.png)


Executive Summary
May 2026 was shaped by Google I/O on May 19-20 and a stream of GCP release notes throughout the month. Three things require immediate attention:
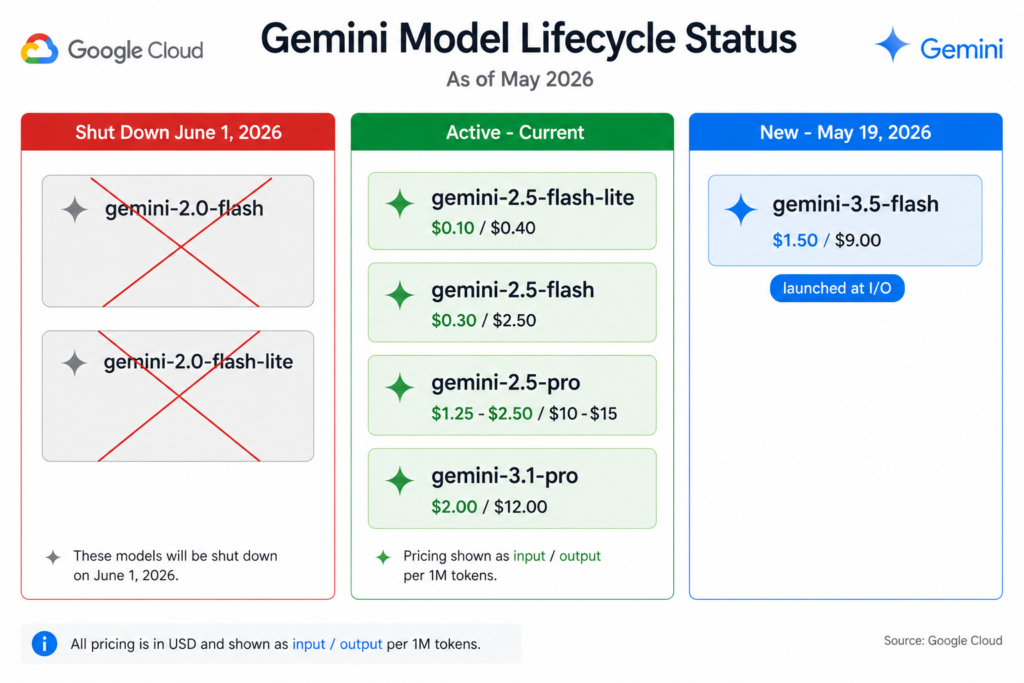
- Gemini 2.0 Flash and Gemini 2.0 Flash-Lite were deprecated February 18, 2026 and shut down on June 1, 2026. Any production workload still calling these model versions stopped working on June 1. The migration window has closed. If this affected your environment, verify and remediate now.
- Gemini 3.5 Flash launched at Google I/O on May 19, 2026 at $1.50 per million input tokens and $9.00 per million output tokens. It outperforms Gemini 3.1 Pro on coding benchmarks at approximately 25% lower cost. Teams running Gemini 3.1 Pro for code generation should benchmark 3.5 Flash before the next billing cycle.
- Knowledge Catalog data products reached general availability on May 25, 2026. Teams using Dataplex for data governance can now manage access workflows, automated documentation, and MCP server integrations for data products without preview limitations.
For FinOps teams, two additional changes matter: Committed Use Discounts now apply to Agent Platform Inference workloads when using Compute Engine reservations, and the App Engine Migration Hub entered preview offering cost-saving Cloud Run migration recommendations for App Engine standard workloads.
All pricing figures in this document require verification at cloud.google.com/pricing before acting on them. Rates change.
Google I/O 2026: May 19-20 Announcements Relevant to GCP Teams
Google I/O 2026 ran May 19-20, 2026. While the event primarily targets Android, Chrome, and web developers, several announcements are directly relevant to GCP infrastructure and AI cost management.
Gemini 3.5 Flash: New Model, New Pricing, and a Migration Deadline from 3.1 Pro
Gemini 3.5 Flash launched at Google I/O on May 19, 2026. Published pricing at launch: $1.50 per million input tokens and $9.00 per million output tokens.
The cost story: Gemini 3.5 Flash outperforms Gemini 3.1 Pro on coding benchmarks at approximately 25% lower cost. Gemini 3.1 Pro was priced at $2.00 per million input tokens and $12.00 per million output tokens. If your team uses Gemini 3.1 Pro primarily for code generation, summarization, or structured extraction, benchmark 3.5 Flash before the next billing cycle. Even a partial migration of suitable workloads delivers material savings.
