.png)


Most LLM cost optimization guides focus on prompts, caching, and model routing. Those techniques matter, but if you’re running LLMs on AWS, your biggest savings often come from the infrastructure layer. The right GPU instance, commitment strategy, and capacity planning can reduce costs long before model-level optimizations make a difference.
That’s why this guide focuses on AWS infrastructure for LLM workloads, covering GPU selection, Savings Plans, Spot Instances, Capacity Blocks, and the 2025 GPU price reductions that many teams still haven’t factored into their budgets.
This approach also aligns with FinOps Foundation best practices, which emphasize optimizing cloud costs across architecture, engineering, and finance together.
By the end of this guide, you’ll know exactly where your LLM infrastructure is overspending and what to optimize first.
%2017%20(1).svg)
The GPU Instance Price Reductions Most Teams Missed
Many AI teams spent months squeezing costs out of prompts, batching requests, and experimenting with smaller models. Meanwhile, AWS made one of the biggest GPU pricing changes in recent years. If your infrastructure budgets, ROI calculations, or business cases haven’t been updated since then, there’s a good chance you’re still planning around numbers that no longer exist.
In June 2025, AWS reduced pricing across several high-performance GPU instance families, and the cuts were substantial. Better yet, they weren’t limited to On-Demand pricing. The lower rates also flowed through to eligible Savings Plans, making long-running AI workloads even more economical than before.
The biggest change was for P5 instances powered by NVIDIA H100 Tensor Core GPUs, where On-Demand pricing dropped by up to 45% effective June 1, 2025. Savings Plan purchases made after June 4, 2025 also reflect the lower pricing, according to AWS.
AWS also reduced pricing for P5en instances by up to 26%, while P4d and P4de instances received reductions of up to 33%, all effective June 1, 2025.
These price reductions apply to instances running Amazon Linux. Other operating systems also benefited, although the reductions are slightly smaller. As always, verify the latest rates for your Region on the AWS pricing page before making commitment decisions.
The practical impact is larger than many teams realize. Imagine a workload that was budgeted at $100,000 per month on P5 infrastructure before June 2025. With a 45% price reduction, that same workload could now cost roughly $55,000 per month before applying Savings Plans or Spot discounts.
If your LLM training or inference cost model still uses pre-June 2025 pricing, it is almost certainly overstating your infrastructure costs and may be influencing architecture and purchasing decisions based on outdated assumptions.
Also read: AWS Savings Plans: Compute Savings Plans for EC2
Choosing the Right GPU Instance for LLM Inference vs Training
The GPU instance selection decision for LLM workloads depends on whether the workload is inference (serving user requests) or training and fine-tuning (iteratively updating model weights). These have different compute profiles, different latency requirements, and different cost-optimization paths.
Inference workloads: G-family instances
LLM inference — generating responses to user requests — benefits from high GPU memory per GPU (to hold model weights in VRAM without offloading) and low latency per request. For production inference of models up to approximately 13 billion parameters, G6e instances powered by NVIDIA L40S Tensor Core GPUs are a strong current generation choice. AWS official: G6e instances can be used to deploy large language models with up to 13B parameters, offer up to 2.5x better performance compared to G5 instances, and offer up to 20% cost savings versus P4d instances for comparable performance.
G6e specifications relevant to LLM inference: up to 8 NVIDIA L40S Tensor Core GPUs, 48 GB of memory per GPU, 384 GB total GPU memory, up to 192 vCPUs, up to 400 Gbps network bandwidth. The high per-GPU memory makes G6e well suited for inference serving where model weights must fit in GPU memory for fast token generation.
For smaller inference workloads, G5 instances (NVIDIA A10G Tensor Core GPUs) remain a cost-effective option, particularly for models under 7B parameters. G5 delivers up to 15% lower cost-to-train than P3 instances per AWS official, and is a common choice for inference workloads that do not require the memory headroom of G6e.
Training and fine-tuning: P-family instances
Model training and fine-tuning at scale benefit from the interconnect capabilities and peak throughput of the P-family instances. P5 instances (NVIDIA H100 Tensor Core GPUs) are the current generation for demanding training workloads, with the post-June 2025 pricing making them significantly more accessible than before.
P5 delivers up to 4x faster time-to-solution versus previous-generation GPU instances and reduces cost to train ML models by up to 40% versus P4d. Source: aws.amazon.com/ec2/instance-types/p5/. For organizations currently running large-scale fine-tuning on P4d or P3 instances, evaluating a migration to P5 at the updated June 2025 pricing is warranted.
