.png)


Redshift Advisor sits quietly in your console generating recommendations that most teams glance at once and never act on. That is a shame, because the recommendations it surfaces — when they fire — tend to reflect real, measurable inefficiencies in your cluster, not generic best-practice nudges.
The sort key recommendations come from actual query pattern analysis. The compression recommendations come from actual column-level storage inspection. Advisor is telling you something specific about your specific cluster, not giving you a checklist copied from a whitepaper.
This guide covers every recommendation type Advisor generates, where the analysis behind each one comes from, what implementing the recommendation actually involves, and a few things about Advisor’s current capabilities that most guides miss entirely — including the newer data mesh analysis and the region availability constraint that trips teams up.
%2013%20(4).svg)
How Redshift Advisor Works
Advisor develops its recommendations by running tests on your clusters and workgroups against a set of performance and usage metrics. The tests evaluate whether a measured value for your cluster falls within a specified range. When a metric is outside the expected range, Advisor generates an observation that feeds into a recommendation. When the metric returns to range, the recommendation is removed.
This makes Advisor dynamic: recommendations appear and disappear based on your cluster’s actual behavior over time. A recommendation to update table statistics fires when Advisor detects stale statistics impacting query plans. It disappears after you run ANALYZE or after Redshift’s automatic statistics maintenance catches up. The recommendations in your console at any given time represent the current state of your cluster’s health, not a static checklist.
Advisor ranks recommendations by order of impact, so the highest-priority items appear first. The impact ranking is based on the estimated performance or cost improvement from implementing the recommendation, relative to your cluster’s current state.
How to access Advisor
Three access methods are available. In the AWS Management Console: sign in, open the Amazon Redshift console at console.aws.amazon.com/redshiftv2/, and choose Advisor from the navigation menu. You can expand each recommendation to see details, sort and group the list, and review the observations behind each recommendation.
Programmatically: use the Amazon Redshift API’s ListRecommendations operation. This requires the redshift: ListRecommendations permission attached to your IAM role or identity. The API output includes the same recommendation types available in the console and can be ingested into external scripts, monitoring tools, or cost governance dashboards.
Via the AWS CLI: the same ListRecommendations call is available through the CLI for teams that prefer scripted access or want to automate recommendation monitoring.
Region availability
Redshift Advisor is not available in all AWS Regions. AWS documentation lists specific supported regions including US East (N. Virginia), US West (N. California), and others. If you do not see Advisor in your Redshift console navigation, verify whether your cluster’s region is on the supported list at docs.aws.amazon.com/redshift/latest/dg/advisor.html. A missing Advisor menu is a region availability issue, not a permissions issue, in most cases.
Also read: Redshift Reserved Nodes: 1-Year vs 3-Year — The Actual Math Behind Which Term to Choose
Data sharing and data mesh analysis
One of the newer Advisor capabilities that most guides have not caught up with: when you use Amazon Redshift Data Sharing, Advisor now analyzes workload patterns across all clusters and workgroups in your data mesh, including clusters and workgroups in different regions.
When tables are shared between producer and consumer clusters, Advisor automatically collects query patterns from all consumer endpoints in the data mesh and combines them with producer workloads to generate recommendations. Source: AWS official Advisor documentation.
The practical implication: table optimization recommendations for a producer cluster now reflect how the data is actually being queried across your entire organization, not just the patterns observed on the producer cluster itself.
A consumer cluster running analytical queries against a shared table with different filter patterns than the producer’s own queries will influence the sort key and distribution key recommendations for that shared table. This is a meaningful accuracy improvement for multi-cluster architectures.
