.png)


RDS Multi-AZ DB Cluster: 2 Readable Standbys and Cost Comparison
Choose Multi-AZ DB Cluster when you need both read scaling and fast failover (under 35 seconds) in a single managed deployment, and when you are currently running a Multi-AZ instance plus a standalone read replica. The cluster replaces both with one managed unit at a similar or lower total cost.
Choose standard Multi-AZ when you only need failover protection and your reads run on the primary, or when your engine is not MySQL or PostgreSQL (the cluster is not available for MariaDB, Oracle, or SQL Server). On a per-instance basis, Multi-AZ DB Cluster costs exactly 3x Single-AZ — there is no discount for the cluster topology itself.
What Is the RDS Multi-AZ DB Cluster and How Does It Differ from Standard Multi-AZ?
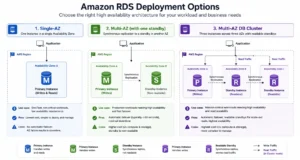
RDS offers three deployment topologies for relational databases, each with different availability characteristics, read capabilities, and cost structures.
Single-AZ: One Instance
One database instance in one Availability Zone. If the instance fails or the AZ experiences an outage, the database is unavailable until AWS restores it or you restore from a snapshot. No automatic failover. Cheapest option. Appropriate for dev, test, and non-critical workloads where downtime is acceptable.
Multi-AZ (One Standby): Two Instances
One primary instance and one synchronous standby instance in different Availability Zones. The standby is a hot copy that cannot serve read queries — it exists exclusively as a failover target. If the primary fails, AWS promotes the standby to primary in approximately 60 seconds with zero data loss. Costs 2x the single-instance rate. Available for all RDS engines: MySQL, MariaDB, PostgreSQL, Oracle, SQL Server, and Db2.
Multi-AZ DB Cluster (Two Readable Standbys): Three Instances
One primary and two readable standby instances in three different Availability Zones, using a Raft-based consensus replication protocol. Both standbys can serve read-only queries. Failover completes in under 35 seconds. Costs 3x the single-instance rate. Available only for MySQL and PostgreSQL. This is the RDS Multi-AZ DB Cluster. The standbys are fully active instances, not passive hot copies. Applications can direct read traffic to the cluster reader endpoint and AWS routes reads to the standbys automatically.
Also read: RDS Encryption: Does Encrypting Your Database Add Cost?
What Is the Exact Cost Comparison Between All Three RDS Deployment Options?
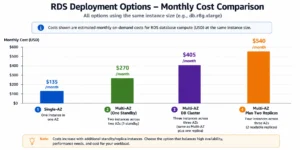
Here is the complete cost breakdown for all three deployment types plus the common alternative (Multi-AZ instance plus separate read replica) for a db.m7g.large MySQL in US East (N. Virginia) as of May 2026 (verify at aws.amazon.com/rds/mysql/pricing — rates change).
| Deployment Option | Instances Running | On-Demand/hr | Monthly Cost | Readable for Reads? | Failover Time |
| Single-AZ | 1 | $0.185 | $135 | Primary only | Manual (mins-hrs) |
| Multi-AZ (one standby) | 2 (primary + 1 standby) | $0.370 | $270 | Primary only (standby not readable) | ~60 seconds |
| Multi-AZ DB Cluster | 3 (primary + 2 readable standbys) | $0.555 | $405 | Primary + 2 standbys (reader endpoint) | < 35 seconds |
| Multi-AZ + 1 read replica | 3 (primary + standby + replica) | $0.555 | $405 | Primary + 1 replica (replica readable) | ~60 sec (Multi-AZ failover) |
| Multi-AZ + 2 read replicas | 4 (primary + standby + 2 replicas) | $0.740 | $540 | Primary + 2 replicas readable | ~60 sec |
The critical comparison in row 3 versus row 4: a Multi-AZ DB Cluster and a Multi-AZ instance plus one read replica cost exactly the same ($0.555/hr for the same instance type). The difference is what you get for that price: the cluster delivers faster failover (35 vs 60 seconds) and two readable standbys instead of one, but the cluster is only available for MySQL and PostgreSQL and uses a different storage topology.
When Is Multi-AZ DB Cluster Cheaper Than the Alternative?
