.png)


Amazon EC2 pricing is the billing model AWS uses to charge for virtual compute capacity based on instance type, operating system, region, and how much of your usage is covered by a discounted pricing model. Understanding those variables and how to align them is the difference between a well-managed cloud bill and one that routinely runs 30–50% above what it should.
What Is Amazon EC2 Pricing?
Amazon EC2 pricing refers to how AWS charges for running virtual machines in the cloud. Instead of owning physical servers, you rent compute capacity on demand, choose the machine type, region, and runtime, and pay accordingly. Beyond the per-instance compute rate, EC2 billing includes storage, data transfer, networking, and idle resources that can add 30–50% to an expected monthly bill.
How Amazon EC2 Pricing Works
EC2 pricing is usage-based, with five key variables determining the final cost:
- instance type (CPU, memory, performance class),
- region (us-east-1 is typically cheapest),
- operating system (Linux is baseline; Windows and enterprise Linux cost more),
- pricing model (On-Demand vs. committed),
- coverage (what fraction of usage is actually billed at the discounted rate).
Billing is per-second for most Linux instances (60-second minimum) and per-hour for some other OS types. You are charged for provisioned capacity, not actual utilization; an instance running at 20% CPU still incurs 100% of its cost.
Amazon EC2 Pricing Models Explained
EC2 has five pricing models. In production environments, they function as layers, not alternatives; most mature setups use all five simultaneously, matching each workload to the model that best fits its behavior.
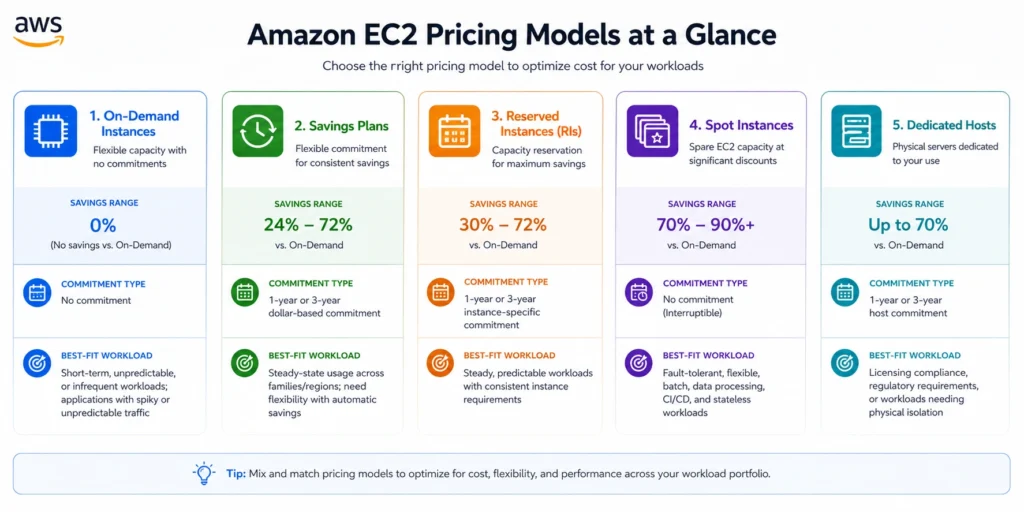
1. On-Demand Pricing
On-Demand is the default: launch instances, pay per second or hour, stop at any time — no commitment required. It offers maximum flexibility at the highest per-unit cost. On-Demand is appropriate for unpredictable workloads, short-term projects, and development environments.
2. Savings Plans (Compute and EC2 Instance)
Savings Plans reduce EC2 costs by committing to a minimum dollar-per-hour spend rate for 1 or 3 years. You commit to a spend level, not a specific instance which preserves flexibility to change instance types, regions, and operating systems without losing the discount.
- Compute Savings Plans: Up to 66% savings across EC2 (any family, any region), Fargate, and Lambda. Migrate to Graviton or a new generation and the discount follows automatically.
- EC2 Instance Savings Plans: Up to 72% savings, locked to one instance family and region. Within that family, size and OS can still change.
Also read: AWS Savings Plan: A Complete Guide to Maximizing Savings
3. Reserved Instances (Standard and Convertible)
Reserved Instances offer up to 72% savings by committing to a specific instance type, region, and term (1 or 3 years). They are the right choice for stable, predictable workloads unlikely to change instance families during the term.
- Standard RIs: Up to 72% savings. Can modify Availability Zone, instance size within the same family, and networking type.
- Convertible RIs: Up to 66% savings, with the ability to exchange for a different instance family, OS, or tenancy trading roughly 6% in discount depth for flexibility.
RIs also offer something Savings Plans don’t: the ability to reserve capacity in a specific Availability Zone, guaranteeing launch availability.
Also read: AWS Reserved Instances: Complete Guide to Pricing, Types & Savings
4. Spot Instances
Spot Instances offer up to 90% savings by using spare AWS capacity with the tradeoff that AWS can reclaim the instance with a two-minute warning. Spot is the right choice for fault-tolerant batch processing, CI/CD pipelines, big data analytics, and any workload that can checkpoint and resume. For workloads requiring continuous uptime, Spot introduces unacceptable interruption risk.
