.png)


Redshift Concurrency Scaling is one of those features that teams either forget to think about until they see it on a bill, or never enable because they are not sure what it will cost. Neither situation is great. If your cluster is under concurrent query pressure and you don’t have Concurrency Scaling configured, queries queue and users complain. If you have it enabled but you don’t understand the credit mechanics or the billing caps, costs appear on your invoice in ways you didn’t expect.
This guide covers how Concurrency Scaling pricing actually works from the ground up: the free credit model, the exact billing mechanics when credits run out, the two separate control mechanisms you should know about, and the scenarios where the feature earns its place versus where alternatives might be better. It also covers the write operation support that most guides still don’t mention, because the feature is no longer read-only.
%2013%20(6).svg)
What Concurrency Scaling Does
When your main Redshift cluster is under load and a new query arrives, Redshift puts that query in a WLM (Workload Management) queue. If the queue fills up, queries wait. Under high concurrency, this waiting becomes the primary user experience: dashboards take 30 seconds instead of 3, analysts wait for reports, and data pipelines pile up behind each other.
Concurrency Scaling solves this by adding transient compute clusters automatically when the main cluster queue reaches capacity. Eligible queries are routed to these temporary clusters and run there in parallel. Users see the most current data regardless of whether their query runs on the main cluster or a transient one. When the load subsides and the transient clusters finish their active queries, they shut down — you are not charged for idle transient capacity.
The key phrase is eligible queries. Not every query can be sent to a Concurrency Scaling cluster, and the eligibility rules matter for planning. We’ll cover those in detail further down.
Where Concurrency Scaling runs
Concurrency Scaling is available on provisioned Redshift clusters running on supported node types: dc2.8xlarge, dc2.large, rg.xlarge, rg.4xlarge, ra3.large, ra3.xlplus, ra3.4xlarge, and ra3.16xlarge. The cluster must be on the EC2-VPC platform, and the maximum cluster size is 32 compute nodes for RG and RA3 node types. There is also a constraint on original cluster creation size: a cluster currently running 20 nodes that was originally created at 40 nodes does not qualify, even though its current node count is under 32. Source: AWS official Concurrency Scaling documentation.
Concurrency Scaling is also available in specific AWS Regions. If you do not see Concurrency Scaling options in your Redshift console, verify that your cluster’s region is on the supported list at docs.aws.amazon.com/redshift/latest/dg/concurrency-scaling.html.
For Redshift Serverless: Concurrency Scaling is included at no additional charge and operates automatically as part of Serverless’ managed compute model. The credit and billing mechanics described in this guide apply only to provisioned Redshift clusters.
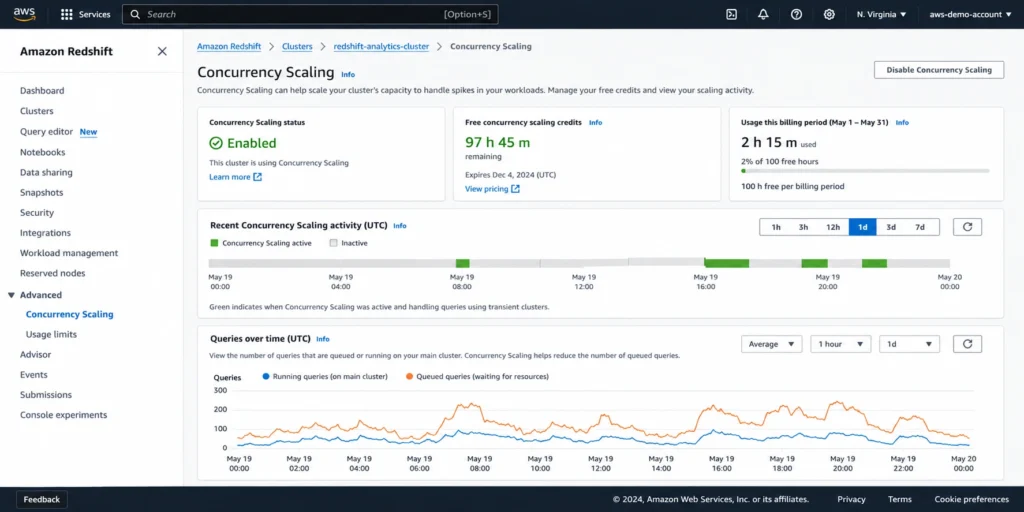
The Free Credit Model
Every active provisioned Redshift cluster earns one hour of free Concurrency Scaling credit per day. Credits are earned on an hourly basis as the cluster runs. You can accumulate up to 30 hours of free Concurrency Scaling credits per cluster. Credits do not expire as long as the cluster is not terminated — if you pause and resume a cluster, credits survive. Only terminating the cluster zeros out the balance. Source: aws.amazon.com/redshift/pricing/ DIRECT QUOTE.
