.png)


The AI Overview gets the headline right: pgvector and PostGIS are free extensions on Amazon RDS for PostgreSQL. No licensing fee, no per-query charge, no additional line item for enabling them. You run CREATE EXTENSION vector; and the extension is active. AWS does not charge more per hour because you are using vector similarity search or geospatial queries.
The cost impact is entirely indirect. These extensions change what your workload demands from the underlying RDS instance — more memory for index operations, more CPU for spatial computations, more storage for indexes that can be as large as the data they cover. On the wrong instance, pgvector queries degrade to full table scans or index builds fail partway through. On the right instance, both extensions perform at the level your application requires.
This guide covers the specific storage and memory math for pgvector HNSW indexes at common embedding dimensions, the instance sizing decision for PostGIS spatial workloads, verified 2026 pricing for the instances that actually support these workloads, and the RI purchasing strategy that applies once you have the right instance size confirmed.
See exactly what you’re overpaying in under 60 seconds. Try the Calculator for free →
pgvector on RDS: Current Version and What It Includes
Amazon RDS for PostgreSQL supports pgvector 0.8.2 as of the latest release notes (June 2026). pgvector 0.8.0 launched November 21, 2024 and is available on PostgreSQL 17.1+, 16.5+, 15.9+, 14.14+, and 13.17+. Source: AWS official announcement aws.amazon.com/about-aws/whats-new/2024/11/amazon-rds-for-postgresql-pgvector-080.
pgvector enables: storage of high-dimensional vectors (embeddings) directly in PostgreSQL tables using the vector, halfvec, and sparsevec data types. Approximate nearest neighbor (ANN) search using HNSW (Hierarchical Navigable Small World) and IVFFlat indexes. Exact nearest neighbor search without an index. Distance calculations using cosine, Euclidean (L2), and inner product metrics. Support for up to 2,000 dimensions for indexed vectors (standard vector type), up to 4,000 for halfvec, and up to 64,000 for binary vectors.
HNSW (added in pgvector 0.5.0, October 2023) is the preferred index type for production pgvector workloads because it provides fast approximate search with high recall at query time. IVFFlat requires training a clustering step before indexing and requires the full dataset to be loaded before the index is built. HNSW supports concurrent inserts and incremental updates without rebuilding the index. Source: AWS official announcements October 2023 and May 2024.
pgvectorscale is NOT available on Amazon RDS for PostgreSQL as of mid-2026. pgvectorscale (from Timescale) uses the DiskANN algorithm and provides significantly better performance and storage efficiency at scale compared to pgvector’s HNSW for very large vector datasets. Teams running more than 10 million vectors who need pgvectorscale must self-manage PostgreSQL on EC2. This is a known gap — multiple teams have filed feature requests via AWS re:Post.
The HNSW Index Storage Math: What 1 Million Vectors Actually Costs
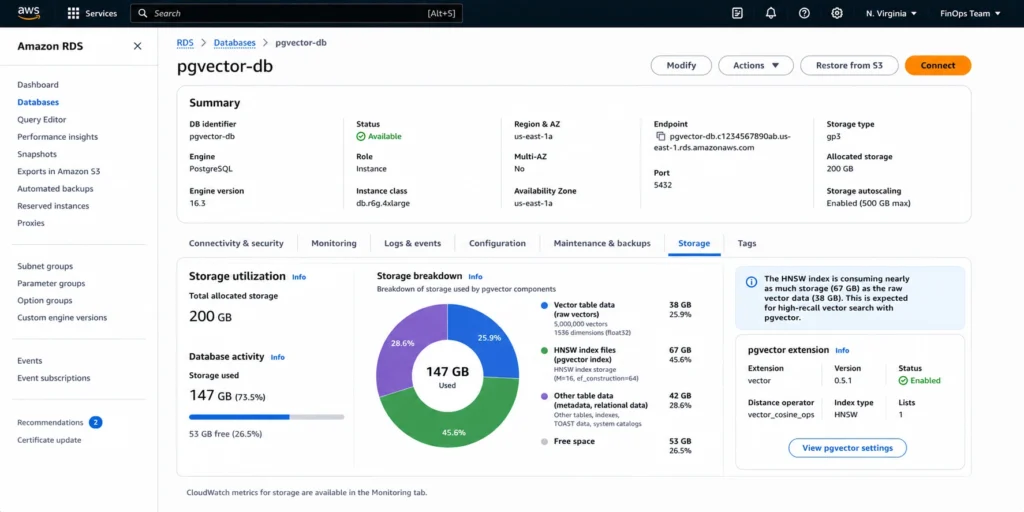
Vector storage cost is the most consistently underestimated line item for pgvector deployments. Most teams size their instance for the raw vector data and discover later that the HNSW index is as large or larger than the data itself.