5. Dedicated Hosts
Dedicated Hosts are physical EC2 servers allocated exclusively to your account, providing per-socket and per-core visibility for BYOL licensing (Oracle, Windows Server, SQL Server) and physical isolation for compliance-driven workloads. Pricing is per-host per hour. On-Demand Dedicated Host rates are higher than shared tenancy, but 1- or 3-year commitments reduce costs by up to 70%.
Bonus: EC2 Free Tier EC2 Free Tier
The AWS Free Tier gives new accounts access to EC2 at no charge, but the structure changed on July 15, 2025 benefits differ by account creation date.
- Accounts created before July 15, 2025: 750 hours/month of t2.micro or t3.micro (Linux or Windows) for 12 months, plus 30 GB of EBS storage (gp2, gp3, or magnetic). Enough to run one instance continuously for a year.
- Accounts created on or after July 15, 2025: Up to $200 in AWS credits valid for 6 months (not 12), redeemable across eligible services. Free-tier eligible instance types include t3.micro, t3.small, t4g.micro, t4g.small, c7i-flex.large, and m7i-flex.large.
There is no permanent EC2 Free Tier. After credits or the 12-month window expires, all usage bills at On-Demand rates. Sources: AWS EC2 Free Tier documentation, AWS EBS Pricing.
EC2 Pricing Model Comparison
The table below compares all seven EC2 pricing options across savings potential, commitment structure, flexibility, and interruption risk, the four dimensions that determine which model fits a given workload.
| Model | Max Savings | Commitment | Flexibility | Interruption Risk |
| On-Demand | — | None | Maximum | None |
| Compute Savings Plan | Up to 66% | 1–3 yr spend rate | High (any family, region, Fargate, Lambda) | None |
| EC2 Instance Savings Plan | Up to 72% | 1–3 yr spend rate | Medium (one family/region) | None |
| Standard Reserved Instance | Up to 72% | 1–3 yr instance | Low | None |
| Convertible Reserved Instance | Up to 66% | 1–3 yr instance | Medium (exchangeable) | None |
| Spot Instances | Up to 90% | None | High | High (2-min warning) |
| Dedicated Hosts (3-yr term) | Up to 70% | Optional 1–3 yr | Low | None |
Amazon EC2 Instance Types and Pricing
EC2 instance type selection has the largest single impact on both performance and cost. AWS EC2 instance pricing varies significantly across families choosing the wrong family or generation routinely results in overpaying by 20–50% for resources the workload doesn’t need. EC2 offers 750+ instance types across five families.
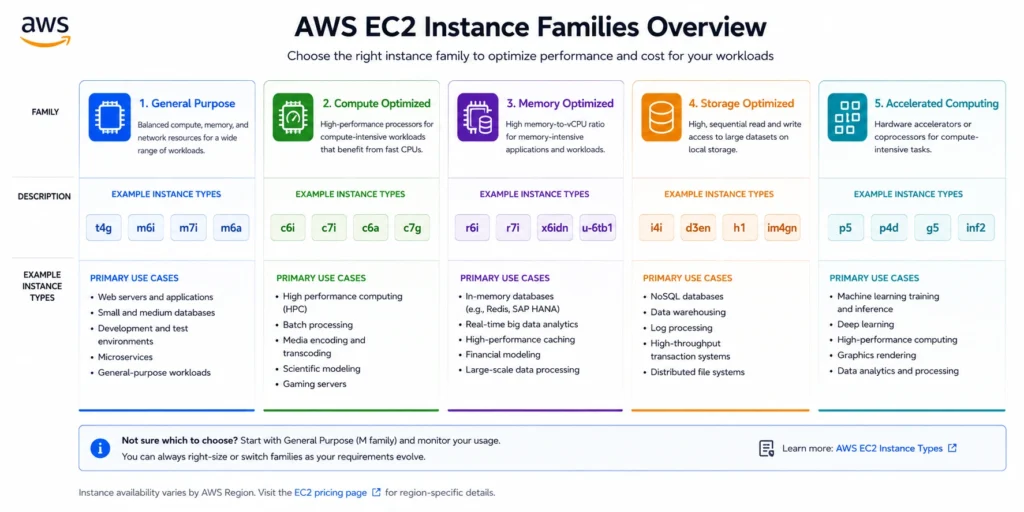
General Purpose Instances (T and M Families)
General purpose instances provide a balanced ratio of CPU, memory, and networking, the right starting point for most web applications, APIs, and development workloads.
- T family (T3, T4g): Burstable instances with a CPU credit model. Cost-effective for low-average-CPU workloads (dev environments, low-traffic web servers). A t3.large runs $0.0832/hr (~$61/month) Linux in us-east-1. Caution: In Unlimited mode, sustained CPU above baseline charges $0.05/vCPU-hr which can make T-family more expensive than M-family for steady-state workloads.
