.png)


Google Cloud’s discount model is the most structurally complex of the three major clouds. AWS Savings Plans and Azure Savings Plans both work on a simple $/hr spend commitment.
GCP offers two fundamentally different CUD types with different eligibility rules, different discount depths, and different risk profiles — plus Sustained Use Discounts that layer on top for eligible machine families. Two significant program changes in 2025-2026 have changed how teams should model and purchase GCP commitments. This guide covers all of it with exact numbers.
See exactly what your GCP CUD coverage gap costs you in under 60 seconds. Try the Calculator for free →
The Two CUD Types: Rates, Rules, and Eligibility
The choice between resource-based and Flex CUDs is not a preference — it is a structural decision that depends on how predictable your machine family selection is. The discount gap between them compounds at scale.
| Factor | Resource-Based CUD | Flex CUD | SUD (no commitment) | Use When |
| 1-year discount | 37% | 28% | Up to 30% (automatic) | Known stable family: resource CUD. Unknown: Flex. |
| 3-year discount | 55% (general purpose)70% (memory-optimized) | 46% | N/A | Maximum discount + stable family: resource CUD 3-yr. |
| Commitment unit | Specific vCPUs + GB memory, specific family + region | $/hr spend across billing account | None — automatic | |
| Family flexibility | None — N2 commit does not cover N2D, C3, or any other family | Full — follows spend across eligible families | N1, N2, N2D, C2, M1, M2 only | |
| Region flexibility | None — us-central1 commit covers us-central1 only | Full — spans regions in same billing account | Per region | |
| GKE Autopilot / Cloud Run coverage | No | Yes (as of Sept 5, 2025) | No | Serverless + containerized workloads: Flex only. |
| Scope | Project-level or billing-account level | Billing-account level (cross-project, cross-region) | Per VM, per region | |
| Risk of stranded spend | High if family changes mid-term | Low — discount follows eligible spend | Zero — no commitment | |
| T2D instance coverage | Yes | Verify — T2D excluded from some Flex CUD configurations | No SUD on T2D | For T2D: resource CUD is the safest choice. |
Sources: discount rates from GCP official documentation and Usage.ai live GCP CUD guide (usage.ai/blogs/gcp/committed-use-discounts/). Flex CUD GKE Autopilot/Cloud Run expansion from GCP official announcement (September 5, 2025). T2D Flex CUD exclusion from usage.ai live GCP CUD blog. Verify current eligibility at cloud.google.com/compute/docs/instances/committed-use-discounts-overview.
Also read: Multi-Cloud Savings Plan Strategy
The 9 Percentage Point Gap and What It Costs
The discount gap between resource-based and Flex CUDs is 9 percentage points at the 3-year mark (55% vs 46%) and 9 points at the 1-year mark (37% vs 28%). This gap compounds directly into dollar cost at scale.
Dollar impact at $100,000/month in eligible GCP compute spend, 3-year commitment:
Resource-based CUD (55% off): effective rate = 45% of on-demand = $45,000/month. Annual cost: $540,000. 3-year saving: $2,160,000.
Flex CUD (46% off): effective rate = 54% of on-demand = $54,000/month. Annual cost: $648,000. 3-year saving: $1,944,000.
The gap: $9,000/month = $108,000/year = $324,000 over the 3-year term. This is the financial cost of choosing Flex over resource-based on stable workloads where the family is known and confirmed. Source: calculation from verified discount rates.
The Flex CUD trade-off quantified: at $100K/month eligible compute, Flex CUDs cost $324,000 more than resource-based CUDs over a 3-year term in exchange for the flexibility to repurpose the commitment across machine families. For teams planning a machine family migration, the flexibility has real value. For teams running stable, unchanging N2 or C3 workloads that will not change family over 3 years, $324,000 is an expensive price for flexibility you will not use. Source: calculation from GCP official 3-year CUD rates.
Sustained Use Discounts: What They Cover in 2026 and What They Don’t
Sustained Use Discounts (SUDs) are GCP’s automatic, zero-commitment discount for Compute Engine VMs that run for a significant portion of the billing month. No purchase required — Google applies the discount automatically when eligible resources run for more than 25% of the month. At full-month utilization (100%), the SUD reaches approximately 30% off on-demand rates. Source: GCP official sustained use discounts documentation.
SUD-eligible machine families (as of June 2026)
N1, N2, N2D, C2, M1, M2. Source: GCP official sustained use discounts documentation.