Raw Vector Storage
A 1536-dimension vector (the dimension count for OpenAI ada-002 and many common embedding models) stored as the standard vector type uses 4 bytes per dimension plus 8 bytes of overhead: (1536 x 4) + 8 = 6,152 bytes, approximately 6 KB per vector.
Storage for different dataset sizes at 1536 dimensions: 100,000 vectors = 615 MB raw storage. 1 million vectors = 6.0 GB raw storage. 10 million vectors = 60 GB raw storage. 100 million vectors = 600 GB raw storage. These are raw data sizes only, before index overhead.
HNSW Index Size
HNSW indexes in pgvector are typically 1.5x to 2x the raw vector data size depending on the m parameter (number of connections per node, default 16) and ef_construction parameter (construction search size, default 64). With default parameters at 1536 dimensions: 1 million vectors generates approximately 9-12 GB of HNSW index storage on top of the 6 GB of raw data. Total storage for 1 million 1536-dim vectors: approximately 15-18 GB.
halfvec reduces storage: using halfvec (2-byte floats instead of 4-byte) cuts raw vector storage in half — approximately 3 KB per 1536-dim vector. halfvec with HNSW reduces total storage for 1 million vectors to approximately 7-9 GB. The trade-off is slight reduction in precision for distance calculations, acceptable for most semantic search applications. Source: pgvector 0.7.0 release notes (AWS official, May 2024).
All rates: gp3 storage at $0.115/GB-month. 15 GB of vectors + index = $1.73/month in storage charges. 150 GB (10 million vectors) = $17.25/month. 1.5 TB (100 million vectors) = $172.50/month. For most teams the storage cost is secondary to the instance compute cost — the instance needs enough memory to keep the HNSW index in shared_buffers for fast queries. Verify at aws.amazon.com/rds/postgresql/pricing — rates change.
Memory Requirements: Why pgvector Forces r-Family Instances
pgvector query performance depends critically on whether the HNSW index fits in shared_buffers (the PostgreSQL shared memory cache). When the index fits in memory, ANN queries return in single-digit milliseconds. When the index does not fit, queries require disk reads for each HNSW graph traversal, and latency degrades to hundreds of milliseconds or worse.
shared_buffers and work_mem
Amazon RDS sets shared_buffers to 25% of the instance’s RAM by default. For a db.r8g.xlarge (32 GB RAM), shared_buffers = 8 GB. For a db.r8g.2xlarge (64 GB RAM), shared_buffers = 16 GB. An HNSW index for 1 million 1536-dim vectors at ~10 GB does not fit in the 8 GB shared_buffers of a db.r8g.xlarge. It fits in the 16 GB shared_buffers of a db.r8g.2xlarge.
work_mem controls the per-operation memory allocation for sort operations, hash joins, and — critically for pgvector — HNSW index builds. Building an HNSW index for 1 million 1536-dim vectors with default work_mem (4 MB on RDS) causes the build to read pages repeatedly from disk, making the index build 10-20x slower than with sufficient memory. The recommended work_mem for HNSW builds with 1536-dim vectors: at minimum 64 MB, ideally 256 MB per worker. Setting work_mem higher consumes memory per active connection — on a busy instance with 100 concurrent connections, 256 MB work_mem = 25.6 GB RAM allocated to active sorts before other operations. Size the instance accordingly.
The practical rule for production pgvector workloads: the instance RAM should be at least 2x the HNSW index size to allow both index caching in shared_buffers and sufficient work_mem for index builds and query execution. For 1 million 1536-dim vectors (~12 GB HNSW index): minimum 32 GB RAM. For 10 million vectors (~120 GB HNSW index): minimum 256 GB RAM. Source: AWS Database Blog (HNSW acceleration guide) and pgvector GitHub documentation.