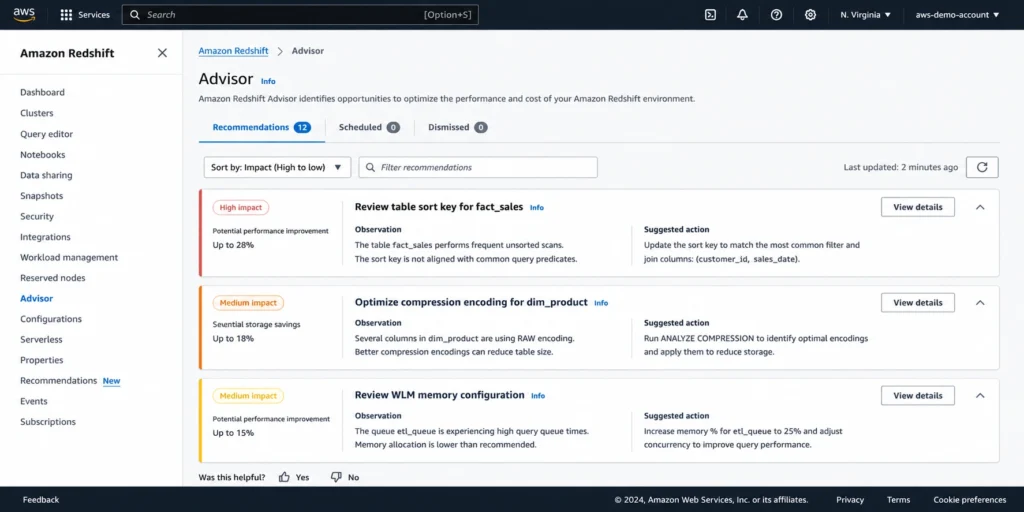
The 11 Recommendation Types: What Fires, Why, and What to Do
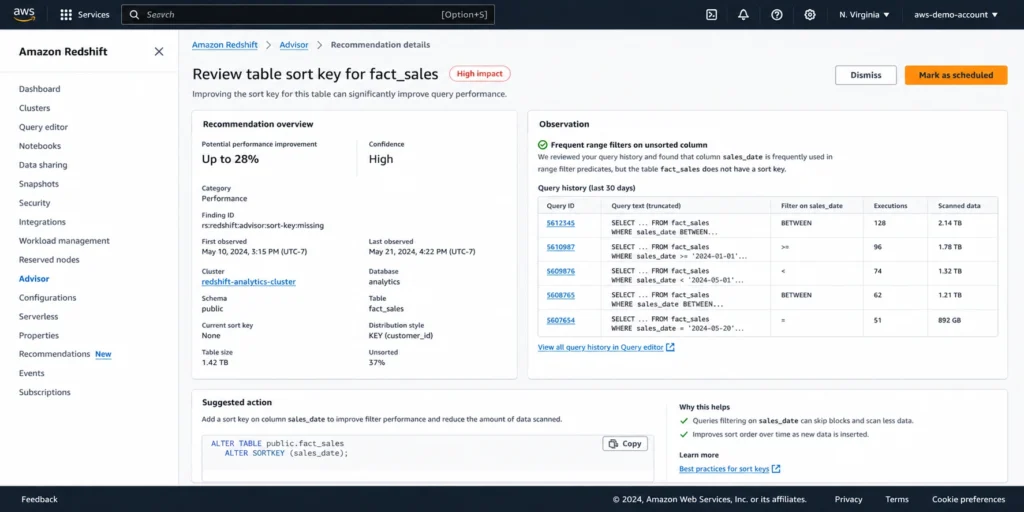
1. Alter sort keys on tables
Advisor analyzes your query patterns to determine whether your table’s current sort key configuration is well matched to the actual filters and joins in your workload. If queries frequently filter on columns that are not sort keys, or if the sort key order does not match the selectivity of the query predicates, Advisor generates a recommendation to alter the sort key.
The underlying analysis: Advisor reviews query history and identifies the columns used most frequently in WHERE clause filters and JOIN conditions. It then compares those columns to the table’s existing sort key definition. When there is a significant mismatch, the recommendation fires.
What to do: Advisor specifically favors compound sort keys over interleaved sort keys for most workloads. AWS documentation states that compound sort keys reduce maintenance overhead significantly because they do not require the expensive VACUUM REINDEX operations that interleaved sort keys need. In practice, compound sort keys are more effective than interleaved for the vast majority of Redshift workloads. The exception is small tables, where Advisor may recommend removing a sort key entirely to avoid sort key storage overhead.
To implement: use the ALTER TABLE command to modify the sort key. Redshift supports online sort key changes without locking the table for reads. When sorting a large table, cluster resources are consumed and table locks are required at certain points during the sort operation. Implement sort key changes when cluster workload is moderate. Source: AWS official Advisor documentation.