Claude Opus 4.8 Now Available on the Gemini Enterprise Agent Platform
Anthropic’s Claude Opus 4.8 was confirmed available on the Gemini Enterprise Agent Platform in May 2026, as announced via the Google Cloud blog. Claude Opus 4.8 brings strong capabilities in agentic coding, including managing extensive code refactors and tracking dependencies over extended sessions.
Cost implication: Claude Opus 4.8 is a premium model tier. Teams running agentic coding workflows should compare Claude Opus 4.8 per-token costs against Gemini 3.5 Flash for the same tasks. For complex, multi-stage refactors where Gemini Flash-tier models may lose context fidelity, Opus 4.8 may justify the premium. For routine code generation and completion, Flash-tier models should be the default.
Gemini 2.0 Flash and Flash-Lite: Shutdown June 1, 2026 – Action Required
Gemini 2.0 Flash and Gemini 2.0 Flash-Lite were deprecated on February 18, 2026 and shut down on June 1, 2026. Any application calling these model versions via the Gemini API or Vertex AI stopped receiving responses on that date.
Recommended migration paths confirmed by Google:
- Gemini 2.5 Flash-Lite ($0.10 per million input / $0.40 per million output) – identical pricing to 2.0 Flash-Lite, with 8x the output token limit. This is the lowest-friction migration path for teams moving from 2.0 Flash-Lite.
- Gemini 2.5 Flash ($0.30 per million input / $2.50 per million output) – for teams that were on 2.0 Flash and need more capability. Higher cost than 2.0 Flash but stronger performance.
If your environment was affected by the June 1 shutdown, pull API error logs for calls to gemini-2.0-flash and gemini-2.0-flash-lite model strings, identify all calling applications, and update model identifiers to the 2.5 series.
Pro Models Removed from Gemini API Free Tier: April 1, 2026
As of April 1, 2026, Pro models are no longer available on the Gemini API free tier. Only Flash and Flash-Lite models retain free access with reduced quotas. Any team that was prototyping with Gemini 2.5 Pro or Gemini 3.1 Pro on the free tier must now use a paid API key. This change took effect in April but its downstream billing impact lands in May invoices for teams that onboarded in April. Review your May Google Cloud invoices for new Vertex AI Gemini API line items if your team recently enabled Pro model access.
Gemini Enterprise Agent Platform: CUDs Now Apply to Agent Inference Workloads
This is the most directly actionable FinOps-relevant GCP change of May 2026 for teams running AI agents at scale. Google confirmed that Committed Use Discounts (CUDs) apply to Agent Platform Inference workloads when using Compute Engine reservations.
How it works: when your agents run on Compute Engine reservations with the label vertex-ai-online-prediction, billing is split into two SKUs. The GCE SKU carries your CUD discount. The Agent Platform Management Fee SKU does not. The net result is that your existing Compute Engine CUDs now reduce the compute component of your agent inference costs – but do not eliminate the management fee entirely.
For teams running large agent fleets on Compute Engine-backed Agent Platform Inference, this changes the CUD sizing calculation. If you currently hold Compute Engine CUDs without accounting for agent inference workloads, you may have unused CUD capacity that should be applied. If you are planning new CUD purchases, include agent inference compute in the baseline.
For a full breakdown of how GCP Committed Use Discounts work, when to use resource-based versus spend-based CUDs, and how to layer commitments across compute and AI workloads, the Usage.ai guide on GCP Cost Optimization covers the decision framework in detail.
Data and Analytics: Airflow 3.1 GA, Knowledge Catalog GA, BigQuery ODBC Driver, and Datastream Updates
Managed Service for Apache Airflow: Airflow 3.1 Generally Available
Managed Service for Apache Airflow (Cloud Composer) launched general availability of Airflow 3.1 in May 2026 alongside a wave of new capabilities:
- Airflow 3.1 GA – the latest stable Airflow version is now available in Cloud Composer without preview limitations.
- AI-powered agentic troubleshooting – Gemini analyzes failed task logs, identifies failure patterns (resource exhaustion, timeouts, dependency failures), and provides actionable recommendations. Available directly in Cloud Composer 3, removing the need to manually sift through raw logs.