P4d instances (NVIDIA A100 Tensor Core GPUs) remain available at their reduced June 2025 rates. P4d delivers an average of 2.5x better performance for deep learning models compared to previous-generation P3 instances, with up to 60% lower cost to train ML models versus P3. Source: aws.amazon.com/ec2/instance-types/p4/. For teams not yet requiring H100 capabilities, P4d at the post-reduction pricing offers strong price-performance.
Savings Plans for GPU Instances: The Commitment Layer Most AI Teams Ignore
Compute Savings Plans are available for GPU-based EC2 instances including the G4dn, G5, P3, and P4d families. A Compute Savings Plan commits to a fixed hourly dollar amount across eligible compute usage. In exchange, the discounted rate applies automatically to all eligible compute — regardless of instance family, size, region, or operating system.
For teams running steady-state inference infrastructure on GPU instances, Savings Plans reduce the on-demand compute cost by a material percentage. The 1-year and 3-year term options provide different discount depths: deeper discounts at 3-year, lower commitment lock-in at 1-year. Verify current Savings Plan rates for specific GPU instance families at aws.amazon.com/savingsplans/pricing/ — the post-June 2025 GPU price reductions also apply to the baseline against which Savings Plan discounts are calculated.
The commitment risk for GPU workloads is distinct from general-purpose compute. AI inference infrastructure tends to be more stable month-to-month than application compute — a production inference endpoint serving consistent traffic is running at roughly the same capacity every hour. This stability profile matches the Savings Plan commitment model well.
Usage.ai applies Compute Savings Plans to GPU instances (G4dn, G5, P3, P4d families) in the same automated commitment management framework used for CPU instances. Recommendations are sized to the stable inference floor — the GPU hours consumed in every hour of the rolling 30-day window.
For GPU inference clusters running 24/7 at consistent load, the combination of Savings Plans and the post-June 2025 price reductions compounds into a significantly lower effective hourly rate than on-demand. Insured Flex Commitments include a buyback guarantee: if GPU inference capacity is decommissioned or migrated mid-term, the unused commitment is returned as cashback in real money.
Also read: AWS Cost Optimization: Cloud Cost Strategies for Engineering Teams
EC2 Capacity Blocks for ML: Reserving GPU Capacity for Training Bursts
EC2 Capacity Blocks for ML let you reserve specific quantities of GPU accelerator capacity for defined durations — from days to weeks — at a published per-accelerator-hour rate. This is designed for ML training and fine-tuning workloads that need guaranteed GPU availability for a specific timeframe, without the continuous commitment of Reserved Instances or Savings Plans.
Published per-accelerator-hour rates for Capacity Blocks effective July 1, 2026: P5 at $5.191 per accelerator per hour for US regions. P5e at $5.97 per accelerator per hour for all available regions. P5en at $6.865 per accelerator per hour for US regions. P4de at $2.214 per accelerator per hour for US regions. P6-B300 at $14.04 per accelerator per hour. P6-B200 at $12.355 per accelerator per hour. Source: aws.amazon.com/ec2/capacityblocks/pricing/.
Capacity Blocks address the key operational risk of GPU training workloads: capacity availability. Unlike on-demand instances where GPU availability is not guaranteed during high-demand periods, Capacity Blocks reserve the specified accelerator capacity with a guaranteed start time. This is particularly valuable for fine-tuning runs with hard deadlines — product launches, scheduled model releases, or time-sensitive evaluation benchmarks.
The pricing consists of a reservation fee plus an operating system fee. Capacity Block pricing is updated periodically based on supply and demand — the rates above reflect the July 1, 2026 update. Verify current pricing at aws.amazon.com/ec2/capacityblocks/pricing/ before planning any significant training budget.
Spot Instances for GPU Training: Up to 90% Discount for Fault-Tolerant Workloads
Amazon EC2 Spot Instances use spare AWS compute capacity and are available at discounts of up to 90% from on-demand pricing. P4d instances are explicitly available for Spot purchase per AWS official documentation. Source: aws.amazon.com/ec2/instance-types/p4/: Spot Instances take advantage of unused EC2 instance capacity and can lower your EC2 costs significantly with up to a 90% discount from On-Demand prices.
