.png)

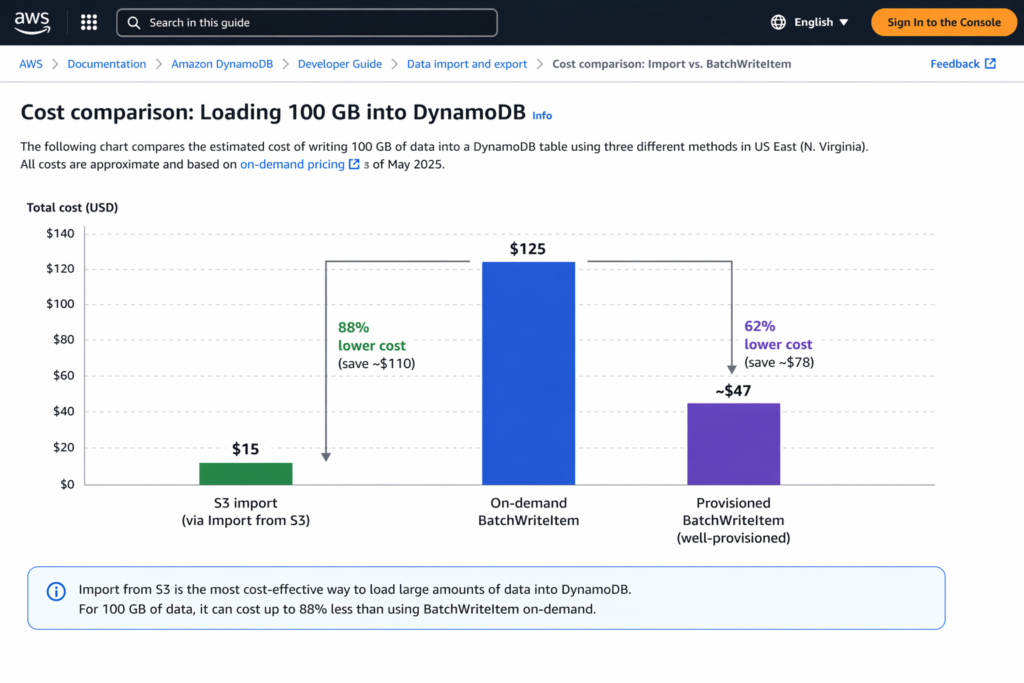
DynamoDB import from S3 costs $0.15 per GB of uncompressed source data and consumes zero write capacity units during the load. For a 100 GB dataset in US East (N. Virginia), the import fee is $15.00. Loading the same 100 GB through on-demand BatchWriteItem at $1.25 per million WRU would cost approximately $125.00 for 1 KB items, making the S3 import roughly 88% cheaper.
The AWS DynamoDB import from S3 feature supports CSV, DynamoDB JSON, and Amazon Ion formats. It creates a new table during the import process, populates any Global Secondary Indexes defined at creation time at no extra cost, and handles up to 50,000 S3 source objects per job.
How Much Does It Cost to Import Data from S3 to DynamoDB?
The pricing model for importing data from S3 to DynamoDB has three components: the DynamoDB import fee, the S3 access costs, and (optionally) cross-region data transfer. Here is the complete cost breakdown.
| Cost Component | Rate (US East) | Scope | Notes |
| DynamoDB Import Fee | $0.15/GB | Uncompressed source data size | Includes failed records |
| GSI Population | $0.00 additional | GSIs defined at table creation | No extra charge during import |
| S3 Storage | $0.023/GB-month (Standard) | Source data in S3 | Charged until you delete source files |
| S3 GET Requests | $0.0004 per 1,000 GET | DynamoDB reads from your S3 bucket | Typically negligible |
| Cross-Region Transfer (if applicable) | $0.02/GB | S3 bucket in different region from target table | Avoid by co-locating S3 and DynamoDB |
For a 100 GB import with source data in the same region: DynamoDB import fee = $15.00. S3 storage for the source files (assuming 1 month) = $2.30. S3 GET requests (negligible, under $0.10). Total: approximately $17.40. If the S3 bucket is in a different region, add $2.00 in cross-region transfer ($0.02/GB x 100 GB), bringing the total to $19.40.
How Does DynamoDB Import from S3 Compare to BatchWriteItem Costs?