The newer option: consider specifying SORTKEY AUTO on tables where you want Redshift to manage sort key selection automatically through automatic table optimization. With SORTKEY AUTO, Redshift monitors query patterns and adjusts sort keys without requiring manual intervention or Advisor-driven ALTER TABLE operations. This eliminates the recurring cycle of sort key review.
2. Alter distribution keys on tables
Distribution keys determine how Redshift distributes table rows across compute nodes. The right distribution key minimizes data movement during JOIN operations by co-locating rows from different tables that are frequently joined on the same node. Poor distribution key choices force Redshift to redistribute large amounts of data during query execution, increasing network traffic and query latency.
Advisor identifies distribution key improvement opportunities by analyzing JOIN patterns in your query history. If two frequently joined tables use different distribution keys or if a high-traffic table uses EVEN or ALL distribution when a specific KEY distribution would improve JOIN performance, Advisor generates a recommendation.
What to do: for high-traffic JOIN tables, use the recommended KEY distribution style on the column that appears most frequently in JOIN conditions. For small dimension tables that are joined frequently, ALL distribution (storing a full copy on every node) can eliminate distribution entirely for those joins. Redshift supports ALTER TABLE to change distribution styles, though changing distribution on large tables is a resource-intensive operation.
As with sort keys, specifying DISTSTYLE AUTO delegates distribution key selection to Redshift’s automatic table optimization, which continuously monitors JOIN patterns and adjusts distribution accordingly.
3. Alter compression encodings on columns
Redshift stores data in a columnar format and applies compression encoding per column. The right encoding for each column’s data type and value distribution reduces storage consumption and improves I/O throughput during scans. Wrong encoding choices (or no encoding at all) increase both storage cost and query scan time.
Advisor identifies columns where the current encoding is suboptimal by comparing the actual data stored in each column to the available encoding options. When a column’s data characteristics would compress significantly better under a different encoding, Advisor generates a recommendation.
What to do: the most common Advisor finding here is uncompressed columns that should have an encoding applied. The ANALYZE COMPRESSION command samples a table and returns the recommended encoding for each column. You can then implement the recommendations by recreating the table with the suggested encodings or by running COPY with automatic compression enabled on a reload. Source: AWS official ANALYZE COMPRESSION documentation.
One important exception from AWS documentation: avoid compressing sort key columns. If the sort key is compressed and if the sort key skew ratio is significantly high, recreate the table without compression on the sort key. Compression on sort keys can degrade the sort key effectiveness.
Also read: Redshift Reserved Nodes: The Complete Guide
4. Update table statistics (run ANALYZE)
Redshift uses table statistics — the distribution of values in each column, row counts, and value frequencies — to generate query execution plans. When statistics are stale, the query planner makes suboptimal decisions about join order, distribution, and scan strategies. This directly degrades query performance on the tables with outdated statistics.
Advisor fires this recommendation when it detects that statistics for a table are significantly out of date relative to the table’s current data volume and distribution. Common triggers: tables that have had large data loads or deletes since the last ANALYZE, tables with automated statistics maintenance disabled, or clusters where the automatic ANALYZE process has not completed recently.
What to do: run the ANALYZE command against the flagged tables, or against the entire database if multiple tables are affected. Redshift automatically runs ANALYZE in the background for most operations, which lessens the need for manual ANALYZE. However, for tables with very large and frequent data loads, manual ANALYZE after major load operations ensures the query planner has current statistics.
5. Skip compression analysis during COPY
When you load data into an empty table using the COPY command without specifying compression encodings, Redshift automatically analyzes the incoming data to determine optimal encodings before writing. This automatic compression analysis is useful for one-time or infrequent loads but adds significant time to structured, recurring ETL processes.
Advisor generates this recommendation when it detects that COPY operations are being delayed by automatic compression analysis. The detection is based on COPY operations where the analysis sampling is adding measurable load time overhead.
What to do: for structured ETL processes where compression encodings are known in advance, define encodings explicitly in the table DDL and use COMPUPDATE OFF in the COPY command to skip the analysis phase. This is appropriate when the ETL process is a regular, well-defined operation. For initial loads where encodings are unknown, automatic compression analysis is still the right approach.