Graviton3 Instances for pgvector Workloads
AWS benchmarks confirm that Graviton3 instances (db.r8g family) outperform Graviton2 (db.r6g family) for 1536-dimension HNSW workloads at high concurrency. Specifically: Graviton3 delivers 60% better throughput than Graviton2 for 1536-dim vector searches at 64 concurrent clients. For pgvector production deployments, db.r8g instances are the recommended choice over db.r6g. The Graviton3 advantage is specific to HNSW search performance — Graviton3 provides hardware-accelerated SIMD (Single Instruction Multiple Data) operations that benefit distance computation. Source: AWS Database Blog (pgvector HNSW acceleration benchmark, November 2023).
Verified Instance Pricing for pgvector Workloads (US East, May 2026)
| Instance | RAM | On-Demand/hr | 1-yr RI/hr | Annual saving | Max HNSW vectors (1536-dim) |
| db.r8g.large | 16 GB | $0.273 | ~$0.183 | ~$789 | ~500K (tight) |
| db.r8g.xlarge | 32 GB | $0.546 | ~$0.366 | ~$1,578 | ~1M (comfortable) |
| db.r8g.2xlarge | 64 GB | $1.093 | ~$0.732 | ~$3,155 | ~5M (comfortable) |
| db.r8g.4xlarge | 128 GB | $2.186 | ~$1.465 | ~$6,310 | ~10M (comfortable) |
| db.r8g.8xlarge | 256 GB | $4.368 | ~$2.927 | ~$12,600 | ~25M (comfortable) |
All rates from Vantage.sh (AWS API, May 2026) and AWS official pricing. Verify at aws.amazon.com/rds/postgresql/pricing — rates change.
HNSW vector capacity estimates based on 2x RAM rule (HNSW index size ~12 KB/vector at 1536 dims; index should fit in shared_buffers which is 25% of RAM). ‘Comfortable’ means index fits in shared_buffers with headroom for work_mem. Annual saving = (on-demand minus RI rate) x 8,760 hours. RI discount approximately 33% at 1-year No Upfront, consistent with r8g MySQL verified rates from prior research. Verify exact rates at aws.amazon.com/rds/postgresql/pricing.
The right-sizing trap: teams frequently start with db.r8g.xlarge (32 GB, $0.546/hr) and then find that as their vector dataset grows past 2 million embeddings, query latency degrades because the HNSW index no longer fits in shared_buffers. The correct approach: size for 2x your current vector count to account for index growth during the instance’s RI term. Buying a 1-year RI on an instance that will need resizing in 6 months creates waste for the remaining 6 months. Source: AWS Database Blog HNSW benchmark (November 2023), size flexibility applies to PostgreSQL BYOL RIs only for exact-size LI — but PostgreSQL has no License Included model, so size flexibility always applies.
Also read: RDS Reserved Instances: complete guide — includes PostgreSQL RI strategy
PostGIS on RDS: What It Costs and Why Spatial Queries Are Different
PostGIS is also a free extension — no additional licensing fee when you enable it on an RDS PostgreSQL instance. The cost model is the same as pgvector: you pay for the instance and storage that the spatial workload demands.
How PostGIS Differs From pgvector in Resource Profile
pgvector is primarily memory-bound. The HNSW index needs to fit in RAM for fast queries, and index builds are memory-intensive. Once the index is loaded, query CPU usage is moderate.