The cost advantage of importing data from S3 to DynamoDB versus writing through the API depends on item size, data volume, and capacity mode. Here is a direct comparison at three data volumes.
| Data Size | S3 Import Cost | On-Demand WRU Cost | Provisioned WCU Cost* | S3 Import Savings vs On-Demand | S3 Import Savings vs Provisioned |
| 10 GB (~10M items at 1 KB) | $1.50 | $12.50 | ~$4.70 | 88% | 68% |
| 100 GB (~100M items at 1 KB) | $15.00 | $125.00 | ~$47.00 | 88% | 68% |
| 1 TB (~1B items at 1 KB) | $153.60 | $1,280.00 | ~$475.00 | 88% | 68% |
At every scale, the DynamoDB import from S3 feature is the cheapest option for bulk loading data into a new table. The 88% cost reduction versus on-demand writes holds consistently because the $0.15/GB import rate is fixed regardless of item count or throughput. For a 1 TB migration, the import saves over $1,100 compared to on-demand BatchWriteItem.
Also read: DynamoDB DAX Pricing: In-Memory Cache Cost vs Performance Gain
Can You Import from S3 to an Existing DynamoDB Table?
No. This is the most common question about this feature, and the answer is definitive: DynamoDB import from S3 to an existing table is not supported. The import process creates a brand-new table during the job. You cannot load data into a table that already exists, regardless of whether it is empty or populated.
This limitation matters for teams running production workloads who need to backfill data, restore from backup, or merge datasets into an active table. If you search for “dynamodb import from s3 to existing table,” you will find this is one of the most frequently asked questions on AWS re:Post and Stack Overflow.
Workaround: Import to a New Table and Swap
The most common workaround involves four steps: (1) Export the existing table to S3 using DynamoDB Export to S3 ($0.10/GB). (2) Merge or transform the exported data with the new data in S3 (using Athena, Glue, or a simple script). (3) Import the merged dataset from S3 to DynamoDB as a new table ($0.15/GB). (4) Update your application’s table references to point to the new table, or use DynamoDB table swap via CloudFormation/CDK.
The combined cost: $0.10/GB (export) + $0.15/GB (import) = $0.25/GB. For a 100 GB table, that is $25.00 total, still significantly cheaper than running BatchWriteItem operations at on-demand rates.
Alternative: BatchWriteItem for Existing Tables
If you need to load data into an existing table without creating a new one, BatchWriteItem is the only native option. Each BatchWriteItem call handles up to 25 items or 16 MB per request. At on-demand rates, each 1 KB write costs $1.25 per million WRU. For large backfills, use multi-threaded writers with exponential backoff to avoid throttling. If the table uses provisioned capacity, temporarily increase WCU for the backfill period and reduce it afterward.
What Are the Quotas and Limitations for AWS DynamoDB Import from S3?
AWS imposes specific quotas on the DynamoDB import from S3 feature that vary by region.
| Quota | Major Regions (us-east-1, us-west-2, eu-west-1) | All Other Regions |
| Max concurrent import jobs | 50 | 50 |
| Max total source object size (concurrent) | 15 TB | 1 TB |
| Max S3 objects per import job | 50,000 | 50,000 |
| Supported input formats | CSV, DynamoDB JSON, Amazon Ion | CSV, DynamoDB JSON, Amazon Ion |
| Compression support | GZIP, ZSTD, or None | GZIP, ZSTD, or None |
| Import target | New tables only | New tables only |
Source:
The 15 TB vs. 1 TB distinction between major and non-major regions is a planning constraint for large migrations. If your data exceeds 1 TB and your target region is outside us-east-1, us-west-2, or eu-west-1, you may need to request a quota increase through AWS Support or split the import into multiple jobs.
How Does DynamoDB Import from S3 Handle Errors and Failed Records?
During the import process, DynamoDB validates each record against the table schema. Records that fail validation (missing partition key, wrong attribute type, malformed data) are logged to Amazon CloudWatch Logs under the /aws-dynamodb/imports log group. Failed records are still billed as part of the import. If the error count exceeds 10,000, DynamoDB stops logging individual errors to CloudWatch but continues the import.
Best practice: run a test import with a small subset of your data (1,000-10,000 records) before importing the full dataset. This catches schema mismatches, encoding issues, and format errors before you pay for the full import. A test import on 1 GB of data costs $0.15, a trivial investment to avoid a failed 1 TB import that still incurs $153.60 in charges.