- M family (M5, M6i, M7i, M8g): Consistent non-burstable CPU for production workloads. M8g instances are powered by AWS Graviton4 processors and deliver up to 30% better compute performance than Graviton3-based M7g instances (source: AWS EC2 C8g and M8g launch, September 2024). An m5.large runs $0.096/hr (~$70/month) Linux in us-east-1.
Compute Optimized (C Family), Memory Optimized (R and X Families), and Storage Optimized (I and D Families)
Compute optimized instances (c5, c6i, c7i, c8g) provide high CPU-to-memory ratios for batch processing, video encoding, and CPU-bound workloads. Memory optimized instances (r5, r6i, r7i, x1e) provide high memory-to-CPU ratios for in-memory databases, real-time analytics, and SAP HANA. Storage optimized instances (i3, i4i, i8g) provide high-speed NVMe local storage for NoSQL databases and data warehousing requiring dense local I/O.
Accelerated Computing Instances (P, G, Inf, Trn Families)
Accelerated computing instances use hardware accelerators, NVIDIA GPUs, and AWS-designed ML chips for parallel processing and AI/ML workloads.
- P family (P4d, P5, P5en, P6-B200): NVIDIA GPU instances for ML training. P5 instances received up to 45% pricing reductions in June 2025. P5.48xlarge runs at approximately $98/hour On-Demand in us-east-1.
- G family (G4, G5, G6): More cost-efficient GPUs for ML inference, graphics workstations, and video processing. g4dn.xlarge runs ~$0.526/hour.
- Inf2 and Trn1: AWS-designed chips for ML inference and training at lower cost than general-purpose GPU instances.
GPU pricing changes frequently verify current rates at aws.amazon.com/ec2/pricing/on-demand before making commitment decisions.
AWS Graviton Instances: 10–20% Lower Cost
AWS Graviton instances run on AWS-designed ARM processors and consistently deliver 10–20% lower per-hour rates than equivalent x86 instances, with comparable or better performance for most Linux workloads.
| Generation | Families | Notes |
| Graviton2 | m6g, c6g, r6g, t4g | First broad-adoption ARM generation |
| Graviton3 | m7g, c7g, r7g | Up to 25% better than Graviton2 |
| Graviton4 | m8g, c8g, r8g | Up to 30% better than Graviton3; 2026 recommendation for new deployments |
The t4g.nano is the lowest-cost EC2 instance at $0.0042/hr (~$3.07/month) in us-east-1 Linux, 20% cheaper than the equivalent t3.nano. For stateless Linux workloads, Graviton migration requires no application code changes. Evaluate Graviton before purchasing any new Savings Plan or RI commitment locking in a commitment on an x86 instance you’re planning to migrate wastes the commitment.
Also read: EC2 Instance Types: What Are EC2 Instances?
Linux vs. Windows vs. RHEL: EC2 Instance Pricing by OS
Operating system choice directly affects the per-hour EC2 rate. The table below uses t3.large (2 vCPUs) in us-east-1 (verified June 2026). Windows and SQL Server rates are per-instance; RHEL rates are per-vCPU-hour since July 2024.
| OS | On-Demand Rate | Monthly Cost (730 hrs) | Premium vs. Linux |
| Linux (Amazon Linux, Ubuntu) | $0.0832/hr | ~$61 | — |
| Windows Server | $0.1072/hr | ~$78 | +29% |
| Windows + SQL Server Web | $0.2656/hr | ~$194 | +219% |
| RHEL | Per-vCPU-hour verify current rate | Varies by instance size | +30–50% typical |
SQL Server on Windows roughly doubles to triple the instance cost. RHEL moved to per-vCPU-hour pricing on July 1, 2024 rates vary by instance size and subscription tier. For t3.large (2 vCPUs), RHEL typically adds $0.06/hr for the license component on top of the Linux base rate, bringing the effective rate to approximately $0.14/hr. Always verify current rates at the RHEL on AWS Pricing page before budgeting.
What You Actually Pay for in EC2: Full Cost Breakdown
Your EC2 bill includes five components. The compute instance is often not the largest once storage, data transfer, and networking are accounted for.
Compute (Instance Runtime)
Compute cost is the base per-second or per-hour charge for the instance itself. You pay for provisioned capacity regardless of utilization.
EBS Storage: Volume Types and Pricing
EBS charges continue even when the instance is stopped. Costs depend on volume type and provisioned size. EBS volume types (us-east-1, June 2026):
| Volume Type | Storage Cost | Baseline Performance | Best For |
| gp3 (recommended) | $0.08/GB-month | 3,000 IOPS, 125 MB/s included | Most workloads |
| gp2 (legacy) | $0.10/GB-month | 3 IOPS/GB, burst to 3,000 | Superseded by gp3 |
| io2 Block Express | $0.125/GB-month + $0.065/IOPS-month | None included | High-performance databases |
| st1 | $0.045/GB-month | Throughput-optimized | Log processing, data warehouses |
| sc1 | $0.015/GB-month | Lowest cost | Cold, infrequently accessed data |
Migrate from gp2 to gp3 immediately if you haven’t already gp3 is 20% cheaper per GB, provides 3,000 IOPS regardless of volume size, and the migration is live with no downtime.