AWS states this free credit tier is sufficient for 97% of customers. For the vast majority of Redshift deployments, Concurrency Scaling never generates a charge because the free daily credit absorbs all burst activity.
How credit accrual and consumption work
Credits are earned per active cluster and can only be consumed by the same cluster that earned them. If you have multiple Redshift clusters in your account, each earns and spends its own separate credit balance. You cannot pool credits across clusters or transfer them to another cluster.
The credit accrual rate is one hour per 24 hours of cluster runtime. If your cluster runs continuously, you earn 1 hour per day and can accumulate up to 30 hours. At 30 hours, additional earned credits are not added — the balance caps there. If your cluster runs for 30+ consecutive days, you enter steady state: 1 hour earned per day, credits consumed as Concurrency Scaling usage occurs.
Credits are consumed first before any paid billing kicks in. When your cluster triggers Concurrency Scaling, the system draws from the free credit balance. Only after the credit balance reaches zero does per-second billing begin for that cluster.
A common misconception: the 30-hour credit cap does not mean you get 30 hours of free Concurrency Scaling per day. It means the maximum bank you can accumulate over time is 30 hours. You earn at most 1 hour per day. If you never use Concurrency Scaling, your balance builds from 0 to 30 hours over 30 days and then stops accruing. Once you start using the feature, you draw from that balance before hitting paid usage.
Also read: Redshift Reserved Nodes: The Complete Guide to Dode Types, Pricing, and Purchase Strategy
Billing When Free Credits Run Out
Beyond the free credit balance, Concurrency Scaling billing is per-second at the same on-demand rate as your main cluster. The rate mirrors your cluster’s actual configuration: if your main cluster type and node count generate an on-demand rate of $X per hour, Concurrency Scaling charges at $X divided by 3600 per second for each transient cluster that is actively running queries.
The worked example from AWS
AWS’s official pricing page provides this worked example: a 10-node rg.4xlarge cluster in US West (N. California) runs at $33.66 per hour on-demand. If two transient concurrency-scaling clusters are active for 5 minutes beyond the free credit balance, the per-second rate is $33.66 divided by 3600, which equals $0.00935 per second. Two clusters for 300 seconds at that rate: $0.00935 times 300 times 2 = $5.61 in Concurrency Scaling charges. The total cluster cost for that hour becomes $39.27 instead of $33.66.
The math scales linearly with cluster cost. A smaller, cheaper cluster running concurrent scaling incurs proportionally smaller burst charges. A larger, more expensive cluster generates higher burst charges for the same duration of excess Concurrency Scaling.
Billing only while actively running queries
An important billing nuance: you are charged only when transient concurrency-scaling clusters are actively running queries. When those clusters are idle — waiting for queries to arrive, starting up, or cooling down — there is no charge. This is genuinely different from paying for permanently provisioned capacity, where you pay whether or not queries are running.
The implication: even if you run past your free credit balance, a workload pattern where Concurrency Scaling clusters spin up briefly for intense bursts and then go idle costs far less than the hourly rate might suggest. The per-second billing accurately reflects actual computational work performed, not just capacity reserved.
The Two Control Mechanisms
Most teams either over-restrict Concurrency Scaling through misunderstanding (setting max_concurrency_scaling_clusters too low and not gaining full benefit) or under-restrict it (leaving usage limits unset and being surprised when a heavy workload burns through the credit bank and generates unexpected charges). Understanding both control mechanisms and setting them intentionally is the right posture.