Note: these are the original and second-generation GCP machine families. The oldest are now 6-8 years old.
SUD-ineligible machine families
C3, C3D, C4, C4A, C4D, N4, N4D, N4A, T2D, T2A, E2, A2, G2, H3, and all other modern machine families. Source: GCP official.
The SUD trap for infrastructure modernization teams: if your team migrates from N1 or N2 VMs to C3 or N4 for the performance and price improvements on modern families, your Sustained Use Discounts disappear entirely. A migration plan that assumes 30% SUDs on the new machine family will produce a bill 30% higher than projected from day one. The correct response: budget for resource-based or Flex CUDs on the new family before the migration completes, not as an afterthought when the first bill arrives. Source: GCP official SUD eligibility documentation.
Also read: GCP Committed Use Discounts: Complete Guide
SUD and CUD stacking
For the eligible machine families (N1, N2, N2D, C2, M1, M2), CUDs and SUDs can stack. Resources not covered by a CUD on an eligible family will receive SUD discounts on the uncovered portion. This means a team running N2 VMs where some are covered by a resource-based CUD and some are not will receive SUDs on the uncovered N2 VMs — providing partial savings even without 100% CUD coverage. Source: cloudbolt.io citing GCP official.
The 2025-2026 Program Changes That Changed Your Cost Model
Flex CUD expansion: GKE Autopilot and Cloud Run (September 5, 2025)
Google announced on September 5, 2025 that Flex CUDs were expanded to cover GKE Autopilot clusters and Cloud Run services alongside Compute Engine VMs. Prior to this change, a team running Compute Engine VMs, GKE Autopilot, and Cloud Run required separate commitment products for each. After the expansion, a single Flex CUD covers all three services simultaneously.
The practical impact: organizations with mixed compute footprints (traditional VMs + containerized workloads on GKE Autopilot + serverless on Cloud Run) can now use a single Flex CUD to cover the entire eligible compute bill. This is a significant simplification for platform teams managing multi-service GCP environments. Source: Usage.ai live GCP CUD blog and GCP official announcement (September 5, 2025).
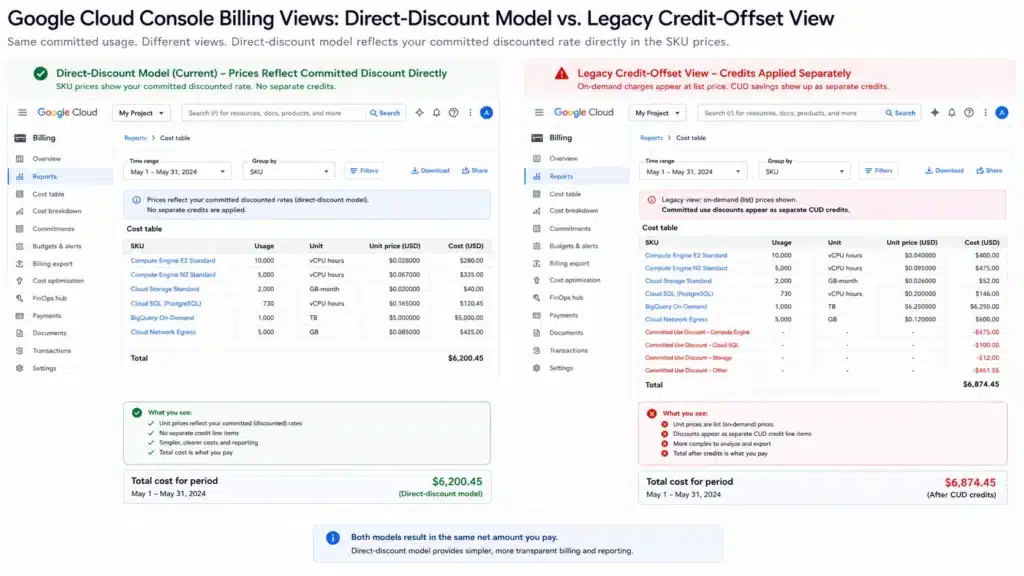
Net price billing migration: January 21, 2026
Google migrated eligible billing accounts from the legacy credit-offset CUD billing model to direct-discount (net price) billing by January 21, 2026. Under the legacy model, compute usage billed at on-demand rates with CUD savings appearing as credit line items. Under net price billing, the discounted rate appears directly as the SKU price — you see the discounted amount as the cost, not a gross cost minus a credit. Source: GCP official billing documentation.