At the same compute cost as Multi-AZ plus one read replica, Multi-AZ DB Cluster delivers one additional readable standby. For teams currently running Multi-AZ plus two separate read replicas (to distribute read load), the comparison changes meaningfully.
Multi-AZ DB Cluster versus Multi-AZ plus two read replicas: the cluster costs $0.555/hr (3 instances). Multi-AZ plus two read replicas costs $0.740/hr (4 instances: primary + standby + 2 replicas). The cluster saves $0.185/hr = $135/month = $1,620/year for the same number of readable endpoints. This is the scenario where Multi-AZ DB Cluster is genuinely cheaper: replacing a Multi-AZ deployment plus two standalone read replicas with a single managed cluster configuration.
The tradeoff: Multi-AZ DB Cluster has 2 readable standbys; Multi-AZ plus 2 replicas has 2 standalone replicas. The cluster’s standbys are synchronously replicated (zero data loss, but slightly higher write latency due to Raft consensus requiring acknowledgment from at least one standby). The standalone replicas are asynchronously replicated (lower write latency on the primary, but replicas may lag by seconds). For applications where read stale data of a few seconds is acceptable, standalone replicas may deliver better primary write performance. For applications requiring read consistency, the synchronous standbys in the cluster are more appropriate.
How Does Multi-AZ DB Cluster Billing Work?
Each node in the Multi-AZ DB Cluster is billed as a separate RDS DB instance at the individual on-demand or reserved rate for that instance type. There is no cluster-level pricing discount or surcharge. The three nodes are billed independently in Cost Explorer and the Cost and Usage Report.
Storage Billing
Each node in the Multi-AZ DB Cluster has its own storage volume, billed at the standard gp3 rate of $0.115/GB-month. Unlike Aurora, which uses a shared distributed storage layer across all nodes, RDS Multi-AZ DB Cluster nodes each maintain their own storage copy. For a cluster with 500 GB provisioned per node, you pay 3 x 500 GB x $0.115 = $172.50/month in storage charges, versus Aurora’s single shared volume at 500 GB x $0.10/GB = $50/month. This storage cost difference is one reason Aurora is often more cost-effective for workloads with multiple read replicas.
Backup Billing
Automated backups for a Multi-AZ DB Cluster are taken from one of the standby instances, which prevents I/O impact on the primary. Backup storage is charged the same as any RDS instance: free up to 100% of total provisioned cluster storage, then $0.095/GB-month for excess. The free tier applies to the sum of all three nodes’ provisioned storage: a 3-node cluster with 500 GB each has 1,500 GB of free backup storage before charges apply.
I/O Billing for Write Operations
For gp3 storage, the 3,000 IOPS baseline is included in the storage rate. For write-heavy workloads in a Multi-AZ DB Cluster, each write on the primary is synchronously replicated to both standbys before the write is acknowledged. This Raft consensus write path means that from a database engine perspective, writes complete slightly slower than on a Single-AZ instance or even a standard Multi-AZ. The I/O billing itself does not change: you pay the gp3 rate on each node’s storage volume. But the write latency is higher, which can affect throughput for I/O-bound workloads.
Also read: RDS Reserved Instances: 1-Year vs 3-Year Break-Even Across All Engines
What Is the Extended Support Cost for Multi-AZ DB Cluster?
Extended Support charges apply to all instances in a Multi-AZ DB Cluster, not just the primary. For a cluster running MySQL 5.7 or PostgreSQL 11 (both in Year 3 Extended Support since March 2026): the surcharge is $0.200 per vCPU-hour, applied to every running instance in the cluster.
For a db.m7g.large cluster (2 vCPUs each, 3 nodes): Extended Support Year 3 surcharge = 3 nodes x 2 vCPUs x $0.200/hr x 730 hrs = $876/month. This is on top of the base compute cost of $405/month. The cluster running MySQL 5.7 in Year 3 costs $405 + $876 = $1,281/month in US East, compared to $135/month for the same instance Single-AZ without Extended Support. The cluster topology multiplies the Extended Support exposure by 3x compared to a Single-AZ deployment. A standard Multi-AZ instance (2 nodes) multiplies it by 2x.