- Managed Airflow MCP Server – a new managed MCP server enables custom AI agent integration with Airflow environments, allowing agents to trigger DAGs, check run status, and interact with pipeline state through a standard MCP interface.
- Declarative YAML-based orchestration pipelines – define DAGs in YAML rather than Python for teams that prefer infrastructure-as-code style pipeline definition.
- Google Cloud tags for environments – apply and manage Cloud tags on Composer environments, enabling conditional IAM policies and cost attribution at the environment level.
Cost implication: the AI-powered troubleshooting capability routes failed task analysis through Gemini, which adds Vertex AI inference costs for each investigation triggered. In environments with high DAG failure rates, this can become a material cost line. Consider setting investigation triggers selectively for high-priority DAGs rather than enabling auto-investigation on all tasks.
Knowledge Catalog Data Products: Generally Available
Knowledge Catalog data products reached general availability on May 25, 2026. This is a significant milestone for teams using Dataplex for data governance. GA status means the feature is now production-ready and eligible for SLA coverage.
Four capabilities included at GA:
- Approval workflows for data product consumption – consumers browse published data products, submit access requests, and track status. Owners approve or reject via the Cloud Console or API.
- Automated documentation and insights – data product owners use Knowledge Catalog data insights and Gemini to automatically generate sample queries, business insights, and documentation templates.
- Service account support – data products can be configured with service accounts in access groups, allowing programmatic consumers to request service account access.
- Remote MCP server support (Preview) – AI agents and data applications can programmatically interact with data products through the Knowledge Catalog remote MCP server.
The MCP server preview is particularly relevant for teams building agentic data pipelines: agents can now discover, access, and query data products using standard MCP tooling without custom API integration.
Google-Built ODBC Driver for BigQuery: Now in Preview
Google released its own ODBC driver for BigQuery in preview in May 2026. This open-source driver provides a direct, high-performance connection for applications to BigQuery and replaces the need to use third-party ODBC drivers or Simba connectors.
Cost implication: teams currently paying for commercial Simba ODBC connector licenses can evaluate replacing them with the Google-built driver at no additional licensing cost. The driver is open-source and developed entirely in-house by Google.
Datastream: Metadata Integration with Knowledge Catalog in Preview
Datastream’s metadata integration with Knowledge Catalog entered public preview in May 2026. The integration creates a single view of all Datastream assets within Knowledge Catalog, enabling unified data discovery, lineage tracking, and governance across streaming data pipelines. Teams running Datastream for database-to-BigQuery replication or CDC pipelines can now surface their stream metadata in Knowledge Catalog without manual cataloging.
Compute and Containers: App Engine Migration Hub, GKE 1.35 Features, and Cloud Run Updates
App Engine Migration Hub: Cloud Run Migration with Cost-Saving Recommendations
The App Engine Migration Hub entered preview in May 2026, supporting App Engine standard environment Go, Java, Node.js, PHP, Python, and Ruby. It provides:
- Guided migration of App Engine standard environment services to Cloud Run with automated code transformation where possible.
- Cost-saving recommendations – the hub analyzes each App Engine service and identifies where a Cloud Run migration would reduce compute costs, particularly for services with infrequent traffic that benefit from Cloud Run scale-to-zero.
Cloud Run scales to zero when idle, meaning you pay only for actual request execution time. App Engine standard has minimum instance settings that can incur idle compute costs. For services with low or irregular traffic, migration to Cloud Run can reduce monthly compute spend by eliminating idle-time charges. The Migration Hub quantifies this saving before migration, making it actionable for FinOps planning rather than retrospective.
GKE 1.35: In-Place Pod Resize and Workload Identity Connectivity Changes
GKE version 1.35 introduced two changes that affect cost and operations:
- In-place Pod Resize (in-place vertical scaling) – change CPU and memory resource allocations for running pods without restarting them. This enables tighter right-sizing of running workloads. Previously, any resource adjustment required a pod restart, which meant teams over-provisioned to avoid restart-driven downtime. With in-place resize, right-sizing can happen continuously without service disruption.
- Workload Identity connectivity timeout – workloads using Workload Identity to authenticate to Google Cloud APIs may experience transient connectivity timeouts or refused connections to the GKE metadata server immediately following node startup on GKE 1.35. Google has published workarounds. Check the GKE release notes for the affected configuration and apply the recommended fix before upgrading production clusters to 1.35.
