCPU + 4 GB, not for a full hour of an underlying node.
This model creates a direct financial incentive for accurate resource requests. In Standard mode, over-requesting resources wastes node capacity but the money is already spent on the node. In Autopilot mode, over-requesting CPU or memory directly inflates the bill. Setting resource requests accurately — as close as possible to what the workload actually consumes — is both a performance best practice and a cost lever in Autopilot.
Standard mode: billing on underlying Compute Engine nodes
In Standard mode, you pay for the underlying Compute Engine VM instances that make up your node pools, billed using Compute Engine pricing. You manage node configuration, upgrades, and scaling. GKE bills for the nodes until they are deleted, not just while pods are running. This means idle node capacity — nodes that are provisioned but not fully utilized by running pods — generates cost with no corresponding workload benefit.
Standard mode gives you more control over machine families, node pool configurations, and scheduling flexibility. That control comes with the operational overhead of managing node lifecycle and the financial overhead of unallocated capacity. For teams with predictable, well-understood workloads, Standard mode can deliver better cost efficiency through precise node configuration. For teams with variable or hard-to-predict workloads, Autopilot’s per-pod billing often delivers better cost behavior because you do not pay for unscheduled capacity.
Also read: GCP Committed Use Discounts: Resource-Based vs Flex CUD Strategy
Lever Three: Committed Use Discounts on GKE — What Changed
This is where most guides written before mid-2025 are now out of date, and it is worth being direct about what changed.
Autopilot CUDs are discontinued for new purchases
GKE Autopilot committed use discounts are no longer available for purchase. This is a current, active policy from Google. If you want to purchase new commitments to cover your Autopilot usage, you must purchase Compute Flexible CUDs instead. Google Cloud will continue to support existing, active Autopilot commitments until the end of their term. Source: docs.cloud.google.com/kubernetes-engine/cud DIRECT QUOTE.
This matters because many organizations running Autopilot clusters assumed they would renew or extend Autopilot-specific CUDs. The path forward is Compute Flexible CUDs, which cover the same usage and more.
Compute Flexible CUDs now cover all of GKE
Compute Flexible CUDs are spend-based commitments that cover eligible Compute Engine, GKE Autopilot, and Cloud Run usage under a single commitment. When you purchase a Compute Flex CUD, you commit to a minimum hourly spend amount for a 1-year or 3-year term. In exchange, Google applies the CUD discount rate across all covered services.
The discounts: 28% for a 1-year Compute Flex CUD, 46% for a 3-year commitment. Source: docs.cloud.google.com/kubernetes-engine/cud.
The practical advantage for GKE teams: if your workloads shift between Compute Engine VMs, GKE Standard node pools, GKE Autopilot pods, and Cloud Run — which is a normal pattern in organizations modernizing their infrastructure — a Compute Flex CUD covers the spend wherever it lands. A resource-based CUD committed to a specific VM family strands when workloads migrate to Autopilot. A Flex CUD follows the spend. This is why Usage.ai recommends Flex CUDs as the default commitment vehicle for most GCP customers running a mix of compute services.
Google applies commitments in a specific order: resource-based CUDs are applied first against eligible Compute Engine usage, then Compute Flexible CUDs cover any remaining eligible usage. Usage overages beyond the committed spend amount run at on-demand rates. Source: docs.cloud.google.com/kubernetes-engine/cud.
Resource-based CUDs still apply to Standard node pools
For GKE Standard clusters where you control the VM configuration, resource-based Compute Engine CUDs still apply to the underlying Compute Engine instances used as nodes. If you have a stable Standard cluster running specific machine families (for example, n2-standard-8 nodes consistently for a long-running data processing cluster), resource-based CUDs deliver slightly higher per-unit discounts than Flex CUDs on that specific usage.
The right combination is resource-based CUDs on stable, fixed-configuration Standard node pools and Flex CUDs to cover the remainder, including Autopilot workloads and any variable or migrating Compute Engine usage.
One important commitment billing nuance from Google’s documentation: when you purchase commitments, you pay the same commitment fee for the entirety of the commitment term, even if the price of applicable usage changes. You still receive the same discount percentage on applicable usage in the event of a price change. This means your Flex CUD discount holds steady through GCP price changes — beneficial if prices increase, less advantageous if Google reduces standard rates.
Lever Four: Spot VMs and Spot Pods
Spot VMs provide discounts of 60-91% off the corresponding regular price for CPU, memory, and GPU in GKE. The discount is dynamic and can change up to once every 30 days. Source: cloud.google.com/kubernetes-engine/pricing DIRECT QUOTE.