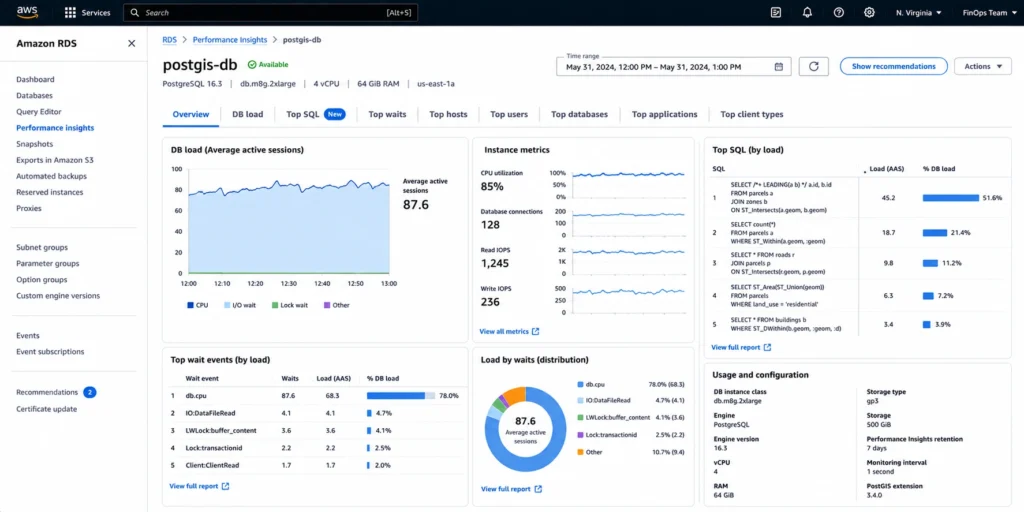
PostGIS is primarily CPU-bound for complex spatial queries. Simple point-in-polygon lookups are fast on any instance. Complex operations — polygon intersection across large datasets, buffer generation, spatial joins with ST_Within or ST_Intersects on tables with millions of geometries — are CPU-intensive and benefit from instances with higher core counts. A 16-vCPU instance handles complex spatial queries significantly faster than a 4-vCPU instance for the same RAM footprint.
PostGIS spatial data storage: geometries are stored as binary objects. A simple point (lat/lng) takes approximately 32 bytes. A complex polygon boundary with hundreds of vertices can take 1-10 KB per row. For datasets with millions of geometries, storage costs are driven by geometry complexity. A table with 10 million simple points: approximately 300 MB. A table with 1 million complex polygons (US Census boundaries, zoning data): 1-10 GB.
The PostGIS Raster Extension
Starting with PostGIS 3.0, raster functionality was moved to a separate extension: postgis_raster. If your workload involves raster image processing — satellite imagery, elevation data, grid-based spatial analysis — you need to install both PostGIS and postgis_raster. Both are free on RDS. Raster storage can be significant: a single high-resolution satellite image tile can be 1-10 MB, and datasets of thousands of tiles add up quickly in gp3 storage charges at $0.115/GB-month. Source: AWS RDS PostGIS documentation (docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Appendix.PostgreSQL.CommonDBATasks.PostGIS.html).
h3-pg: Hexagonal Geospatial Indexing
AWS added h3-pg (the H3 hexagonal geospatial indexing system) to RDS PostgreSQL in September 2023. h3-pg works alongside PostGIS for hexagonal grid analysis — retail site selection, mobility heatmaps, geospatial ML preprocessing. Like PostGIS, h3-pg is free to enable. It adds minimal storage overhead (hexagonal cell IDs are fixed-size 64-bit integers) but adds CPU usage for conversion and lookup operations. Source: AWS official announcement, September 2023.
pgvector vs PostGIS: Instance Family Selection
The resource profiles of the two extensions point to different optimal instance selections.
| Factor | pgvector (HNSW) | PostGIS (complex spatial) | Both together |
| Primary bottleneck | Memory (index in RAM) | CPU (polygon operations) | Memory + CPU |
| Recommended family | r8g (8 GB/vCPU, Graviton3) | m8g (4 GB/vCPU, more cores) | r8g (balance memory + CPU) |
| Key parameter | shared_buffers (fit HNSW in RAM) | vCPU count (parallel spatial ops) | Both |
| Scale trigger | Vector count grows past index-in-memory threshold | Concurrent spatial query CPU > 70% | Either threshold hit |
| Storage driver | HNSW index (1.5-2x raw vector size) | Geometry complexity per row | Both independent |
| Extension fee | $0 | $0 | $0 |
Source: AWS Database Blog (HNSW benchmark November 2023), AWS RDS PostGIS documentation. Instance families verified against Vantage.sh (May 2026). Note: a single RDS instance can run both pgvector and PostGIS simultaneously — both extensions co-exist without conflict. If using both, size for the more demanding workload (usually pgvector’s memory requirement exceeds PostGIS’s CPU requirement unless the spatial dataset is very large).