The in-place Pod Resize feature is the more significant cost change. For clusters running stateful workloads with predictable but variable resource consumption (ML serving, database sidecars, batch processors), continuous right-sizing without restarts means resource utilization can be maintained close to actual demand, reducing per-node waste.
GKE Gateway: Backend Authenticated TLS for Gateway-Originated Connections
GKE Gateway now supports backend authenticated TLS for Gateway-originated connections to Pods or InferencePools. This enables mTLS between the GKE Gateway and backend workloads, improving security posture for AI inference traffic that passes through the Gateway layer. No direct cost change.
Apigee: UI Updates and Model Armor Bug Fix
Two Apigee updates from the May 2026 release notes:
- Apigee UI (version 1-17-0-apigee-8, May 21, 2026) – teams can now create, view, update, and delete spaces and manage IAM policies directly in the Apigee UI. Previously, these actions required the Apigee API.
- Model Armor response parsing fix – a bug was fixed where unknown fields in Model Armor responses caused policy failures. Future Model Armor field additions will no longer break existing policies.
The Model Armor fix is relevant for teams using Apigee with AI proxy policies: policies that were intermittently failing due to Model Armor response format changes should be re-tested after the 1-17-0-apigee-8 rollout completes. Rollouts began May 21 and may take four or more business days to complete across all zones.

FinOps and Cost Management: What May 2026 Means for GCP Spend
Gemini 2.0 Shutdown: Audit Your Model Strings Now
The June 1, 2026 shutdown of Gemini 2.0 Flash and Flash-Lite is the highest-urgency item from May for GCP FinOps teams. If any production application called these model versions, it broke on June 1. But the broader FinOps point is cost modeling: the migration paths have different pricing.
Gemini 2.0 Flash was priced at $0.10 per million input tokens and $0.40 per million output tokens in most configurations. Gemini 2.5 Flash is priced at $0.30 input / $2.50 output. The migration from 2.0 Flash to 2.5 Flash increases per-token cost significantly. For high-volume workloads, model your May token consumption against both the 2.5 Flash-Lite ($0.10/$0.40 – same pricing as 2.0 Flash-Lite) and 2.5 Flash rates before defaulting to 2.5 Flash. Flash-Lite may be sufficient for most tasks at 2.0-equivalent pricing.
For teams evaluating how GCP Committed Use Discounts apply across Compute Engine and Vertex AI workloads, the Usage.ai guide on GCP Committed Use Discounts covers resource-based versus spend-based CUDs and how to layer them for AI inference workloads.
Gemini 3.5 Flash: Benchmark Before Migrating from 3.1 Pro
Gemini 3.5 Flash at $1.50/$9.00 per million tokens versus Gemini 3.1 Pro at $2.00/$12.00 per million tokens represents a 25% cost reduction on input and output tokens if quality is maintained for your workload. For teams running Gemini 3.1 Pro at high volume, the annualized savings on a $50,000/month Gemini 3.1 Pro spend would be approximately $150,000 at the same token volume.
The FinOps discipline here: do not migrate blindly based on pricing. Run a representative sample of your production prompts through both models and score outputs. For coding tasks, Google’s own benchmarks show 3.5 Flash outperforming 3.1 Pro. For complex multi-document reasoning or domain-specific professional tasks, validate independently.
Agent Platform CUDs: Update Your Commitment Baseline
Now that CUDs apply to Agent Platform Inference via Compute Engine reservations, teams with existing Compute Engine CUDs should check whether agent inference workloads are running under the vertex-ai-online-prediction label. If they are, and you hold unused CUD capacity, you may be leaving commitment discounts unused. If you are planning new CUD purchases, include agent inference compute in the hourly spend baseline before sizing the commitment.
The full breakdown of GCP compute pricing by machine family, how to read your CUD utilization report, and when to use Spot VMs versus CUDs for AI workloads is covered in the Usage.ai guide on Google Cloud Compute Pricing.
App Engine Migration Hub: Run the Cost Analysis Before Migrating
The App Engine Migration Hub provides cost-saving recommendations as part of its preview, not just migration guidance. Before migrating any App Engine service to Cloud Run, run the Hub analysis and review the projected cost reduction. The Hub quantifies the expected Cloud Run savings based on your actual App Engine traffic patterns. For services that received fewer than 100 requests per day, the scale-to-zero benefit of Cloud Run is material. For high-traffic services running at consistent load, the cost difference between App Engine and Cloud Run is smaller.