This is the most expensive billing state for RDS Multi-AZ DB Cluster. If your cluster is running an EOL engine version, upgrading to a supported version is the highest-priority cost action — even before reserved instance optimization. The Extended Support surcharge on a 3-node cluster at larger instance sizes can exceed $2,000-3,000/month for a workload that should cost $400-600/month on a current engine version.
How Do Reserved Instances Work for Multi-AZ DB Clusters?
Each node in a Multi-AZ DB Cluster is reserved independently. There is no single reservation that covers the entire cluster. To fully cover a 3-node cluster with reserved instances, you purchase 3 separate reserved instances: one for the primary and one for each standby.
The reserved instance type for each cluster node is the same as any standard RDS reservation: specify engine, instance family, Single-AZ (since each cluster node is billed as a single AZ instance), region, and payment option. The cluster nodes run as Single-AZ billing units from AWS’s cost management perspective — the Multi-AZ topology is handled at the cluster level, but each node is charged individually as a single instance.
Practical reservation strategy for a db.m7g.large MySQL Multi-AZ DB Cluster: purchase 3x db.m7g.large MySQL Single-AZ reserved instances in the cluster’s region. The discount applies to all three nodes. 3-year All Upfront: ~$0.083/hr effective per node x 3 nodes = $0.249/hr, $182/month. Compare to on-demand: $0.555/hr, $405/month. Annual RI savings: ($405 – $182) x 12 = $2,676/year.
Size flexibility applies to each individual reservation within the cluster. If you later resize the cluster nodes from db.m7g.large to db.m7g.xlarge, the large reservations partially cover the xlarge nodes via normalization units, same as any other RDS instance with size flexibility.
How Do You Connect to a Multi-AZ DB Cluster?
Multi-AZ DB Cluster provides two endpoint types that differ from standard RDS instance endpoints.
Cluster Endpoint (Writer Endpoint)
The cluster endpoint routes to the current primary instance. All write operations must use the cluster endpoint. On failover, the cluster endpoint automatically updates its DNS target to point to the new primary instance. Application connection strings pointed at the cluster endpoint automatically reconnect to the new primary after failover without any application configuration changes. This is the same behavior as Aurora’s cluster endpoint.
Reader Endpoint
The reader endpoint load-balances read connections across the two standby instances. AWS distributes incoming read connections evenly between the two standbys. Applications that want to offload reads from the primary should use the reader endpoint for read-only queries while continuing to use the cluster endpoint for writes. The reader endpoint remains stable across failover events — if a standby is promoted to primary, AWS updates the reader endpoint to route to the remaining standby instance.
Instance Endpoints
Each cluster node also has its own individual instance endpoint. These are primarily useful for diagnostic access to a specific node. For production application traffic, always use the cluster endpoint for writes and the reader endpoint for reads. Connecting directly to an instance endpoint bypasses the automatic failover routing that the cluster and reader endpoints provide.
Connection String Update Required from Standard RDS
If you are migrating an existing application from a standard RDS Multi-AZ instance to a Multi-AZ DB Cluster, you need to update your connection string from the instance endpoint to the cluster endpoint. The instance endpoint format and the cluster endpoint format are different. Applications should also be updated to use the reader endpoint for read-heavy queries to take advantage of the readable standbys.
What Are the Performance Characteristics of Multi-AZ DB Cluster vs Standard Multi-AZ?
Understanding the performance trade-offs helps determine whether the cluster is the right choice for your workload, beyond the cost comparison.
Write Latency: Cluster vs Standard Multi-AZ
Standard Multi-AZ uses synchronous page-level replication to one standby. The write is acknowledged once the primary and one standby have both written the page. Multi-AZ DB Cluster uses Raft consensus replication to two standbys. A write is acknowledged once the primary and at least one standby have acknowledged the write. In practice, this means the write must traverse the network to one additional standby before completing. Benchmarks vary by instance type, network conditions, and workload pattern, but Multi-AZ DB Cluster write latency is generally 1-3 milliseconds higher than standard Multi-AZ write latency for the same instance type. For write-intensive transactional workloads where P99 write latency matters, benchmark both configurations before committing.
Read Throughput: Cluster Advantage
Standard Multi-AZ routes all reads to the primary. Multi-AZ DB Cluster routes reads to two standby instances via the reader endpoint. For read-heavy workloads, this provides approximately 2x the read throughput available from a standard Multi-AZ deployment of the same instance size, without additional instances. For a reporting workload that generates 1,000 read queries per second alongside 100 writes per second, distributing reads across two standbys reduces primary read pressure and improves overall query latency.