What Is the Best Way to Import Data from S3 to DynamoDB for Different Use Cases?
The right method to import data from S3 to DynamoDB depends on whether you are loading into a new table or an existing one, and the volume of data involved.
Migration or Initial Load (New Table)
Use the native DynamoDB import from S3 feature. It is the cheapest ($0.15/GB), requires no code, consumes no WCU, and populates GSIs at no extra charge. Define your table schema, GSIs, and capacity mode before starting the import. The table is created in the same operation.
Backfill into Existing Table (Under 1 GB)
Use BatchWriteItem with the AWS SDK. For small datasets, the on-demand write cost is under $1.25, and the operational complexity is minimal. A single Lambda function or a local script can handle this volume in minutes.
Backfill into Existing Table (Over 1 GB)
Use AWS Glue or a multi-threaded BatchWriteItem loader. For datasets between 1 GB and 100 GB, temporarily increase provisioned WCU for the backfill window to control costs. For datasets over 100 GB, the export-merge-reimport workaround ($0.25/GB) may be cheaper than sustained BatchWriteItem at on-demand rates ($1.25/million WRU).
Cross-Account or Cross-Region Table Copy
Use DynamoDB Export to S3 ($0.10/GB) from the source account/region, copy the S3 data to the target account/region bucket, then use import from S3 to DynamoDB in the target ($0.15/GB). Total: $0.25/GB plus S3 cross-region transfer ($0.02/GB if applicable). This is the cheapest fully managed approach for cross-account DynamoDB table migration.
How Does the Import Interact with Table Capacity Mode and Reserved Capacity?
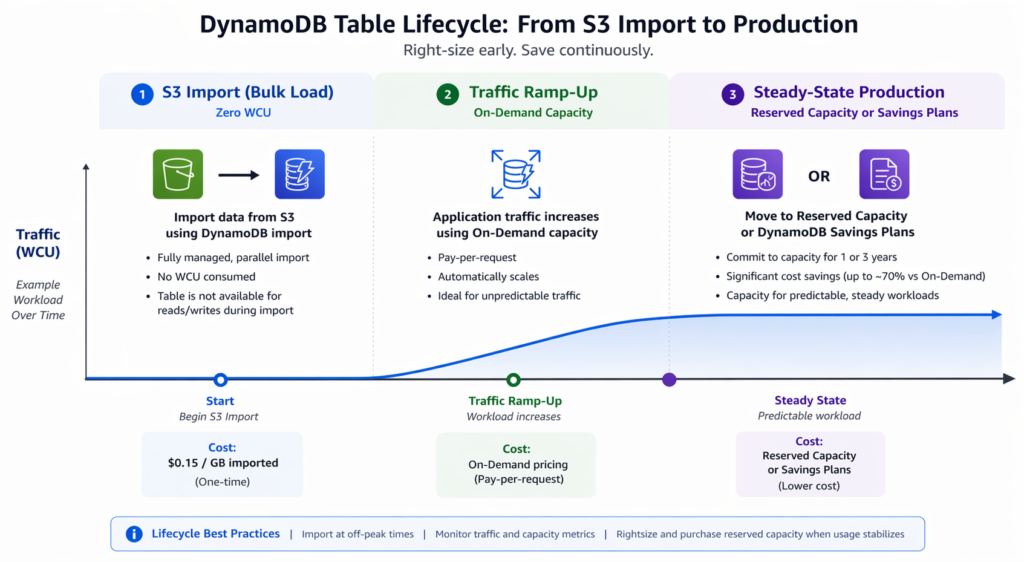
The DynamoDB import from S3 process does not consume any write capacity on the target table. This means your capacity mode selection (on-demand or provisioned) only matters for post-import production traffic, not for the import itself.
During the import, the table is created with your specified capacity mode, but no WCU are consumed by the import process regardless of which mode you choose. After the import completes and production traffic begins, the table starts consuming read and write capacity at the mode’s standard rates.
This creates a natural inflection point: the import is the cheapest phase of a DynamoDB table’s lifecycle. The ongoing production read/write capacity is where the real cost optimization happens. For tables that will sustain steady traffic after the initial load, reserved capacity offers 53% savings (1-year) to 73% savings (3-year) on provisioned WCU and RCU.