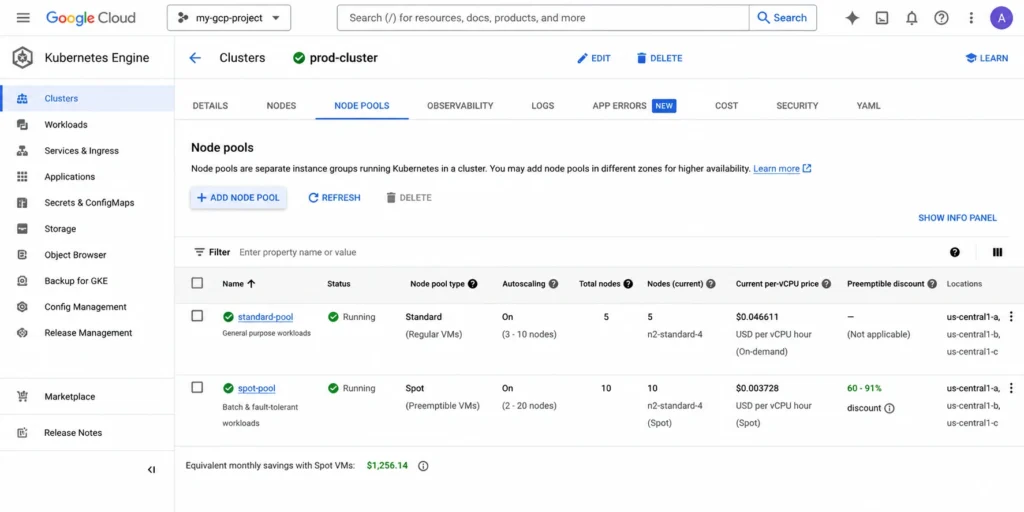
In Standard mode, you create node pools using Spot VMs. These node pools are appropriate for fault-tolerant, interruption-safe workloads: batch jobs, ML training runs, data processing pipelines, CI/CD workers. When Google needs the capacity, Spot VMs are terminated with a brief notice window, so any workload running on Spot nodes needs to handle interruption gracefully — either by checkpointing, retrying, or simply being stateless.
In Autopilot mode, the equivalent capability is Spot Pods. In Autopilot clusters, when you request Spot Pods using the cloud.google.com/gke-spot=true node selector, Autopilot automatically provisions Spot VMs, adds taints and tolerations, and manages autoscaling and scheduling. Spot Pods are priced lower than standard Autopilot pods. GKE automatically taints nodes that run Spot Pods so that standard pods are not scheduled onto them. Source: docs.cloud.google.com/kubernetes-engine/docs/how-to/autopilot-spot-pods DIRECT.
What works well on Spot
Batch processing and ETL pipelines are the clearest use case. A nightly data processing job that can be retried if interrupted, runs for 2-3 hours, and has no user-visible latency requirement is an ideal Spot candidate. The 60-91% discount against a workload that runs 2 hours a night yields meaningful savings with very low operational risk.
CI/CD build workers are another clean match. Most build jobs are inherently stateless — if a build fails mid-run due to interruption, it gets retried. Running build infrastructure on Spot nodes can dramatically reduce the cost of a large CI/CD pipeline without impacting developer velocity.
ML training jobs fit Spot well when training frameworks support checkpoint and resume. Most modern ML frameworks (TensorFlow, PyTorch, JAX) write model checkpoints periodically. A training job that checkpoints every 10 minutes loses at most 10 minutes of work on a Spot interruption.
What does not work well on Spot
Stateful workloads with persistent local state that is not externalalized to persistent storage. User-facing services with latency SLAs that cannot absorb the disruption of a pod being evicted and rescheduled mid-request. Any workload where the operational cost of handling interruptions — designing for it, testing it, managing incidents — exceeds the compute savings. Spot is not universally right. It is right for the fraction of your workload that can genuinely tolerate interruption.
Lever Five: Pod Rightsizing and Request Accuracy
This lever operates differently depending on your cluster mode. In Autopilot, pod resource requests directly determine your bill — an over-requested pod costs more than a right-sized one. In Standard, pod resource requests determine how much node capacity is consumed and therefore how efficiently your nodes are utilized.
Why resource requests matter more than most teams realize
The default behavior in Kubernetes is that a pod without explicit resource requests can be scheduled anywhere and consume as much CPU and memory as available on a node. That flexibility sounds useful but creates two problems: the scheduler cannot make informed placement decisions, and you have no signal for whether your cluster is over or under provisioned.
Setting resource requests accurately means: the scheduler can pack pods onto nodes efficiently (maximizing node utilization in Standard mode), Autopilot can bill correctly (you pay for what you request, not a platform-wide default), and the Horizontal Pod Autoscaler can make meaningful scaling decisions based on CPU or memory utilization relative to requests.
Autopilot sets defaults when requests are missing
For Autopilot mode specifically: Autopilot sets a default value if no resource request is defined in the pod spec. Autopilot also increases values that do not meet the required minimums or CPU-to-memory ratios. This means that even if you omit resource requests intending to minimize cost, Autopilot applies a minimum allocation. The practical advice: always define resource requests in Autopilot, because the defaults Autopilot applies may be higher than what your workload actually needs.
GKE cost allocation for visibility
GKE cost allocation surfaces cluster-level cost data in your GCP billing export to BigQuery, broken down by namespace and workload. When enabled, the cluster name and namespace appear in the billing export. This makes it possible to answer ‘which team or application is driving our GKE costs’ from the billing data rather than having to instrument it manually. Source: cloud.google.com/kubernetes-engine/docs/how-to/cost-allocations.