Snapshots cost $0.05/GB-month (incremental) and accumulate silently. Implement retention policies using Amazon Data Lifecycle Manager to avoid snapshot sprawl.
Data Transfer Costs: Rates by Traffic Type
Data transfer is frequently the third-largest EC2 line item for distributed architectures. Key rates (us-east-1, verified June 2026):
| Traffic Type | Rate |
| Inbound (into AWS) | Free |
| Same AZ, private IPs | Free |
| Cross-AZ (same region, each direction) | $0.01/GB |
| Cross-region | $0.02/GB (most region pairs) |
| Internet egress: first 100 GB/month | Free |
| Internet egress: 0–10 TB | $0.09/GB |
| Internet egress: 10–50 TB | $0.085/GB |
| Internet egress: 50–150 TB | $0.07/GB |
Networking Components and Idle Resources
NAT Gateways charge $0.045/hr (~$32.40/month per gateway) plus $0.045/GB processed. VPC Gateway Endpoints eliminate NAT Gateway processing fees for S3 and DynamoDB traffic. Elastic IPs are free when attached to a running instance; unattached EIPs charge ~$0.005/hr. Detached EBS volumes, accumulated snapshots, and forgotten non-production instances represent the most common sources of unnoticed background spend.
Amazon EC2 Pricing Example: Real-World Cost Breakdown
Scenario: 10 × m5.large instances, Linux, running 24/7 in us-east-1 (m5.large On-Demand verified at $0.096/hr, June 2026). Savings percentages are approximate and based on 1-year No Upfront rates; verify current Savings Plan rates at aws.amazon.com/savingsplans/pricing.
| Pricing Model | Monthly Cost | Annual Cost | Savings vs. On-Demand |
| On-Demand | ~$700 | ~$8,400 | — |
| Compute Savings Plan (1-yr) | ~$455 | ~$5,460 | ~35% |
| EC2 Instance Savings Plan (1-yr) | ~$420 | ~$5,040 | ~40% |
| Standard RI (3-yr All Upfront) | ~$390 | ~$4,680 | ~44% |
| Spot (blended) | ~$250–300 | ~$3,000–3,600 | ~60–70% |
These percentages apply only to covered usage. Coverage is what determines realized savings, not the model itself.Coverage makes the actual difference. Same workload, same 1-year Compute Savings Plan (35% off covered usage) different coverage levels:
- 40% coverage: 60% still billed On-Demand. Effective monthly cost ~$600. ~14% total savings.
- 80% coverage: 20% On-Demand. Effective monthly cost ~$500. ~29% total savings.
~$100/month difference (~$1,200/year) on a modest workload not from changing the pricing model, but from increasing coverage. Calculations: (40% × $700 × 0.65) + (60% × $700) = $603; (80% × $700 × 0.65) + (20% × $700) = $504.
The Most Misunderstood Concept in EC2 Pricing: Coverage
EC2 coverage is the percentage of your total compute usage billed under discounted pricing (Savings Plans or RIs) rather than On-Demand rates:
| Coverage (%) = Usage billed under commitments ÷ Total compute usage |
Pricing models define how much you could save. Coverage determines how much you actually save. Two teams using identical Savings Plans with 80% vs. 40% coverage end up with fundamentally different effective cost rates.
Two failure modes:
- Undercoverage: Large On-Demand exposure. Savings exist on paper but aren’t captured in practice.
- Overcoverage: Committed spend exceeds actual usage. You’ve prepaid for compute that no longer exists. This failure is harder to detect; it shows up not as unused infrastructure but as commitments generating less value than expected.
Also read: 7 AWS Savings Plan KPIs Every FinOps Team Should Track for Better Cost Efficiency
Why Savings Plans and RIs Don’t Always Deliver Expected Savings
Savings Plans and Reserved Instances underperform when committed usage and actual usage drift apart. Commitments are fixed for 1–3 years while infrastructure evolves continuously — new services launch, teams migrate instance generations, and scaling patterns shift. By the time drift is visible, months of sub-optimal spend have accumulated. Compute workloads tolerate longer commitment terms; database and specialized services evolve faster and are harder to commit against accurately.
Also read: AWS Savings Plans vs Reserved Instances: A Practical Guide
The Real Tradeoff: Cost vs. Flexibility vs. Risk
Every EC2 pricing decision trades off three variables that cannot all be optimized simultaneously. Lower cost requires higher commitment; higher commitment reduces flexibility; reduced flexibility increases misalignment risk. The goal is a portfolio that manages this tradeoff intelligently: committed pricing for the stable baseline, On-Demand for variable headroom, Spot for fault-tolerant workloads.
Also read: How to Choose Between AWS Savings Plan Types
EC2 Cost Optimization Framework Used by FinOps Teams
Effective EC2 cost optimization treats pricing as a portfolio problem maintained over time — not a one-time configuration decision.