Why this matters for FinOps reporting: any dashboard, COGS allocation model, or savings tracking built on the old credit-offset billing model now produces inconsistent data if it compares pre-migration actuals against post-migration data without normalization. Legacy billing data does not retroactively update to the new format. Teams that have not audited their billing analytics for pre/post-migration consistency risk making commitment decisions based on mismatched baselines.
Additionally: under net price billing, the commitment amount you specify is denominated in the discounted rate — not the on-demand rate the old model used as its baseline. A $70/hr commitment under the new model covers more on-demand-equivalent resources than the same $70/hr did under the old model. Teams renewing at the same historical dollar amount without adjusting for the model change will over-commit. Source: GCP official billing documentation (January 2026).
Audit action: check whether your GCP billing account migrated to net price billing. Navigate to Google Cloud Console, Billing, Billing Overview. If your account is on the new model, discounted rates appear directly in the SKU price column. If credits still appear as separate line items, your account is on the legacy model. Any commitment renewal that references historical dollar commitments across the migration boundary needs to be re-baselined. Source: GCP official billing documentation.
Resource-Based CUD Eligible Machine Families: The Complete Reference
Resource-based CUDs are available for the following GCP Compute Engine machine series as of June 2026. Source: GCP official committed use discounts documentation.
General-purpose: E2, N1, N2, N2D, N4, T2D, T2A. Compute-optimized: C2, C2D, C3, C3D, C4, C4A, C4D, H3. Memory-optimized: M1, M2, M3. Accelerator-optimized: A2, G2. Storage-optimized: Z3.
Discount by category: general-purpose and compute-optimized machines receive 37% (1-year) / 55% (3-year). Memory-optimized machines (M1, M2, M3) receive up to 70% on 3-year commitments — the deepest discount available on GCP for any machine type. For organizations running memory-intensive workloads (SAP HANA, large in-memory databases, high-memory analytics), the 70% 3-year resource CUD is the highest-yield commitment instrument on any major cloud provider. Source: GCP official CUD documentation and Usage.ai live GCP CUD guide.
Also read: GCP Committed Use Discounts: Complete Guide with Discount Tables
The Layered Commitment Strategy: How to Use Both CUD Types
The teams achieving the highest effective discount rates on GCP run both resource-based and Flex CUDs simultaneously, matched to workload stability. Neither type alone is optimal. Source: Usage.ai live GCP CUD guide.
| Layer | Instrument | Target Workloads | Discount Captured |
| 1 | Resource-based CUD (3-year) | Stable VMs that have not changed machine family or region in 12+ months. Core databases, production API servers, SAP workloads, long-running data pipelines with confirmed family. | 55% (general-purpose/compute), 70% (memory-optimized) |
| 2 | Resource-based CUD (1-year) | Workloads with stable family for the next 12 months but uncertain beyond that. Workloads recently confirmed on a new machine family after migration. | 37% (general-purpose/compute) |
| 3 | Flex CUD | Container workloads on GKE Autopilot, Cloud Run, or mixed-family compute. Cross-region traffic. Workloads undergoing machine family migration. | 28% (1-year) / 46% (3-year) |
| 4 | SUD (automatic, no purchase) | N1, N2, N2D, C2, M1, M2 VMs running continuously but not covered by CUDs. Stacks on top of CUD partial coverage on eligible families. | Up to 30% automatic (on eligible, uncovered usage) |
| 5 | On-demand | Genuine peak burst, event-driven, scheduled batch, and any workload where the duration is unpredictable. Preemptible/Spot VMs for fault-tolerant batch. | None committed — preserves elasticity |
Source: Usage.ai live GCP CUD guide and FinOps Foundation GCP commitment playbook. Discount rates from GCP official documentation.
Commitment Laddering: Staggering Expiration Dates to Avoid Cliff Risk
The single highest-risk GCP commitment mistake is purchasing one large commitment that covers 80-90% of compute at a single point in time — whether at the beginning of a year or a quarter. When all commitments expire simultaneously, the team faces a single high-stakes decision point where one misjudged purchase locks in the wrong allocation for 1-3 more years.
Commitment laddering staggers expiration dates so renewals happen continuously rather than in one batch. Instead of one annual purchase of 500 vCPUs of N2 in us-central1, a laddered approach might purchase 125 vCPUs per quarter, with four cohorts expiring quarterly throughout the year. The benefits:
No renewal cliff: commitments expire in small batches. Each expiration is a low-stakes recalibration, not a budget-cycle event.