Usage.ai automates this post-import capacity optimization through its Flex Reserved Instances product for DynamoDB. Once your table is live and production traffic patterns stabilize (typically within 7-14 days), Usage.ai analyzes the read and write capacity consumption, then purchases reserved capacity blocks where the utilization justifies the commitment. The platform refreshes recommendations every 24 hours, compared to AWS Cost Explorer’s 72+ hour cycle. If a reservation becomes underutilized because workload patterns shift, Usage.ai provides cashback and credits on the unused portion. The fee is a percentage of realized savings only.
Also read: DynamoDB Reserved Capacity: 1-Year vs 3-Year Pricing Compared
How Does DynamoDB Export to S3 Compare to Import from S3 in Pricing?
DynamoDB offers both export to S3 and import from S3 as managed features. They are priced differently and serve opposite data flow directions.
| Feature | Export to S3 | Import from S3 |
| Direction | DynamoDB -> S3 | S3 -> DynamoDB |
| DynamoDB fee | $0.10/GB (full export) | $0.15/GB (uncompressed source) |
| Capacity consumed | Zero RCU | Zero WCU |
| Target | S3 bucket (any account/region) | New DynamoDB table only |
| Output/Input formats | DynamoDB JSON, Amazon Ion | CSV, DynamoDB JSON, Amazon Ion |
| PITR required? | Yes (for full export) | No |
A round-trip (export then import) costs $0.25/GB total. For a 100 GB table, that is $25.00 to clone it to a new table in the same or different account/region. This is cheaper than any BatchWriteItem approach for datasets above approximately 20 GB.
Frequently Asked Questions
1. How much does DynamoDB import from S3 cost?
DynamoDB import from S3 costs $0.15 per GB of uncompressed source data in US East (N. Virginia). GSI population during the import incurs no additional DynamoDB charge. You also pay standard S3 costs for storing source data and GET requests. For 100 GB, the total cost is approximately $17.40 including S3 charges.
2. Can you import from S3 to an existing DynamoDB table?
No. The DynamoDB import from S3 feature only loads data into a new table created during the import process. You cannot import from S3 to an existing DynamoDB table. The workaround is to export the existing table to S3 ($0.10/GB), merge the datasets, and reimport into a new table ($0.15/GB), then swap application references to the new table.
3. How do I import data from S3 to DynamoDB?
Navigate to the DynamoDB console, choose Imports from S3, select your source S3 bucket and prefix, choose the input format (CSV, DynamoDB JSON, or Amazon Ion), define the target table schema and capacity mode, then start the import. No code or servers required. You can also initiate the import through the AWS CLI or SDK using the ImportTable API.
4. What formats does DynamoDB import from S3 support?
Three formats are supported: CSV, DynamoDB JSON, and Amazon Ion. All S3 objects under the specified prefix must use the same format. Compression is supported via GZIP or ZSTD. The objects do not need matching file extensions. DynamoDB uses the format specified in the ImportTable API call, not the file extension.
5. How much does DynamoDB export to S3 cost?
DynamoDB full export to S3 costs $0.10 per GB of table data (including local secondary indexes) at the point-in-time of the export. Incremental exports are charged based on the size of data processed from PITR backups. S3 PUT request charges and storage costs apply separately.
6. Is DynamoDB more expensive than S3?
Yes, significantly. DynamoDB Standard storage costs $0.25/GB-month versus S3 Standard at $0.023/GB-month, roughly a 10x difference. DynamoDB is a database optimized for low-latency key-value reads and writes, while S3 is object storage. For data that needs sub-millisecond access patterns, DynamoDB justifies the premium. For archival or bulk analytics, S3 is the cheaper option.
7. How long does a DynamoDB import from S3 take?
Import duration depends on data volume, item count, and number of GSIs being populated. AWS does not publish specific throughput benchmarks, but community reports indicate approximately 1-2 hours per 100 GB for simple schemas without GSIs. Adding GSIs increases import duration roughly proportionally to the number of indexes. Run a test import on a representative subset to estimate duration for your specific dataset.
8. Does the DynamoDB import from S3 feature work across AWS accounts?
Yes. The requester must have permission to list and read from the source S3 bucket. Configure the S3 bucket policy to allow cross-account access, and ensure the DynamoDB import role in the target account has s3:GetObject and s3:ListBucket permissions on the source bucket. No cross-account data transfer fee applies if both accounts are in the same region.