For LLM workloads, Spot Instances are appropriate for: fine-tuning and training jobs that implement checkpoint saving (the job can be interrupted and resumed without starting over), batch inference runs where the output is not time-sensitive, data preparation and preprocessing pipelines that feed into training, and experimental and evaluation workloads where occasional interruption is acceptable.
Spot Instances are not appropriate for: production inference endpoints serving real-time user requests (interruptions would cause outages), time-critical fine-tuning jobs without checkpointing, or single-node training jobs that cannot be resumed from checkpoints.
Implementing checkpointing for fault tolerance: for training jobs on Spot, the pattern is to write model checkpoint files to Amazon S3 at regular intervals (every N training steps). When a Spot interruption occurs, the job is terminated and the latest checkpoint is preserved in S3. On restart, the job loads from the checkpoint and continues. The training time overhead of checkpointing is typically small relative to the 90% compute cost savings on Spot.
Diversification for Spot availability: Spot availability varies by instance type and Availability Zone. Diversifying across multiple GPU instance families (P4d, G5, P3dn) and multiple AZs reduces the probability of simultaneous unavailability. AWS EC2 Fleet and Amazon SageMaker managed Spot training both support multi-instance-type Spot diversification automatically.
The Model API Layer: Infrastructure for Managed Inference
Not all LLM inference runs on self-hosted GPU infrastructure. For managed API-based inference (OpenAI, Anthropic, Google, AWS Bedrock), the cost levers are different from infrastructure selection. This section covers the API-layer optimizations that apply regardless of which infrastructure strategy you use for self-hosted workloads.
Token pricing asymmetry: why input and output costs differ
Managed LLM providers price input tokens (your prompt) and output tokens (the model’s response) at different rates. Output tokens — the generated response — cost significantly more per token than input tokens in most pricing tiers. This asymmetry reflects the computational cost structure of autoregressive generation: generating each output token requires a forward pass through the model, while processing input tokens is more parallelizable.
The practical implication: optimizations that reduce output token count (more concise system instructions, structured output formats that avoid verbose filler, response length constraints) yield higher savings per token reduced than optimizations targeting only the input side.
Provider-level prompt caching
Both OpenAI and Anthropic offer prompt caching at the API level. OpenAI Cached Inputs delivers approximately 50% discounts on cached prompt content for eligible models. Anthropic Prompt Caching provides similar benefits.
Prompt caching is most effective for applications with a large, stable system prompt that is repeated across many requests — RAG applications with a fixed knowledge base preamble, coding assistants with detailed instructions, customer service bots with extensive product knowledge. The cached portion of the prompt is billed at the reduced cached rate; only the per-request variable input (the user query) is billed at the standard rate.
Implementation: for OpenAI, prompts over a threshold length (typically 1,024 tokens for Cached Inputs) are automatically cached after the first use. For Anthropic Prompt Caching, you enable caching explicitly by adding cache-control headers to the sections of your prompt you want cached. The cache TTL is typically a few minutes to an hour depending on provider and endpoint.
Model routing: matching request complexity to model tier
LLM provider pricing varies by a factor of 100 or more between frontier models and small models. Frontier models like GPT-4o or Claude Opus 4 are appropriate for complex, multi-step reasoning tasks. Smaller models like GPT-4o-mini or Claude Haiku are sufficient for extraction, classification, simple Q&A, and structured data tasks. Routing each request to the cheapest model capable of handling it — rather than sending everything to the frontier model — is the highest-ROI model-layer optimization for most production applications.
The routing decision is typically based on one or more of: heuristic request classification (length, keywords, request type metadata), a fast lightweight classifier model that predicts whether a smaller model can handle the request, or explicit application-layer routing based on the user’s request type (search vs synthesis vs extraction). The routing infrastructure cost is negligible compared to the savings from sending 60-80% of requests to a model tier costing 50-100x less than the frontier.
%2018.svg)
Batching for throughput optimization
For self-hosted inference, batching multiple requests into a single GPU pass improves utilization and reduces effective cost per request. Without batching, a GPU executing one request at a time may be utilized at 20-30% of its throughput capacity — the GPU is waiting between requests rather than processing. With batching, multiple requests are grouped and processed simultaneously, pushing GPU utilization to 70-90%.
Dynamic batching (grouping requests as they arrive within a latency window) is a standard feature of production LLM inference servers such as vLLM, TGI (Text Generation Inference), and NVIDIA Triton. Configuring the batch size and latency window correctly for your traffic pattern determines the effective throughput at a given GPU count. Over-aggressive batching increases per-request latency; under-batching wastes GPU cycles.