Continuous alignment with current usage: each new purchase reflects the environment as it is now, not as it was modeled 12 months ago. Infrastructure that changed during the commitment term is handled at the next ladder rung, not retroactively.
Lower per-decision risk: a miscalculated tranche of 125 vCPUs costs a fraction of what a miscalculated annual purchase of 500 vCPUs costs.
Flexibility at each rung: each expiring tranche is an opportunity to change machine family, region, or commitment type based on current workload composition — without waiting for a full annual renewal.
Implementation: in the Google Cloud Console, navigate to Compute Engine, Committed use discounts, New commitment. Purchase at partial allocation (70-75% of your stable baseline for the first cohort). Set the remaining allocation for subsequent quarterly cohorts. Calendar the expiration dates and set a 60-day advance review cycle for each.
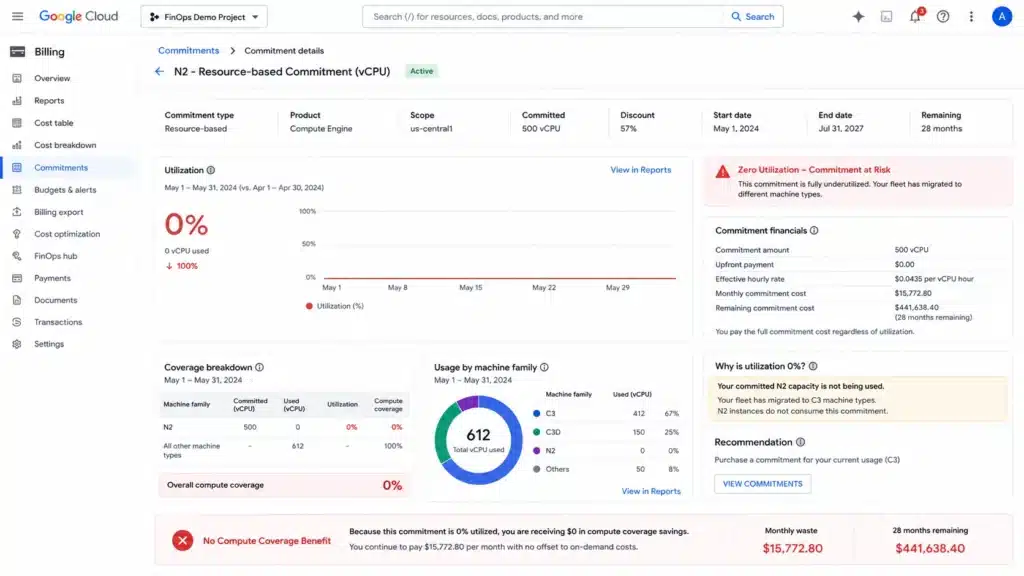
The Machine Family Migration Trap: The Commitment That Covers Nothing
The most common GCP commitment stranding scenario: a team purchases a 3-year resource-based N2 CUD in us-central1 for their production compute fleet. Six months later, engineering migrates the same workloads to C3 for performance improvements. The N2 CUD continues billing — it covers N2 usage — but there are no N2 instances running. The commitment pays for zero compute value until the 3-year term expires.
Prevention: before purchasing any resource-based CUD, confirm the machine family selection is stable for the full commitment term. Ask: Is a Graviton-equivalent migration (N2 to N4, C2 to C3) on the 12-month roadmap? Is GKE adoption increasing the fraction of containerized vs VM compute? Is a multi-cloud migration underway that will reduce GCP VM footprint?
If any of these are yes: purchase Flex CUDs for the uncertain portion and resource-based CUDs only for the confirmed-stable portion. The 9pp discount gap is real, but 0% discount on a stranded N2 CUD while paying on-demand for C3 workloads is 100% waste.
See exactly what your GCP CUD coverage gap costs you in under 60 seconds. Try the Calculator for free →
How Usage.ai Optimizes GCP Committed Use Discounts
Usage.ai supports GCP alongside AWS and Azure on a single platform. For GCP commitment management, Usage.ai covers the full CUD lifecycle:
Recommendation: Usage.ai analyzes GCP billing data and Compute Engine utilization to identify the correct split between resource-based and Flex CUD allocations. For each machine family in the fleet, the platform evaluates whether the family has been stable for 12+ months (resource-based CUD candidate) or whether family changes are on the roadmap (Flex CUD candidate). The recommendation accounts for the recent Flex CUD expansion to GKE Autopilot and Cloud Run — container and serverless spend is included in Flex CUD sizing rather than left uncovered.