6. Compress Amazon S3 file objects loaded by COPY
If your ETL process stages data in Amazon S3 before loading it into Redshift via COPY, and if that staged data remains in S3 after loading (common in data lake architectures), storing the staged files in a compressed form reduces S3 storage costs. Uncompressed S3 staging files also result in larger network transfer volumes during the COPY load, which can increase load time.
Advisor generates this recommendation when it detects COPY loads from S3 where the source files are uncompressed. AWS documentation recommends compressing files with gzip, lzop, or bzip2. The ideal object size after compression is 1 to 128 MB per file.
What to do: update the upstream ETL process to write compressed output to S3 before the Redshift COPY operation. The COPY command automatically detects and decompresses gzip, lzop, and bzip2 files. No changes to the COPY command itself are needed if the file extension reflects the compression format.
7. Split Amazon S3 objects loaded by COPY
Redshift loads data in parallel: each compute node reads a subset of the S3 source files simultaneously. When the S3 source contains too few files relative to the number of compute nodes (or slices per node), some nodes sit idle during the load while others are fully occupied. This under-parallelizes the load and increases overall load time.
Advisor generates this recommendation when the number of S3 files in a COPY operation is significantly less than the number of slices available for parallel processing. The general guidance from AWS documentation is to produce enough files to ensure each compute node slice has at least one file to process.
What to do: update the upstream process to split large single files into multiple smaller files, each in the 1-128 MB compressed range, before staging to S3. Most ETL frameworks support output file splitting as a configuration parameter.
8. Reallocate workload management (WLM) memory
Redshift’s Workload Management (WLM) configuration controls how query queues are defined and how memory is allocated to each queue. Poorly configured WLM settings result in queries waiting in queues when memory is available but allocated to an underused queue, or in queries running with insufficient memory and spilling to disk.
Advisor generates this recommendation when it observes significant disk spilling in query execution (indicating memory pressure) or when queue wait times are high alongside idle memory in other queues. The recommendation typically suggests redistributing memory percentages across queues to better match actual workload patterns.
What to do: review the WLM configuration in the Redshift Parameter Group settings and adjust memory percentages per queue based on the observed workload patterns. Redshift also supports automatic WLM, which dynamically manages concurrency and memory without requiring manual queue configuration. For clusters where WLM tuning is a recurring pain, switching to automatic WLM may be more sustainable than continuously tuning fixed allocations.
9. Enable short query acceleration (SQA)
Short Query Acceleration prioritizes small, fast queries over longer-running queries in the query queue. When SQA is enabled, Redshift uses machine learning to predict query execution times and automatically routes short queries to a dedicated queue with fast execution priority. This reduces wait times for operational queries, reporting queries, and user-facing analytics that would otherwise queue behind long batch jobs.
Advisor generates this recommendation when it detects that short queries are consistently waiting behind long queries and that SQA would improve their completion times based on your query patterns.
What to do: enable SQA in the WLM configuration. SQA is a parameter group setting. The maximum query execution time for SQA eligibility is also configurable. AWS documentation notes that SQA is particularly effective when a cluster runs a mix of short interactive queries and long batch analytical queries.
10. Isolate multiple active databases
Redshift allows multiple databases on a single cluster, but queries running in different databases share the same underlying cluster compute and storage resources. When multiple active databases have unrelated workloads running simultaneously, the workloads compete for the same cluster resources, which can degrade performance for both.
Advisor analyzes all databases on the cluster for concurrent active workloads. If it detects active workloads running at the same time across databases that appear to be unrelated (different users, different query patterns, different times), it generates a recommendation to consider migrating databases to separate Redshift clusters.
What to do: evaluate whether the active databases serve genuinely separate teams or use cases that would benefit from dedicated cluster resources. If so, migrating each database to a dedicated cluster or considering a Redshift Serverless workgroup per use case may improve performance and simplify cost allocation. Redshift Data Sharing provides a way to maintain data access across separate clusters without duplicating the underlying data.