Backup Performance
Multi-AZ DB Cluster backups are taken from a standby instance, preventing backup I/O from impacting the primary. Standard Multi-AZ also backs up from the standby. Single-AZ backs up from the primary and may cause brief I/O pauses during the snapshot. From a backup performance perspective, both Multi-AZ configurations behave identically — the backup runs on a non-primary instance with no primary impact.
What Are the Multi-AZ DB Cluster Limitations You Should Know?
Engine Availability: MySQL and PostgreSQL Only
Multi-AZ DB Cluster is available only for RDS for MySQL and RDS for PostgreSQL. It is not available for MariaDB, Oracle, SQL Server, or Db2. Teams running any other engine cannot use the cluster topology and must use standard Multi-AZ (one standby) for managed high availability.
Instance Type Availability: Not All Types Supported
The Multi-AZ DB Cluster is available for a subset of RDS instance types. Not all db.m7g, db.r8g, or other instance families support the cluster topology. Verify instance type availability at docs.aws.amazon.com/AmazonRDS/latest/UserGuide/multi-az-db-clusters-concepts.html before planning cluster deployments on a specific instance type. The M6gd family is commonly cited in AWS examples; M7g and R8g support is expanding but verify current availability.
Storage Write I/O Latency
The Raft consensus protocol requires that a write on the primary be acknowledged by at least one standby before the transaction is committed. This synchronous replication path adds write latency compared to a Single-AZ instance or even a standard Multi-AZ instance (which also does synchronous replication but to only one standby). For write-latency-sensitive workloads, benchmark the cluster write performance against a standard Multi-AZ before committing.
Read Replica Support
Multi-AZ DB Clusters support additional read replicas beyond the two included standbys. Each additional read replica is billed as a separate RDS instance at the same rate as the cluster nodes. If you add two more read replicas to a 3-node cluster, you are effectively running 5 instances. Evaluate whether the additional replicas are needed or whether the two standbys provide sufficient read capacity.
Also read: RDS Reserved Instances: Engine-by-Engine Pricing and Commitment Guide
Choose Multi-AZ DB Cluster When… Choose Standard Multi-AZ When…
Choose Multi-AZ DB Cluster When:
You are currently running a Multi-AZ instance plus two standalone read replicas. The cluster replaces this four-instance pattern with three instances at lower cost, with faster failover. You require failover completion in under 35 seconds for a strict SLA. Standard Multi-AZ achieves approximately 60 seconds. You want read scaling without managing standalone replica endpoints and connection strings. The cluster reader endpoint routes reads to standbys automatically. You are running MySQL or PostgreSQL (the only engines that support the cluster topology). Your workload can tolerate slightly higher write latency from the Raft consensus protocol compared to a single writer.
Choose Standard Multi-AZ (One Standby) When:
You only need failover protection and do not need read scaling from the standby. Standard Multi-AZ at 2x the single-instance cost is cheaper than the cluster at 3x. Your engine is MariaDB, Oracle, SQL Server, or Db2 — the cluster is not available. Your instance type is not available for Multi-AZ DB Cluster. Your workload is write-latency-sensitive and the Raft consensus protocol’s extra write hop adds unacceptable latency. You want 1-year or 3-year reserved instances without the complexity of purchasing separate reservations for each of three cluster nodes.
Choose Single-AZ When:
The workload is development, testing, staging, or any non-production environment. A few minutes of downtime during a failover has no business impact. Every Multi-AZ environment in development or staging is paying $270/month for availability guarantees that nobody is monitoring or acting on. Audit your RDS deployments: any instance marked Multi-AZ in a dev or test environment should be converted to Single-AZ to save $135/month per instance.
How Does Usage.ai Optimize Multi-AZ DB Cluster Costs?
Multi-AZ DB Cluster nodes are individually monitored RDS instances from a cost management perspective. Usage.ai Flex Reserved Instances treats each cluster node as a separate reservation candidate, evaluating utilization, term eligibility, and the same criteria applied to any standard RDS instance.