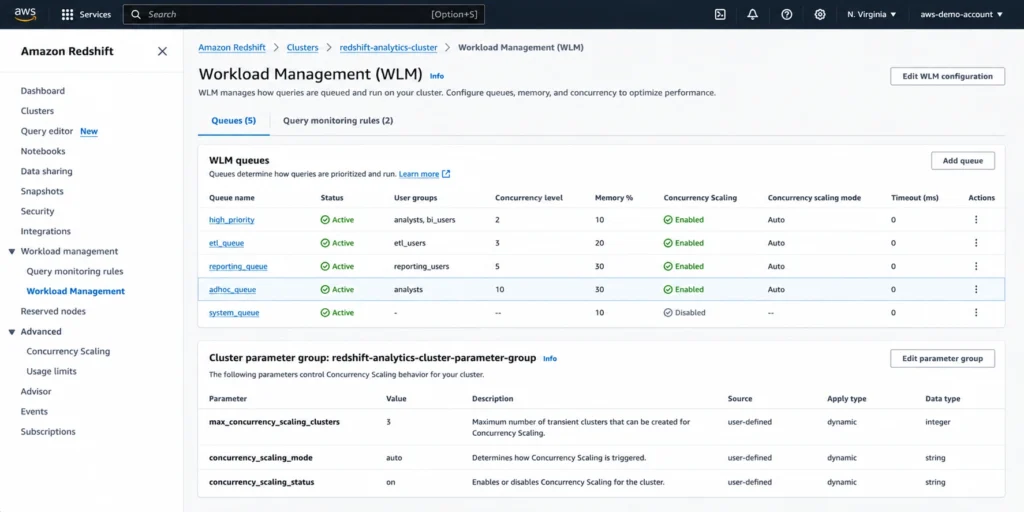
max_concurrency_scaling_clusters: the cluster count cap
This is a database parameter that sets the maximum number of transient clusters allowed to be active simultaneously when Concurrency Scaling is enabled. The default is 1. The maximum is an adjustable quota that you can increase by requesting a limit increase through AWS. AWS documentation recommends increasing this value if your workload requires more Concurrency Scaling and decreasing it to reduce usage and resulting billing charges. Source: docs.aws.amazon.com/redshift/latest/dg/r_max_concurrency_scaling_clusters.html.
Setting this too low is a common mistake. If your cluster has 5 WLM queues all experiencing concurrent load simultaneously and max_concurrency_scaling_clusters is set to 1, only one queue gets a transient cluster. The other four queues still queue up. You have Concurrency Scaling ‘enabled’ but it is only solving one fifth of the problem.
Setting this too high without other controls can cause unexpected costs if a workload pattern triggers many simultaneous transient clusters, each consuming credits (or generating charges if credits are exhausted) at the same time. The right value depends on your queue configuration and how many queues are likely to experience simultaneous pressure.
Usage limits: the time-based billing cap
Usage limits are a separate control mechanism that lets you set a cap on total Concurrency Scaling time consumed in a given period. A concurrency scaling usage limit specifies the threshold of total Concurrency Scaling time in 1-minute increments. The period can be daily, weekly, or monthly (UTC calendar). If you create a usage limit in the middle of a period, measurement begins from that point to the end of the period. Source: docs.aws.amazon.com/redshift/latest/mgmt/managing-cluster-usage-limits.html.
When a usage limit threshold is reached, you can configure one of two actions. The alert action sends an SNS notification (and optionally creates a CloudWatch event) but continues allowing Concurrency Scaling to run. The disable action stops Concurrency Scaling for the remainder of the period when the threshold is hit. The right choice depends on your use case: if you want visibility into heavy burst usage without stopping the feature, use alert. If you want a hard cap to prevent charges beyond a specific budget, use disable.
Usage limits are not set by default. AWS does not apply automatic spending caps on Concurrency Scaling. If you want a cap, you need to create it explicitly in the AWS console or via the CLI using the CreateUsageLimit API. This is one of the most commonly overlooked configuration steps for teams that enable Concurrency Scaling and then discover unexpected charges.
The practical combination for most teams: set max_concurrency_scaling_clusters to match the number of WLM queues that might experience simultaneous load (typically 2-5 for production clusters), and set a monthly usage limit with alert action at 200% of your expected monthly Concurrency Scaling usage to catch anomalies without disabling the feature during a genuine peak. If you have strict budget constraints, use the disable action instead of alert. If you are unsure what your expected monthly usage is, run for 30 days with alert only, observe the CloudWatch metrics, then set the limit based on observed patterns.