Stranded commitment detection: Usage.ai identifies resource-based CUDs where utilization has dropped below 80% for more than 14 consecutive days — a signal that the underlying machine family has changed or the workload has been decommissioned. The 24-hour refresh cycle surfaces this signal before it compounds into months of unused commitment cost.
Net price billing normalization: Usage.ai’s billing analytics normalize pre- and post-migration billing data to ensure that commitment recommendations are based on consistent baselines — not a mix of credit-offset and direct-discount data that produces artificially inflated or deflated utilization signals.
Buyback guarantee: Usage.ai’s Insured Flex Commitments include a buyback guarantee on GCP CUD commitments. If a resource-based CUD becomes stranded due to a machine family migration or workload decommission, the unused commitment is bought back and the value returned as cashback in real money — the same guarantee that applies to AWS Savings Plans and RIs, now extended to GCP. This changes the commitment risk calculus: teams can commit at the correct level rather than the conservative level, because underutilization is protected rather than a permanent loss.
Fee: percentage of realized savings only. $0 if Usage.ai saves nothing. 30-minute setup, billing-layer access only, no infrastructure changes required.
See how Usage.ai manages GCP CUD coverage across your full compute fleet

Frequently Asked Questions
1. What is the difference between resource-based and Flex CUDs on GCP?
Resource-based CUDs commit to a specific quantity of vCPUs and GB memory within one machine family and one region. Discount: 37% for 1-year, 55% for 3-year (general-purpose and compute-optimized), up to 70% for 3-year (memory-optimized). Flex CUDs commit to a $/hr spend amount across any eligible machine family and any region in the same billing account. Discount: 28% for 1-year, 46% for 3-year. The 9 percentage point discount gap represents the cost of flexibility. Use resource-based for stable, family-confirmed workloads. Use Flex for dynamic, cross-family, or GKE Autopilot/Cloud Run workloads. Source: GCP official CUD documentation, verified June 2026.
2. What GCP machine families qualify for Sustained Use Discounts?
SUDs apply only to six machine series: N1, N2, N2D, C2, M1, and M2. Modern families including C3, C3D, C4, N4, T2D, T2A, E2, A2, G2, H3, and all newer series do not receive SUDs. Organizations migrating from legacy families (N1, N2) to modern families (C3, N4) must explicitly replace the SUD discount with resource-based or Flex CUDs, or the new machine family runs at full on-demand rates. Source: GCP official sustained use discounts documentation.
3. What changed with GCP Flex CUDs in 2025-2026?
Two significant changes: (1) On September 5, 2025, Google expanded Flex CUDs to cover GKE Autopilot clusters and Cloud Run services alongside Compute Engine VMs. A single Flex CUD now covers an organization’s entire eligible compute footprint across VMs, containers, and serverless. (2) By January 21, 2026, Google migrated eligible billing accounts from the legacy credit-offset CUD billing model to direct-discount (net price) billing, where discounts appear as lower SKU prices rather than as credit offsets. Source: GCP official announcements and GCP billing documentation.
4. Can you use both resource-based and Flex CUDs simultaneously?
Yes. The optimal GCP commitment strategy uses both. Resource-based CUDs on stable, family-confirmed workloads capture the deeper 55-70% discount. Flex CUDs cover dynamic, cross-family, and containerized workloads at the 28-46% range. On eligible machine families (N1, N2, N2D, C2, M1, M2), Sustained Use Discounts apply automatically to any usage not covered by CUDs, stacking additional discounts on top. Source: GCP official documentation and Usage.ai live GCP CUD guide.
5. What is the risk of a stranded GCP resource-based CUD?
A resource-based CUD is stranded when the committed machine family is no longer running — because the fleet migrated to a different family, the workload was decommissioned, or the project was shut down. A stranded CUD continues billing for the committed resource allocation with zero compute coverage benefit for the remainder of the term (up to 3 years). Prevention: purchase resource-based CUDs only for machine families confirmed stable for the full commitment term. For workloads with migration plans in the next 12-24 months, use Flex CUDs instead and accept the 9pp discount trade-off. Source: GCP official CUD documentation.