For a 3-node cluster, Usage.ai identifies that all three nodes have identical instance type and utilization patterns, purchases three matched reserved instances, and monitors for cluster node changes (resizing, engine version upgrades) that could affect reservation coverage. The platform refreshes analysis every 24 hours versus AWS Cost Explorer’s 72+ hour cycle, ensuring that cluster nodes created during scaling events are evaluated for reservation eligibility quickly.
Usage.ai also surfaces Extended Support charges on Multi-AZ DB Clusters, where the 3-node topology triples the monthly surcharge versus a Single-AZ instance. For clusters running EOL engine versions, the Extended Support cost alert is the highest-priority action item, showing the exact monthly amount attributable to each cluster node’s EOL version surcharge. If reservations become underutilized because a cluster is resized or deprecated, Usage.ai provides cashback and credits. The fee is a percentage of realized savings only.
See how much you can save on RDS clusters with Usage.ai
Frequently Asked Questions
What is RDS Multi-AZ DB Cluster?
RDS Multi-AZ DB Cluster is a three-instance deployment of an RDS MySQL or PostgreSQL database across three Availability Zones. One instance is the primary (accepts reads and writes). Two instances are readable standbys (serve read-only queries and act as automatic failover targets). Replication uses a Raft consensus protocol. Failover completes in under 35 seconds. Each of the three instances is billed separately at the standard on-demand or reserved rate.
How expensive is Amazon RDS Multi-AZ DB Cluster?
The Multi-AZ DB Cluster costs exactly 3x the Single-AZ instance rate for the same instance type, since all three nodes are billed individually. A db.m7g.large MySQL Single-AZ is $0.185/hr ($135/month). The same instance in a Multi-AZ DB Cluster is $0.185/hr x 3 = $0.555/hr ($405/month) in US East. Reserved instances reduce each node’s rate by 29-55%, same as any RDS instance.
What is the difference between read replicas and Multi-AZ RDS?
Standard Multi-AZ creates a synchronous standby in a second AZ for automatic failover. The standby cannot serve reads. Read replicas are separately created instances that receive asynchronous replication and can serve read queries. Multi-AZ DB Cluster combines both: three synchronously replicated instances where both standbys can serve reads and act as failover targets. Multi-AZ DB Cluster is only available for MySQL and PostgreSQL.
Is Multi-AZ DB Cluster faster for failover than standard Multi-AZ?
Yes. Standard Multi-AZ (one standby) failover completes in approximately 60 seconds. Multi-AZ DB Cluster failover completes in under 35 seconds. The improvement comes from the Raft consensus protocol, which maintains a continuously up-to-date standby state versus the page-level synchronous replication used in standard Multi-AZ. For applications with strict availability SLAs where 60 seconds of downtime is meaningful, the cluster provides a measurable improvement.
How do reserved instances work for Multi-AZ DB Clusters?
Each cluster node is reserved independently using a separate reserved instance purchase. To cover a 3-node cluster, purchase three reserved instances for the same engine, instance family, Single-AZ deployment type, and region. There is no single cluster-level reservation. All three nodes qualify for the same 29-55% savings rates as any other RDS reserved instance.
Does Multi-AZ DB Cluster support all RDS engines?
No. Multi-AZ DB Cluster is available only for RDS for MySQL and RDS for PostgreSQL. It is not available for MariaDB, Oracle, SQL Server, or Db2. Teams on those engines must use standard Multi-AZ (one standby) for managed high availability.
How does Extended Support billing work for Multi-AZ DB Clusters?
Extended Support charges apply to all three cluster nodes when the engine version is past end-of-standard-support. For a 3-node cluster on MySQL 5.7 in Year 3 (Year 3 active since March 2026): 3 nodes x 2 vCPUs each x $0.200/hr = $0.80/hr surcharge on top of compute cost. A db.m7g.large cluster pays $876/month in Extended Support alone. Upgrading to a supported engine version is the highest-priority cost action for affected clusters.
Can you add read replicas to a Multi-AZ DB Cluster?
Yes. Multi-AZ DB Clusters support additional standalone read replicas beyond the two included standbys. Each additional replica is billed as a separate RDS instance at the standard rate. Before adding replicas, evaluate whether the two existing readable standbys provide sufficient read capacity for your workload — adding replicas increases cost without improving failover capability.