What Can and Cannot Use Concurrency Scaling
Concurrency Scaling was historically read-only. It now supports both read and write operations, but with important node type and statement type restrictions.
Supported read operations
Standard SELECT queries, including complex joins and aggregations, are routed to concurrency-scaling clusters when eligible. Users see the most current data regardless of whether their query runs on the main cluster or a transient one, because Redshift maintains transactional consistency across the cluster set.
There are notable exclusions from read-side eligibility. Queries on tables using interleaved sort keys cannot be routed to concurrency-scaling clusters. Queries on temporary tables are excluded. Queries accessing system tables, PostgreSQL catalog tables, or no-backup tables cannot scale out. Queries containing Python UDFs or Lambda UDFs are excluded. Queries accessing external resources protected by restrictive network or VPC configurations are excluded. Source: docs.aws.amazon.com/redshift/latest/dg/concurrency-scaling.html DIRECT.
Supported write operations (RG and RA3 only)
Write operation support is the newer capability that most Concurrency Scaling documentation still underrepresents. The supported write statements for concurrency scaling are: COPY, INSERT, DELETE, UPDATE, CREATE TABLE AS (CTAS), and VACUUM. Additionally, manual refresh of materialized views and automatic vacuum operations are supported. Source: docs.aws.amazon.com/redshift/latest/dg/concurrency-scaling.html DIRECT.
Write Concurrency Scaling is specifically supported only on RG and RA3 nodes. DC2 nodes do not get write concurrency scaling. If you are running heavy concurrent ETL and ingest workloads on a DC2 cluster that is experiencing queue pressure on write operations, write concurrency scaling is not available to you — this is one of the practical migration incentives toward RG or RA3.
Write Concurrency Scaling has additional exclusions. Most DDL operations are not supported (only CREATE TABLE AS is supported, not CREATE TABLE without AS). ANALYZE for COPY commands is excluded. Write operations on tables with DISTSTYLE ALL are excluded. Write operations on tables with identity columns are excluded. When non-supported write statements are included in an explicit transaction before supported ones, none of the write statements in that transaction will run on concurrency-scaling clusters. Source: AWS official documentation.
The credit accrual mechanism applies equally to both read and write concurrency scaling. A cluster earning 1 hour of credits per day can use those credits for both read and write transient cluster time.
Also read: Redshift Reserved Nodes 1-Year vs 3-Year: The Commitment Analysis
Configuring Concurrency Scaling on WLM Queues
Concurrency Scaling does not activate simply by being available for your cluster type. You need to enable it on WLM queues explicitly. The Concurrency Scaling mode per queue can be set to auto (Redshift decides when to use Concurrency Scaling based on queue depth) or off (Concurrency Scaling is disabled for that queue regardless of load).
In automatic WLM mode, Redshift manages concurrency and memory dynamically. You can enable Concurrency Scaling at the cluster level in auto WLM. In manual WLM mode, you configure queues explicitly and set Concurrency Scaling on a per-queue basis. Source: AWS official WLM documentation.
A practical configuration question is which queues to enable for concurrency scaling. The queues with the most variable load — typically user-facing dashboard queues and ad-hoc query queues — benefit most from the feature because they are most likely to see burst pressure. Long-running ETL queues with few concurrent jobs are less likely to benefit and enabling Concurrency Scaling for them may generate transient cluster usage for cases where simply waiting would have been fine.
Monitoring Concurrency Scaling Activity
AWS provides several mechanisms for monitoring how Concurrency Scaling is being used.
The Redshift console includes a Concurrency Scaling view that shows the current credit balance, recent transient cluster activity, and the queued versus running query graph. This is the fastest way to check whether Concurrency Scaling is actually being triggered in your cluster.
CloudWatch metrics for Redshift include concurrency scaling-specific metrics. The concurrency scaling cluster count metric shows how many transient clusters are active at any given time. The queued query count and queue wait time metrics can surface whether Concurrency Scaling is actually resolving queue pressure or whether queries are still waiting despite transient clusters being active.