At constant traffic volume: doubling effective GPU utilization through batching halves the GPU count required to serve the same load, directly halving the infrastructure cost.
Quantization: Running More Model per GPU
Quantization reduces the numerical precision of model weights — from 32-bit or 16-bit floating point to 8-bit or 4-bit integers — shrinking the memory footprint and improving throughput on a given GPU hardware. The cost impact is direct: a model that fits in GPU memory at 4-bit quantization requires fewer GPUs (or a smaller GPU SKU) than the same model at full 16-bit precision.
Quantization trade-offs are task-dependent. For many production inference use cases, INT8 quantization delivers inference quality nearly indistinguishable from FP16 at substantially lower memory cost. 4-bit quantization (GPTQ, GGUF, AWQ formats) enables even larger models to fit on smaller GPU configurations but can affect quality on tasks requiring precise numerical reasoning or complex multi-step generation.
For AWS-hosted inference: quantized models running on G5 or G6e instances can serve models that would otherwise require the larger GPU memory of P4d or P5 instances. The per-hour rate for G5 and G6e is lower than P4d and P5, and the memory headroom provided by quantization enables the cost-performance trade-off to favor the smaller instance type for many inference use cases.
KV Cache Optimization: Reducing Memory Waste During Generation
The KV cache (key-value cache) stores intermediate attention computations during token generation, avoiding recomputing them for each new token. It enables efficient generation but consumes significant GPU memory proportional to context length and batch size. For long-context workloads (systems processing documents of tens of thousands of tokens), the KV cache can consume a large fraction of available GPU memory.
When KV cache memory consumption causes the model to fall below the GPU memory available on a given instance type, two outcomes occur: either requests fail (GPU OOM), or the system falls back to slower CPU offloading. Both are expensive: OOM requires larger GPU instances, and CPU offloading dramatically reduces throughput.
Techniques that reduce KV cache memory consumption: KV cache quantization (reducing precision of cached states), context length limits (capping the maximum input plus output length below the full model context window), sliding window attention (limiting the active KV cache to recent tokens for very long sequences), and prefix caching (sharing KV cache state across requests that share a common prefix, which is the infrastructure-level analog of provider-level prompt caching).
For cost optimization: right-sizing the GPU instance for your actual maximum context length and batch size — rather than the theoretical maximum the model supports — is the most direct path to avoiding over-provisioning of GPU memory and the associated overpayment for GPU SKUs that are larger than needed.
The Break-Even Analysis: Self-Hosted vs Managed API Inference
For teams choosing between self-hosted GPU inference and managed API providers, the break-even calculation is a function of request volume, average token count per request, and the target model size.
Managed API pricing scales linearly with token volume — every request adds to cost, and there is no fixed capacity component. Self-hosted GPU inference has a fixed cost (the GPU instance rate) plus a variable compute cost, but the per-request marginal cost approaches zero once the GPU is already paid for.
At low request volumes, managed APIs are almost always more cost-effective: there is no idle GPU capacity to pay for. The break-even point where self-hosted inference becomes cheaper depends on average utilization of the self-hosted fleet. At high GPU utilization (70-90%), the per-request cost of self-hosted inference falls well below equivalent managed API rates for most model tiers. At low GPU utilization (20-30% common without batching), the effective per-request cost of self-hosted inference may exceed managed API rates even at substantial request volumes.
Simplified break-even estimate: if a G5 instance running an open-source model costs $X/hour on-demand and serves Y requests per hour at target quality, and the managed API equivalent costs $Z per request, the break-even is when X/Y = Z (that is, the per-request cost of the GPU instance equals the per-API-call rate). Above this request volume, self-hosted is cheaper. Below it, managed API is cheaper.
%2015.svg)
How Usage.ai Optimizes LLM Infrastructure Costs
Usage.ai manages GPU instance commitment optimization alongside general-purpose EC2, RDS, and other services in the same multi-cloud platform. For LLM infrastructure specifically:
Savings Plan optimization for GPU fleets: Usage.ai identifies EC2 instances in GPU families eligible for Compute Savings Plans (G4dn, G5, P3, P4d and others). For inference clusters running at consistent GPU utilization, the platform sizes the Savings Plan commitment to the stable hourly spend floor — the GPU hours that exist in every hour of the evaluation window, including overnight and weekends when traffic may be lower. This prevents over-committing GPU capacity that is only required during peak inference hours.