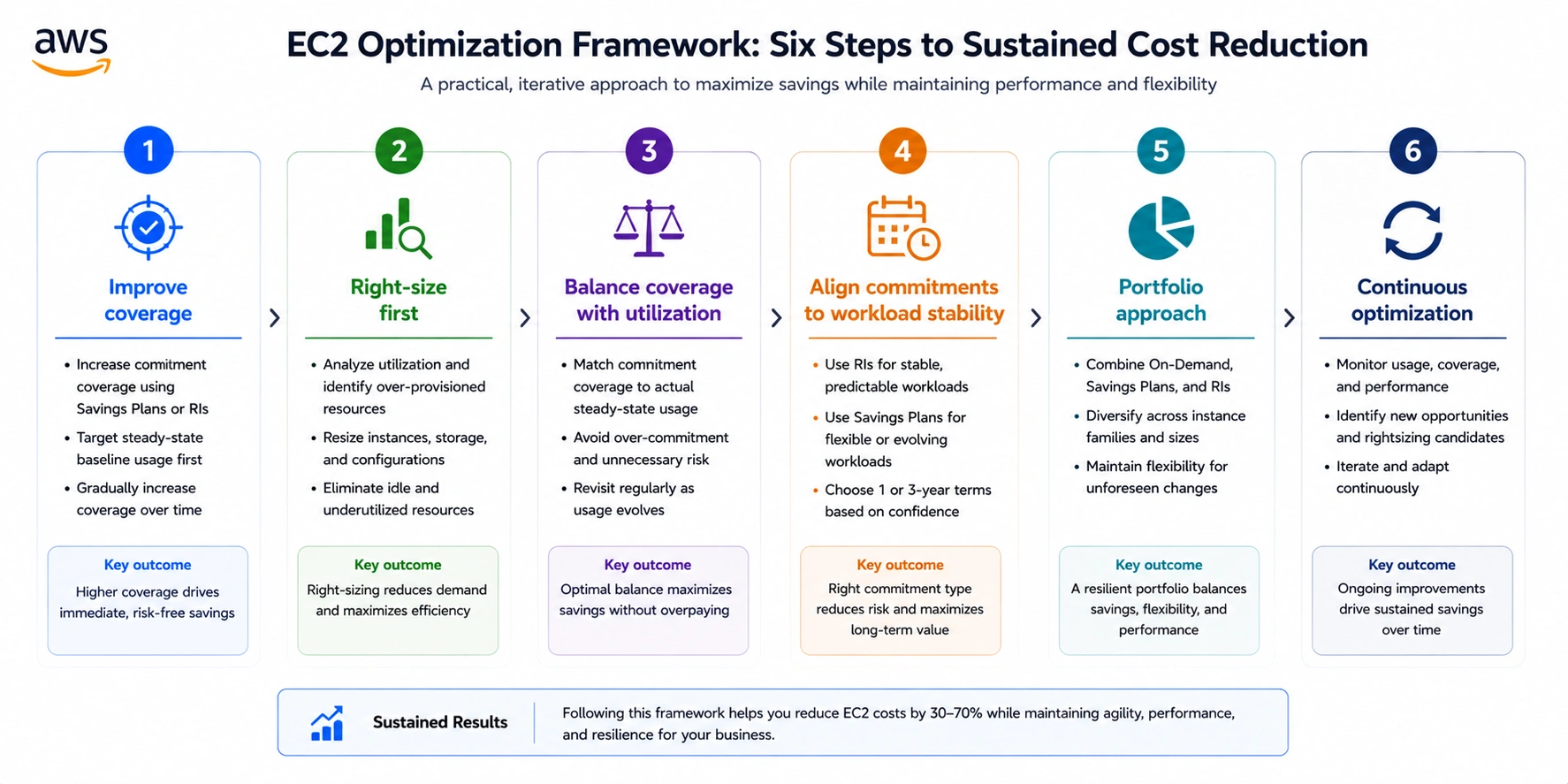
- Start with coverage, not resource reduction. Increasing coverage from 50% to 75–80% typically reduces total compute cost more than aggressive rightsizing, because more of the existing workload benefits from the discount rate.
- Right-size before you commit. A 40% discount on an oversized instance still represents significant overspend. Use CloudWatch P90 CPUUtilization (below 40% signals over-provisioning) and FreeableMemory (consistently above 25% of RAM signals over-provisioned memory) to identify candidates before purchasing commitments typically reduces required commitment count by 20–30%.
- Balance coverage with utilization. A system with 80% coverage but 70% utilization is still inefficient. Well-optimized environments target coverage of 70–85% and utilization of 85–95%.
- Align commitments with workload stability. Commit aggressively to stable, long-running services; commit conservatively to workloads that scale frequently or migrate instance generations.
- Treat pricing as a portfolio. Target structure: 60–80% covered by Savings Plans or RIs, 10–30% On-Demand, 0–20% Spot for fault-tolerant workloads.