System views in Redshift provide query-level granularity. The STL_QUERY system view records which cluster (main or transient) processed each query. The SVL_QLOG view includes concurrency scaling cluster activity. These views are useful for understanding which queries are being routed to concurrency-scaling clusters and whether the routing is behaving as expected given your WLM configuration.
For usage limit monitoring specifically, the CreateUsageLimit API and the DescribeUsageLimits API allow you to manage and review configured limits programmatically. CloudWatch events can be triggered when usage limits are breached, allowing integration with existing alerting workflows.
Concurrency Scaling vs Elastic Resize vs Reserved Nodes
Understanding where Concurrency Scaling fits in the broader Redshift cost and performance toolkit requires comparing it against the other mechanisms for handling load.
Concurrency Scaling vs Elastic Resize
Elastic Resize changes the permanent node count of your main cluster. It is a minutes-long operation that temporarily disconnects users (for Classic Resize) or operates with minimal disruption (for Elastic Resize on supported node types). It is appropriate when your baseline query processing needs have grown and the main cluster is consistently under-resourced, not just under burst load.
Concurrency Scaling is appropriate when load spikes are episodic — predictable daily peaks, reporting windows, end-of-month processing — rather than a persistent state. If your cluster is consistently saturated throughout the business day and Concurrency Scaling is running continuously to keep up with normal load, that is a signal that permanent cluster capacity needs to grow, not that you need more Concurrency Scaling budget.
The practical test: if Concurrency Scaling is running more than your free credit balance allows on a typical day, your main cluster is probably permanently under-provisioned. The on-demand charges from sustained Concurrency Scaling usage will likely exceed the cost of adding reserved nodes to the main cluster.
Concurrency Scaling and reserved nodes together
Reserved nodes reduce the hourly rate of your main cluster. They have no direct effect on Concurrency Scaling rates — Concurrency Scaling billing is always based on the on-demand rate of your cluster’s node type, regardless of whether the main cluster runs on reserved or on-demand nodes. Source: AWS pricing documentation.
This means that buying reserved nodes for your main cluster does not make Concurrency Scaling cheaper. It makes the main cluster cheaper. The burst compute you use beyond the free credit balance is always billed at on-demand. This is a meaningful distinction for cost modeling: if your cluster is on 3-year reserved nodes at 60% off on-demand, your Concurrency Scaling burst charges still run at the full on-demand rate.
For clusters with significant, predictable Concurrency Scaling usage beyond the free tier, the cost model comparison is: how much does it cost to run Concurrency Scaling for the burst period at on-demand rates versus how much would it cost to have that capacity permanently available at reserved node rates? If burst periods are short and infrequent, Concurrency Scaling wins. If burst periods are long or frequent, adding permanently reserved nodes is often cheaper.
Redshift Serverless and Concurrency Scaling
If you are evaluating Redshift Serverless as an alternative to provisioned clusters, one of its relevant cost characteristics is that Concurrency Scaling is included at no additional charge. Serverless automatically manages capacity by scaling up or down as query load changes, and the same RPU-based billing applies whether the cluster is handling 1 query or 1,000 concurrent queries. Spectrum is also included at no additional charge for Serverless. Source: aws.amazon.com/redshift/pricing/.
This is one of the meaningful cost differences between provisioned and Serverless architectures for high-concurrency workloads. On provisioned clusters, Concurrency Scaling beyond the free tier is a variable cost that requires active monitoring and control. On Serverless, concurrent load simply increases RPU consumption, which is predictable and metered the same way as all other Serverless usage.
For teams currently seeing significant Concurrency Scaling charges on provisioned clusters, the comparison between continuing to manage Concurrency Scaling on provisioned nodes (with reserved node discounts plus variable burst charges) versus migrating to Serverless (with flat RPU-based pricing) is worth modeling with the AWS Pricing Calculator using your actual usage data.
How Usage.ai Fits Into Redshift Cost Management
Concurrency Scaling charges are a variable cost layer that sits on top of your base provisioned cluster charges. Usage.ai handles the base provisioned cluster layer — the reserved node purchasing and management that determines your hourly compute rate for the main cluster.