Enabling pgvector and PostGIS: The Commands and Parameter Considerations
Enabling pgvector
Enable the extension in any database: CREATE EXTENSION IF NOT EXISTS vector;
Create a table with a vector column: CREATE TABLE documents (id BIGSERIAL PRIMARY KEY, content TEXT, embedding vector(1536));
Create an HNSW index: CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64);
The m and ef_construction parameters control index quality and build time. Higher m (connections per node) improves recall at the cost of larger index size and slower build. Higher ef_construction improves index quality at the cost of slower builds. Default values (m=16, ef_construction=64) are appropriate for most production workloads. Source: pgvector GitHub repository (April 2026).
Enabling PostGIS
Enable the core extension: CREATE EXTENSION IF NOT EXISTS postgis;
If raster processing is required: CREATE EXTENSION IF NOT EXISTS postgis_raster;
For hexagonal geospatial indexing: CREATE EXTENSION IF NOT EXISTS h3;
To check available PostGIS versions: SELECT * FROM pg_available_extension_versions WHERE name = ‘postgis’ ORDER BY version DESC;
The work_mem Parameter for HNSW Index Builds
Before building a large HNSW index, set work_mem for the session: SET work_mem = ‘256MB’; This setting applies to the current session only and reverts when the connection closes. For index builds on large vector datasets (1 million+ vectors), this setting can reduce build time from hours to minutes. Do not set work_mem globally to 256 MB on a busy instance — this multiplies by concurrent connection count and can cause OOM (out of memory) conditions. Set it at session level immediately before the index creation command. Source: AWS Database Blog and pgvector documentation.
See how Usage.ai handles PostgreSQL RI optimization for AI and spatial workloads
RDS Reserved Instances for pgvector and PostGIS Workloads
pgvector and PostGIS workloads are particularly well-suited for Reserved Instances because both extension use cases tend to be stable: vector search for a production AI application does not typically change instance families month to month, and PostGIS spatial data pipelines are generally steady-state.
The RI strategy for PostgreSQL instances running these extensions follows the same rules as all RDS PostgreSQL RIs: size-flexible, Single-AZ RI at the smallest size in the target family. A db.r8g.xlarge RI covers two db.r8g.large instances or 50% of a db.r8g.2xlarge via normalization units. Source: AWS official RDS RI documentation.
The critical sizing caution for pgvector specifically: purchase the RI after confirming the instance size is correct for your current and near-term projected vector dataset size. A 1-year RI on a db.r8g.xlarge that needs to be replaced by a db.r8g.2xlarge in 6 months leaves you with a mismatched RI for the remaining 6 months. Because PostgreSQL RIs are size-flexible, the orphaned xlarge RI will partially cover the 2xlarge at 50% normalization — not ideal, but not completely wasted. Run the workload for 30 days with a realistic production vector load before purchasing any RI.
Savings at 1-year No Upfront for the production pgvector instance sizes: db.r8g.2xlarge saves approximately $3,155/year versus on-demand. db.r8g.4xlarge saves approximately $6,310/year. For an AI application running production vector search at scale, the RI saving often exceeds $5,000/year on the compute alone — before accounting for storage and I/O optimization. Rates verified from Vantage.sh (AWS API, May 2026). Verify at aws.amazon.com/rds/postgresql/pricing — rates change.
Usage.ai Insured Flex Commitments for RDS PostgreSQL instances apply to pgvector and PostGIS workloads identically to any other PostgreSQL instance. The platform identifies the correct instance size based on 30-day utilization analysis, purchases the RI automatically, and provides cashback if the instance is later resized or decommissioned. For teams scaling vector datasets rapidly, the 24-hour recommendation refresh catches when a scale-up is needed and updates the RI recommendation before the next purchase decision. Fee: percentage of realized savings only.
See exactly what you’re overpaying in under 60 seconds. Try the Calculator for free →

Frequently Asked Questions
1. Are pgvector and PostGIS free on Amazon RDS?
Yes. Both pgvector and PostGIS are open-source PostgreSQL extensions that AWS includes in RDS for PostgreSQL at no additional charge. There is no licensing fee, no per-query cost, and no extra hourly charge for enabling them. You pay only for the standard RDS PostgreSQL instance, storage, and I/O that your workload consumes. The cost impact of these extensions is indirect — they change what your workload demands from the instance, typically requiring larger memory-optimized instances.