- Optimize continuously, not periodically. Infrastructure changes daily; monthly reviews allow misalignment to accumulate. AWS Cost Explorer recommendations are 72+ hours old. Even a 5–10% gap between committed and actual usage compounds to meaningful inefficiency at scale.
EC2 vs. Fargate vs. Lambda: When to Use Each
EC2 is cheapest for always-on workloads with predictable utilization; Fargate is cheaper when significant idle time makes provisioned instances wasteful; Lambda is cheapest for infrequent, short-duration event-driven tasks.
| Service | Best For | Cost Profile |
| EC2 | Always-on, high-utilization workloads (>40% of the time) | Lowest $/compute-hour with commitments |
| AWS Fargate | Variable container workloads with significant idle time | No idle cost; higher per-unit than EC2 |
| AWS Lambda | Short, infrequent, event-driven tasks | Cheapest for sparse invocations; expensive at high sustained throughput |
For high-utilization Fargate workloads running 24/7, migrating to EC2 launch type with Compute Savings Plans can substantially reduce compute costs; the savings depend on the specific workload size and configuration.
Also read: On-Demand vs Reserved vs Spot: The Complete AWS Pricing Guide 2026
Common Mistakes That Increase Amazon EC2 Costs
- Treating On-Demand as the permanent default. On-Demand makes sense early; it rarely makes sense once workloads stabilize. Baseline compute running predictably for months should be covered under Savings Plans or RIs.
- Overcommitting to capture maximum discounts. Aggressive commitment adoption only works if usage stays stable. Infrastructure changes and it almost always does leaving committed capacity generating no value while the cost continues.
- Ignoring coverage as a metric. Many teams track total spend but not coverage rate, making it impossible to know whether 40% of usage is still running at full On-Demand price.
- Focusing on discount rates, not utilization. A 60% discount delivers value only when the commitment is fully utilized. If utilization drops to 70%, a substantial portion of the discount is effectively lost.
- Treating optimization as a periodic task. Infrastructure changes daily; quarterly reviews allow significant misalignment to accumulate before correction.
- Committing before right-sizing. This locks in waste for 1–3 years. The correct sequence: right-size first, confirm stability, then commit.
Also read: Cloud Waste in AWS: Causes, Examples & How to Eliminate It
Amazon EC2 Pricing Calculator: How to Estimate Your Costs
The AWS Pricing Calculator (calculator.aws) generates estimated monthly costs for any EC2 configuration you define. It’s most useful before deployment when comparing pricing models or forecasting spend.
Step-by-Step: How to Use the AWS Pricing Calculator
To estimate EC2 costs with the AWS Pricing Calculator, follow these six steps the tool is free and requires no AWS account.
- Go to calculator.aws, click “Create estimate,” search for Amazon EC2, and click Configure.
- Select your operating system, tenancy model, and pricing scenario (On-Demand, Reserved, Savings Plan, or Spot).
- Enter instance type, quantity, and monthly usage hours (730 hours = always-on; ~176 hours = typical 8-hr weekday dev environment).
- Add EBS storage: select volume type (gp3 for most workloads), provisioned GB, and any additional IOPS.
- Add estimated outbound data transfer in GB for a more accurate total.
- Click “Save and view summary” for the estimated monthly and annual cost.
What the AWS calculator does not show: changes in usage over time, partial coverage across workloads, underutilization of existing commitments, or hidden costs from snapshots, unattached volumes, and NAT Gateway traffic. Also see AWS Pricing Calculator vs Usage.ai Savings Calculator.
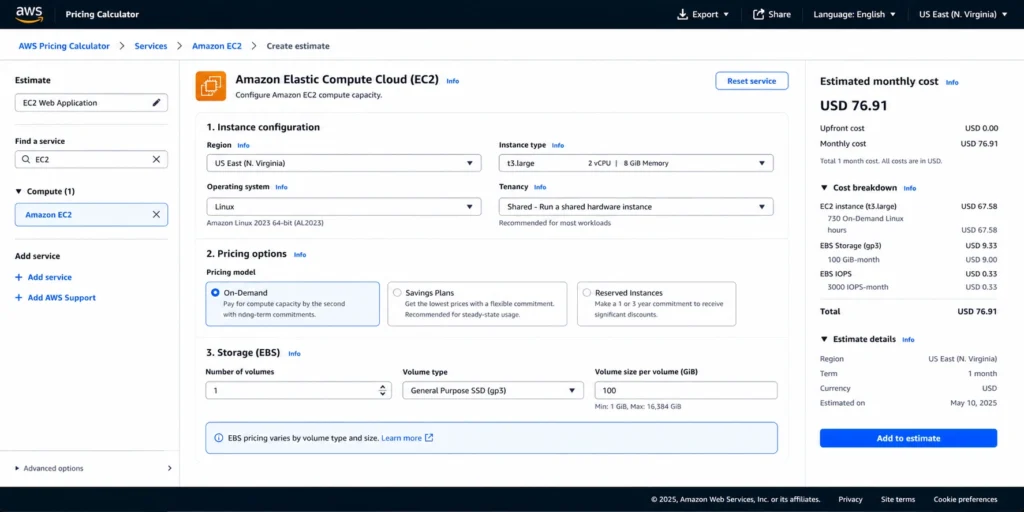
See Your Actual Overpayment: Usage.ai Savings Calculator
The AWS Pricing Calculator shows list prices for a hypothetical configuration. Usage.ai’s Savings Calculator analyzes your live AWS billing data to show how much you’re currently overpaying and what a fully optimized coverage strategy would recover.