Post-price-reduction rate verification: Usage.ai flags GPU instance commitments that were purchased against pre-June 2025 on-demand rates. For P5 and P4d instances specifically, a Savings Plan purchased before the June 1, 2025 price reduction may reflect the older, higher baseline rate. Verifying that current commitments reflect the post-reduction effective rates prevents teams from paying Savings Plans sized against an inflated baseline.
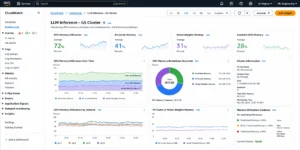
Right-size before commit: Usage.ai pulls GPU utilization metrics (GPU Utilization, GPU Memory Utilization) from CloudWatch for each GPU instance in the fleet. Instances consistently running at low GPU memory utilization relative to available VRAM are flagged as candidates for a smaller GPU SKU before any Savings Plan commitment is generated. A Savings Plan on an oversized G5.12xlarge when actual memory utilization supports a G5.4xlarge locks in the over-provisioning for the full commitment term.
Insured Flex Commitments: every GPU Savings Plan purchased through Usage.ai includes the buyback guarantee. If an inference deployment is replaced by a managed API migration, an architecture change reduces the GPU count, or a model migration moves from one GPU instance family to another mid-term, the unused commitment is bought back and returned as cashback in real money.
$91M+ in savings delivered to 300+ enterprise customers across AWS, Azure, and GCP. 30-minute setup, billing-layer access only. Fee: percentage of realized savings only. $0 if Usage.ai saves nothing.
See exactly what you’re overpaying on GPU and AI compute in under 60 seconds. Try the Calculator free →
Frequently Asked Questions
Which AWS GPU instances are best for LLM inference?
For LLM inference workloads up to approximately 13B parameters, G6e instances (NVIDIA L40S, 48 GB GPU memory each) are the current recommended choice. AWS official states G6e delivers up to 2.5x better performance versus G5 and up to 20% cost savings versus P4d for comparable performance. For smaller models under 7B parameters or development inference workloads, G5 instances remain a cost-effective option. For larger models requiring maximum GPU memory and throughput, P5 instances (NVIDIA H100) at the post-June 2025 reduced rates are the current production choice. Verify current on-demand rates at aws.amazon.com/ec2/pricing/on-demand/ — rates change.
How much did AWS reduce GPU instance prices in 2025?
In June 2025, AWS reduced on-demand pricing for several GPU instance families: P5 instances by up to 45%, P5en instances by up to 26%, P4d and P4de instances by up to 33%. These reductions apply to instances running Amazon Linux, with slightly smaller reductions for other operating systems. Savings Plan rates effective after June 4, 2025 also reflect the reduced baselines.
Can I use Spot Instances for LLM training on AWS?
Yes. P4d instances are explicitly available for Spot purchase per AWS official documentation. Spot Instances provide up to 90% discount from on-demand pricing. Spot is appropriate for training and fine-tuning workloads that implement checkpoint saving to S3 — when a Spot interruption occurs, the job resumes from the last checkpoint. Spot is not appropriate for production inference endpoints serving real-time requests. For training runs requiring guaranteed capacity (hard deadlines, no interruption tolerance), EC2 Capacity Blocks for ML provide reserved GPU capacity at a published per-accelerator-hour rate.
What are EC2 Capacity Blocks for ML?
EC2 Capacity Blocks for ML let you reserve specific GPU accelerator capacity for defined durations at a published per-accelerator-hour rate. Current rates effective July 1, 2026: P5 at $5.191/accelerator/hr (US regions), P5e at $5.97/accelerator/hr, P5en at $6.865/accelerator/hr (US), P4de at $2.214/accelerator/hr (US). Capacity Blocks are designed for ML training and fine-tuning workloads needing guaranteed GPU availability for specific durations, without the continuous commitment of Reserved Instances.
Do Compute Savings Plans apply to GPU instances on AWS?
Yes. Compute Savings Plans apply to eligible GPU instance families including G4dn, G5, P3, and P4d, among others. A Compute Savings Plan commits to a fixed hourly spend amount across eligible EC2 instances and automatically applies the discounted rate to any eligible usage — including GPU instances — regardless of instance family, size, or region. For inference clusters running at consistent GPU utilization, Compute Savings Plans are one of the most direct infrastructure cost reduction mechanisms available. Verify eligible instance families and current Savings Plan rates at aws.amazon.com/savingsplans/pricing/.