2. How much storage does a pgvector HNSW index use?
At 1536 dimensions (standard for OpenAI ada-002 embeddings): approximately 6 KB per vector for raw storage, plus HNSW index overhead of 1.5x to 2x the raw data size with default parameters (m=16, ef_construction=64). One million 1536-dim vectors: approximately 6 GB raw + 9-12 GB HNSW index = 15-18 GB total. gp3 storage at $0.115/GB-month: approximately $1.73-$2.07/month per million vectors. Storage cost is typically dwarfed by the compute cost of the instance required to hold the index in memory. Verify at aws.amazon.com/rds/pricing.
3. Which RDS instance is recommended for pgvector?
Graviton3 r-family instances (db.r8g) are recommended for pgvector production workloads. AWS benchmarks confirm 60% better throughput on Graviton3 versus Graviton2 for 1536-dimension HNSW searches at high concurrency. For 1 million vectors, db.r8g.xlarge (32 GB RAM, $0.546/hr) is the minimum practical instance. For 5 million vectors, db.r8g.2xlarge (64 GB RAM, $1.093/hr). The HNSW index should fit in shared_buffers (25% of RAM) for fast queries. Source: AWS Database Blog November 2023, Vantage.sh May 2026.
4. What version of pgvector does RDS support?
Amazon RDS for PostgreSQL supports pgvector 0.8.2 as of June 2026. pgvector 0.8.0 (released November 2024) added improved filtering with WHERE clauses, iterative index scans to prevent overfiltering, and HNSW performance improvements. Available on PostgreSQL 17.1+, 16.5+, 15.9+, 14.14+, and 13.17+. pgvectorscale is not available on RDS as of mid-2026 — teams needing DiskANN for very large datasets must self-manage PostgreSQL on EC2. Source: AWS official release notes.
5. Does pgvector work with Amazon Bedrock and SageMaker embeddings?
Yes. pgvector on RDS stores embedding vectors generated by any source including Amazon Bedrock foundation models, Amazon SageMaker endpoints, OpenAI API, Cohere, and any other service that produces numerical vector representations. The extension stores and indexes the numerical arrays regardless of which model generated them. AWS explicitly supports Bedrock and SageMaker integration with pgvector in the RDS documentation and Database Blog.
6. How does PostGIS affect my RDS instance sizing?
PostGIS is CPU-intensive for complex spatial operations (polygon intersections, spatial joins, buffer generation) rather than memory-intensive. Simple point lookups require minimal resources. Complex polygon operations on large datasets can push CPU utilization to 80-100% on smaller instances. For CPU-intensive PostGIS workloads, m-family instances (db.m8g, db.m7g) provide more vCPUs per dollar than r-family. For mixed pgvector and PostGIS workloads, r-family instances balance memory and CPU. Monitor CPU utilization in CloudWatch — if spatial queries consistently drive CPU above 70% P95, consider scaling up vCPU count.
7. What is the work_mem parameter and why does it matter for pgvector?
work_mem is a PostgreSQL parameter controlling the per-operation memory for sort and hash operations including HNSW index builds. RDS sets the default to 4 MB. Building an HNSW index for 1 million 1536-dim vectors with 4 MB work_mem causes the build to repeatedly read pages from disk, making it 10-20x slower than with sufficient memory. Set work_mem at session level before building: SET work_mem = ‘256MB’; This only affects the current session and reverts on disconnect. Do not set work_mem globally at 256 MB on multi-user instances — it multiplies by concurrent connections and can exhaust instance RAM.
8. Can I run pgvector and PostGIS on the same RDS instance?
Yes. Both extensions co-exist on a single RDS PostgreSQL instance without conflict. Enable both: CREATE EXTENSION IF NOT EXISTS vector; CREATE EXTENSION IF NOT EXISTS postgis; Each extension operates independently. For mixed workloads, size the instance for the more demanding requirement — typically the pgvector memory requirement (fitting the HNSW index in shared_buffers) rather than the PostGIS CPU requirement, unless the spatial dataset is very large or spatial queries run at high concurrency.