Run your free Savings Assessment →
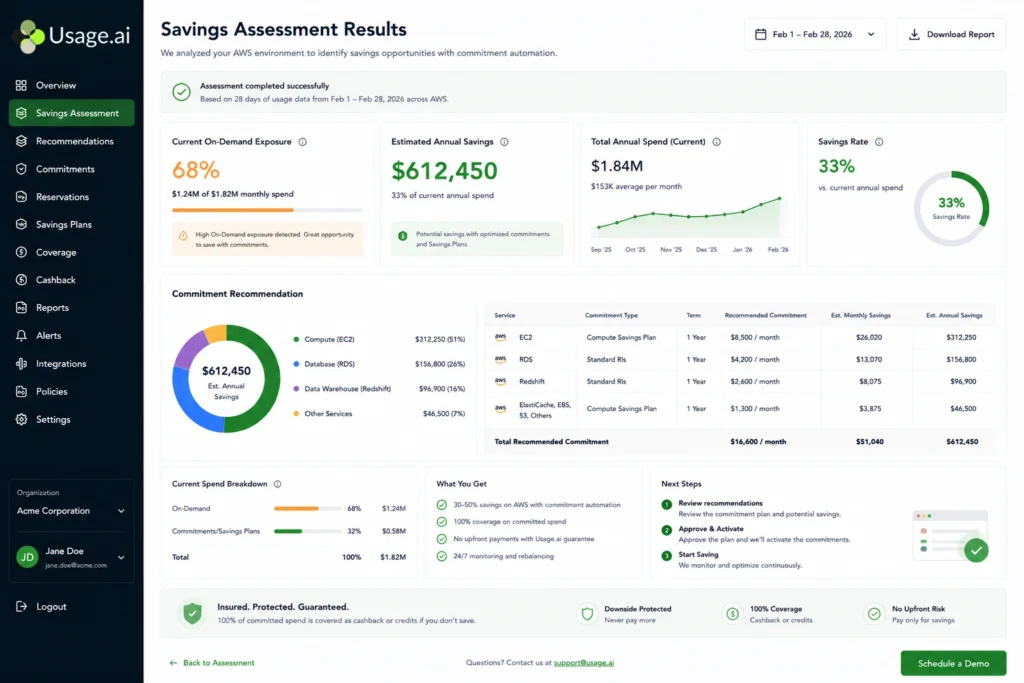
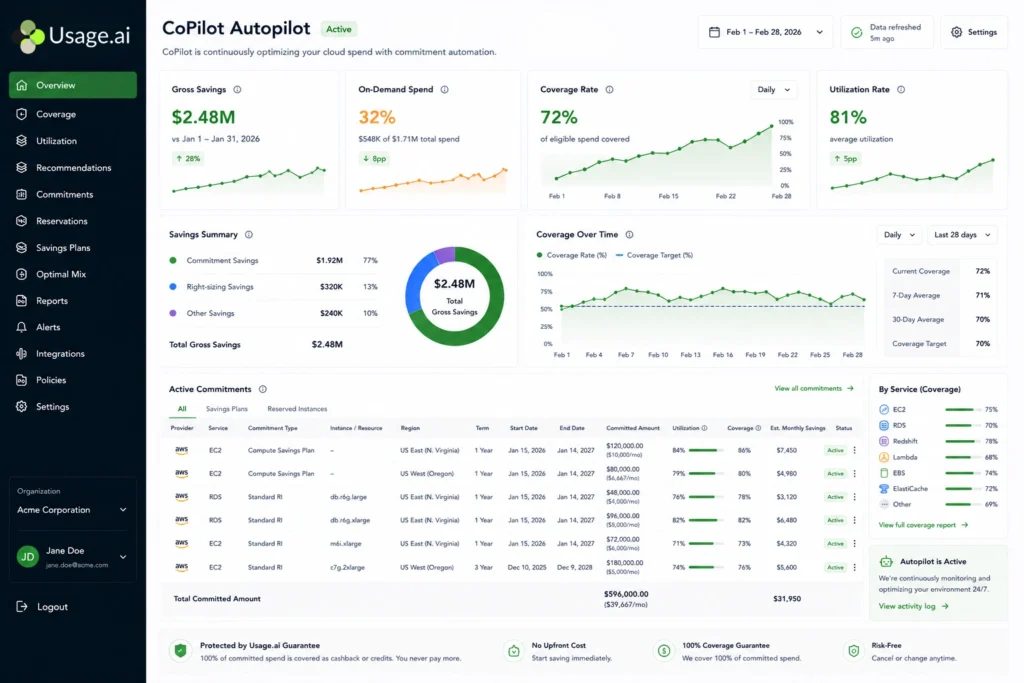
How Modern Platforms Approach EC2 Optimization
The core problem with native AWS tooling: Cost Explorer and Trusted Advisor generate RI and Savings Plan recommendations based on data that is 72+ hours old. By the time a FinOps engineer reviews recommendations, obtains approval, and makes purchases, usage data may be 4–6 weeks stale compounding missed savings daily.