By ensuring your main cluster has the right reserved node coverage, Usage.ai directly reduces the on-demand rate that Concurrency Scaling burst charges are calculated against. If your cluster’s on-demand hourly rate drops from $33.66 to $20.00 through reserved node coverage, every second of paid Concurrency Scaling becomes proportionally cheaper. The two levers are independent but complementary.
Usage.ai also monitors overall Redshift spend patterns and can surface signals that Concurrency Scaling is being used excessively relative to reserved capacity — the pattern that suggests permanent cluster growth is a better solution than ongoing burst billing. If a cluster’s Concurrency Scaling charges persistently exceed the cost of additional reserved nodes at the same capacity, that is a recommendation worth surfacing.
For teams running provisioned Redshift at scale: reserved node coverage on the main cluster, properly configured Concurrency Scaling with usage limits, and regular monitoring of the credit balance versus paid usage is the complete cost governance posture. Usage.ai handles the first piece autonomously. The Concurrency Scaling configuration is a one-time setup that deserves attention before the first unexpected burst charge appears on an invoice.
$91M+ in savings delivered to 300+ customers across AWS, Azure, and GCP. Fee is a percentage of realized savings only. No savings, no fee. 30-minute setup, billing-layer access only.
%2024%20(3).svg)
Frequently Asked Questions
1. How much does Redshift Concurrency Scaling cost?
For 97% of customers, Concurrency Scaling costs nothing because the free credit tier covers all burst usage. Each active provisioned cluster earns 1 free hour of Concurrency Scaling credit per day, accumulating up to a maximum of 30 hours. Beyond the free balance, billing is per-second at the same on-demand rate as your main cluster. A cluster with an on-demand rate of $33.66 per hour generates Concurrency Scaling charges at $0.00935 per second per transient cluster. You are only billed when transient clusters are actively running queries. Source: aws.amazon.com/redshift/pricing/.
2. Do Concurrency Scaling credits expire?
Credits do not expire as long as the cluster is not terminated. Pausing and resuming a cluster preserves the credit balance. Only terminating the cluster resets the balance to zero. This means a cluster that has been running for 30 days without heavy Concurrency Scaling usage has accumulated the full 30-hour maximum credit balance, which provides significant burst runway before any paid usage kicks in. Source: aws.amazon.com/redshift/pricing/ DIRECT.
3. Does Concurrency Scaling support write operations?
Yes, on RG and RA3 node types. Supported write operations include COPY, INSERT, DELETE, UPDATE, CREATE TABLE AS (CTAS), VACUUM, manual materialized view refresh, and automatic vacuum operations. Write Concurrency Scaling is not supported on DC2 nodes. Most DDL operations other than CTAS, ANALYZE for COPY, write operations on DISTSTYLE ALL tables, and write operations on tables with identity columns are excluded. Source: docs.aws.amazon.com/redshift/latest/dg/concurrency-scaling.html DIRECT.
4. How do I prevent unexpected Concurrency Scaling charges?
Two mechanisms work together. Set max_concurrency_scaling_clusters in the cluster parameter group to limit how many transient clusters can spin up simultaneously. Create a usage limit (CreateUsageLimit API or AWS console) to cap total Concurrency Scaling time in a daily, weekly, or monthly period. Set the action to alert to receive notification when the threshold is reached, or disable to stop Concurrency Scaling for the remainder of the period. Usage limits are not created by default — you must explicitly set them. Source: docs.aws.amazon.com/redshift/latest/mgmt/managing-cluster-usage-limits.html.
5. Does reserved node pricing affect Concurrency Scaling charges?
No. Concurrency Scaling billing is always based on the on-demand hourly rate of your cluster’s node type and size, regardless of whether your main cluster runs on reserved or on-demand nodes. If you purchase reserved nodes for your main cluster, your main cluster charges decrease, but the per-second Concurrency Scaling burst rate stays at the on-demand equivalent. The two pricing mechanisms are independent.
6. Is Concurrency Scaling included with Redshift Serverless?
Yes. Concurrency Scaling and Redshift Spectrum are both included at no additional charge with Redshift Serverless. Serverless scales compute capacity automatically as query load changes, and all usage is billed through the RPU-hour model regardless of concurrent query count. The free credit model described in this guide applies only to provisioned Redshift clusters. Source: aws.amazon.com/redshift/pricing/.