11. Data type recommendations
Redshift performs best when column data types match the actual data they store. Oversized character columns (VARCHAR(MAX) where the actual values are consistently short), integer columns storing values that fit in smaller types, and timestamp columns where only date precision is needed all consume more storage than necessary and can affect compression efficiency.
Advisor identifies tables with data type mismatches by analyzing the actual stored values against the declared column types. When columns are consistently storing values well within a smaller type’s range, Advisor generates a data type recommendation.
What to do: use the suggested smaller or more precise data types in a table recreation. For large production tables, a direct ALTER TABLE to change data types is not supported for all type changes in Redshift. The common approach is to create a new table with the corrected DDL, copy data using INSERT INTO … SELECT, swap the table names, and drop the old table. This is a maintenance operation that benefits from scheduling during low-traffic windows.
Also read: Cloud Cost Automation Without Lock-In: How Usage.ai Gets You 3-Year Savings at Zero Risk
Automatic Table Optimization: When Advisor Recommendations Become Self-Maintaining
For teams that find Advisor’s sort key and distribution key recommendations recurring — you implement the suggestion, things improve, and then six months later the recommendation fires again because query patterns have shifted — the longer-term solution is automatic table optimization.
When you create a table with SORTKEY AUTO and DISTSTYLE AUTO, Redshift monitors query patterns and automatically adjusts sort keys and distribution styles without requiring ALTER TABLE operations or manual Advisor review. AWS documentation recommends creating tables with SORTKEY AUTO as the default for new tables. For existing tables, you can modify them to enable automatic optimization.
Automatic optimization and Advisor are complementary rather than exclusive. Advisor still surfaces recommendations for tables on manual configurations. For tables using AUTO settings, Advisor’s sort key and distribution key recommendations become less relevant because Redshift is already handling those adjustments continuously.
The recommendation types that remain relevant regardless of automatic optimization: compression encoding recommendations (AUTO does not automatically re-encode columns), WLM memory and SQA recommendations (workload configuration), COPY optimization recommendations (S3 object size and compression), update statistics recommendations (ANALYZE for tables with heavy DML), and the isolate databases recommendation.
What Advisor Does Not Cover
Understanding Advisor’s scope prevents misplaced expectations. It does not cover everything in Redshift cost and performance optimization.
Reserved node purchasing: Advisor does not generate recommendations for purchasing Reserved Nodes to reduce compute costs, even if your cluster has been running on on-demand pricing continuously for months. The compute billing model is outside Advisor’s scope. Reserved node analysis lives in AWS Cost Explorer and the Redshift Reserved Nodes purchase interface.
Cluster sizing and node type changes: Advisor does not recommend resizing your cluster, adding or removing nodes, or migrating to a different node family (such as from RA3 to RG). Those recommendations come from AWS Compute Optimizer and the Redshift console’s built-in sizing guidance.
Query-level optimization: Advisor does not analyze individual SQL queries and suggest query rewrites. It identifies structural issues with tables and cluster configuration. For query-level optimization, Redshift Query Execution Details, the STL_ALERT_EVENT_LOG system table, and the SVL_QLOG view provide execution-level diagnostics.
Serverless RPU sizing: Advisor supports Serverless and maintains optimization continuity across pause and resume cycles, but it does not generate recommendations for RPU base capacity sizing. Serverless capacity sizing is managed through usage monitoring and base capacity configuration rather than Advisor recommendations.
A Note on Python UDFs: A Deadline Advisor Will Not Warn You About
This is time-sensitive for any Redshift cluster using Python-based User Defined Functions. Amazon Redshift stopped supporting the creation of new Python UDFs from Patch 198. Existing Python UDFs continue to function until June 30, 2026. After that date, Python UDFs will be disabled in Redshift.
Advisor does not generate recommendations about Python UDF deprecation. If your cluster or data warehouse processes rely on Python UDFs, you need to identify them now and plan migrations to SQL UDFs, Lambda UDFs, or stored procedures before June 30, 2026. AWS documentation directs you to a blog post on the migration path. Identifying Python UDFs in your environment: query the PG_PROC system catalog filtering for prolang = (SELECT oid FROM pg_language WHERE lanname = ‘plpythonu’).