One nuance: when using CUDs with discount sharing enabled, costs for instances covered by CUDs may not be fully broken down and may appear under a goog-k8s-unsupported-sku namespace. This is a known behavior noted in Google’s cost allocation documentation. Enabling GKE cost allocation is still worthwhile for workload-level visibility even if the CUD attribution is imperfect.
Also read: GCP CUD Types Compared: Resource-Based vs. Flex
Putting It Together: A Practical GKE Cost Governance Posture
For most teams running GKE at meaningful scale, the practical posture is:
- Audit cluster count and consolidate where blast radius risk allows. Each cluster costs $0.10/hour. Ten clusters versus five is $360/month difference before any compute.
- Use Autopilot for variable, hard-to-predict workloads where per-pod billing incentivizes accurate requests and avoids idle node cost.
- Use Standard for workloads with well-understood, stable machine family requirements where resource-based CUDs on specific VM types deliver the highest per-unit discount.
- Purchase Compute Flexible CUDs (not Autopilot CUDs, which are no longer available) to cover the stable floor of Autopilot and mixed compute spend. 28% for 1-year, 46% for 3-year.
- Layer Spot node pools or Spot Pods for batch, CI/CD, and training workloads that tolerate interruption. The 60-91% discount on those workloads significantly reduces the overall cluster bill.
- Enable GKE cost allocation to BigQuery export for workload-level cost visibility. Without it, optimization work is directional at best.
The FinOps Foundation’s cloud cost management framework describes the Operate phase as continuous execution of optimization decisions — not a quarterly review. For GKE, that means CUD utilization monitoring, Spot node availability checks, and pod rightsizing as ongoing processes, not one-time projects.
How Usage.ai Fits Into GKE Cost Management
Usage.ai handles the Compute Flexible CUD layer for GCP customers: analyzing actual Autopilot and Standard cluster spend, sizing Flex CUD commitments to the stable floor of eligible usage, purchasing commitments automatically on a 24-hour cycle, and monitoring utilization throughout the term.
The buyback guarantee matters here specifically because GKE workloads change faster than most compute workloads. A team migrating from Standard to Autopilot, or from GKE to Cloud Run, creates committed spend on a service mix that no longer reflects the architecture. Usage.ai’s buyback guarantee means that if a Flex CUD commitment becomes underutilized because of a workload migration, the unused portion returns as cashback in real money rather than sunk cost. That changes the commitment sizing calculus from conservative to accurate.
Usage.ai covers Compute Engine, GKE Autopilot, GKE Standard, and Cloud Run under the same Flex CUD commitment model. Fee is a percentage of realized savings only. No savings, no fee.
%2025.svg)
Frequently Asked Questions
1. How does GKE charge for Autopilot clusters?
GKE Autopilot charges based on the CPU, memory, and ephemeral storage resources that your running pods request, in per-second increments with no minimum duration. The cluster management fee of $0.10 per cluster per hour applies continuously regardless of pod activity. For Spot Pods in Autopilot clusters, pricing is lower than standard Autopilot pods. GKE sets default resource values if none are defined in the pod spec, and increases values that do not meet minimum requirements. Source: cloud.google.com/kubernetes-engine/pricing.
2. Can I still buy GKE Autopilot CUDs?
No. GKE Autopilot committed use discounts are no longer available for purchase. If you want new commitments to cover your Autopilot usage, you must purchase Compute Flexible CUDs. Google will continue supporting existing active Autopilot CUDs until their terms expire. Compute Flexible CUDs cover GKE Autopilot, GKE Standard, Compute Engine VMs, and Cloud Run under a single spend-based commitment. Source: docs.cloud.google.com/kubernetes-engine/cud DIRECT.
3. What discount do Compute Flexible CUDs give for GKE?
Compute Flexible CUDs provide a 28% discount on a 1-year term and a 46% discount on a 3-year term, applied to eligible hourly spend on covered services including GKE Autopilot and Standard workloads. Any usage beyond the committed spend amount runs at on-demand rates. Source: docs.cloud.google.com/kubernetes-engine/cud.
4. How much can Spot VMs save on GKE?
Spot VMs provide discounts of 60-91% off the corresponding regular price for CPU, memory, and GPU in GKE. The discount rate is dynamic and can change up to once every 30 days. Spot VMs are appropriate for fault-tolerant, interruption-safe workloads. In Autopilot clusters, the equivalent is Spot Pods. Spot Pods are excluded from the Autopilot SLA. Source: cloud.google.com/kubernetes-engine/pricing DIRECT.
5. What is the GKE cluster management fee?
A flat fee of $0.10 per cluster per hour applies to every GKE cluster regardless of mode, size, or topology. GKE provides a free tier of $74.40 in monthly credits per billing account, equivalent to one free zonal or Autopilot cluster per month. Free tier credits do not apply to regional cluster management fees or to compute charges. Unused free tier credits do not roll over. Source: cloud.google.com/kubernetes-engine/pricing DIRECT.