How Redshift Advisor Fits in a Complete Redshift Optimization Picture
Advisor covers one part of Redshift optimization: cluster configuration, table structure, and query routing. The FinOps Foundation’s cloud cost optimization framework would call this the Optimize phase for the performance and architecture layer. What it does not cover is the cost commitment layer — the Reserved Node purchasing and utilization management that determines your hourly compute rate.
The typical pattern for a well-run Redshift environment: review Advisor recommendations monthly and prioritize the high-impact items, implement sort key and distribution key changes during scheduled maintenance windows, let automatic table optimization handle ongoing adjustments for tables using AUTO, and manage the compute cost layer through Reserved Node coverage with regular utilization monitoring.
Usage.ai handles the Reserved Node layer: analyzing actual utilization, sizing recommendations to the stable floor, purchasing commitments, monitoring utilization throughout the term, and providing a buyback guarantee on reservations that go underutilized. Advisor and Usage.ai are not substitutes — they operate on different layers of the Redshift optimization stack, and both are worth using.
$91M+ in savings delivered to 300+ customers across AWS, Azure, and GCP. Fee is a percentage of realized savings only. No savings, no fee. 30-minute setup, billing-layer access only.
%2024%20(2).svg)
Frequently Asked Questions
1. What is Amazon Redshift Advisor?
Amazon Redshift Advisor is a free, built-in service that analyzes your cluster’s performance metrics, query history, and data patterns to generate specific optimization recommendations. It covers 11 recommendation types across table design (sort keys, distribution keys, compression), query performance (statistics updates, SQA, WLM memory), operational maintenance (VACUUM, ANALYZE), and data load optimization (S3 compression, S3 splitting, COPY compression skip). Advisor ranks recommendations by estimated impact. Access it from the Redshift console under Advisor, via the ListRecommendations API, or via the AWS CLI.
2. Is Redshift Advisor free?
Yes. Amazon Redshift Advisor is included with Amazon Redshift at no additional charge. The recommendations it generates, the analysis it performs, and the API access it provides are all part of the standard Redshift service. The only costs associated with acting on Advisor recommendations are the resources consumed when implementing changes — for example, the compute used during an ALTER TABLE operation to apply a new sort key on a large table.
3. How often does Redshift Advisor update its recommendations?
Advisor updates recommendations dynamically as cluster conditions change. Recommendations appear when Advisor’s tests detect a metric outside the expected range and disappear when the underlying condition is resolved. There is not a fixed update interval — recommendations reflect the current state of your cluster based on Advisor’s continuous analysis. After implementing a recommendation, you may need to give the cluster time to process recent queries and reflect the improvement before the recommendation clears.
4. Does Redshift Advisor work with Serverless?
Yes. Advisor supports Amazon Redshift Serverless and automatically maintains optimization continuity across pause and resume cycles. Serverless workloads receive the same recommendation types as provisioned clusters for applicable areas. Advisor also extends to serverless workgroups in data mesh architectures, analyzing cross-cluster query patterns to generate more accurate recommendations. Advisor does not generate RPU base capacity sizing recommendations for Serverless — that requires manual usage monitoring and base capacity configuration.
5. What is the difference between Redshift Advisor and AWS Trusted Advisor?
Amazon Redshift Advisor is specific to Redshift and focuses on cluster-level optimizations: table design, query performance, workload configuration, and operational maintenance. AWS Trusted Advisor is a broader service that evaluates your entire AWS environment across cost, security, performance, resilience, and service limits. Trusted Advisor can flag idle Redshift clusters or downscaling opportunities but does not provide the Redshift-specific query pattern analysis and table structure recommendations that Redshift Advisor generates. For Redshift optimization, both tools are useful but serve different purposes.
6. Why is Redshift Advisor not showing up in my console?
Redshift Advisor is only available in specific AWS Regions. If Advisor does not appear in your Redshift console navigation, the most likely cause is that your cluster is in a region where Advisor is not yet supported. Check the list of supported regions in the official Advisor documentation at docs.aws.amazon.com/redshift/latest/dg/advisor.html. If your region is listed as supported and Advisor still does not appear, verify that your IAM role includes the redshift: ListRecommendations permission.