Modern optimization platforms address this through continuous usage analysis across all accounts, dynamic commitment modeling, and 24-hour recommendation refresh cycles.
Usage.ai’s Insured Flex Commitments operate on top of AWS’s native pricing models: Flex Savings Plans cover EC2, Fargate, and Lambda (40–60% savings); Flex Reserved Instances cover RDS, ElastiCache, OpenSearch, Redshift, and DynamoDB (20–40% savings) all at $0 upfront with no multi-year lock-in.
The key differentiator is the cashback guarantee: if a commitment goes underutilized, Usage.ai provides real cashback (not credits) for the unused portion eliminating the over-commitment tax. Usage.ai’s fee is a percentage of actual savings realized; if the platform doesn’t save you money, you pay nothing.

Frequently Asked Questions
1. What is Amazon EC2 pricing per hour?
EC2 pricing per hour varies by instance type, region, OS, and pricing model. Reference rates in us-east-1 Linux On-Demand: t3.micro – $0.0104/hr (~$7.59/month); m5.large $0.096/hr (~$70/month); t4g.nano $0.0042/hr (~$3.07/month). Savings Plans and Reserved Instances reduce per-hour rates by approximately 35–72% for committed usage, depending on plan type and term. Verify current rates at aws.amazon.com/ec2/pricing/on-demand.
2. What is the cheapest EC2 instance type?
The cheapest On-Demand EC2 instance is the t4g.nano (Graviton2 ARM) at $0.0042/hr (~$3.07/month) in us-east-1 Linux 20% cheaper than the equivalent t3.nano. For interruptible workloads, Spot pricing for t-family instances can push rates below $0.002/hr.
3. Does a stopped EC2 instance still cost money?
A stopped instance incurs no compute charges. However, attached EBS volumes continue billing at their provisioned rate (e.g., $0.08/GB-month for gp3), unattached Elastic IPs charge ~$0.005/hr, and snapshots continue accumulating at $0.05/GB-month.
4. What is the cheapest EC2 pricing model?
Spot Instances are cheapest (up to 90% off On-Demand) but can be interrupted with a two-minute warning suitable only for fault-tolerant workloads. For always-on workloads requiring continuous availability, 3-year All Upfront Reserved Instances offer the deepest stable discount (up to 72%).
5. What is EC2 coverage and why does it matter?
EC2 coverage is the percentage of total compute usage billed under discounted pricing (Savings Plans or RIs) rather than On-Demand rates. Coverage is the primary driver of realized savings not which model you choose. Two teams using identical Savings Plans but with 80% vs. 40% coverage end up with substantially different effective costs.
6. Are Savings Plans worth it?
Yes, for stable and predictable workloads. Compute Savings Plans save up to 66%; EC2 Instance Savings Plans save up to 72%. Effectiveness depends on how closely committed spend matches actual usage over the term.
7. What is the difference between Savings Plans and Reserved Instances?
Savings Plans commit to a dollar-per-hour spend rate, applying discounts automatically across EC2, Fargate, and Lambda regardless of instance type. Reserved Instances commit to a specific instance configuration and offer deeper discounts for exact-match usage but are rigid when infrastructure changes. Most teams use Compute Savings Plans for evolving EC2 and serverless workloads, and RIs for stable database services (RDS, ElastiCache, Redshift).
8. Can Reserved Instances be canceled?
Standard and Convertible RIs generally cannot be canceled after purchase. Standard RIs can be listed on the AWS RI Marketplace (typically selling at 60–80 cents on the dollar); Convertible RIs can be exchanged for different configurations.
9. What is a Dedicated Host and how is it priced?
A Dedicated Host is a physical EC2 server allocated exclusively to your account for BYOL licensing (Oracle, Windows Server, SQL Server) and compliance-driven physical isolation. Pricing is per-host per hour; 1- or 3-year commitments reduce costs by up to 70%.
10. Is there an EC2 Free Tier?
Yes, but it changed on July 15, 2025. Accounts created before that date receive 750 hours/month of t2.micro or t3.micro (Linux or Windows) for 12 months, enough to run one instance continuously. Accounts created on or after July 15, 2025 receive up to $200 in credits valid for 6 months, usable across eligible services including EC2. There is no permanent Free Tier for EC2 on either plan.
Pricing figures verified against AWS official pricing pages and third-party pricing databases in June 2026. EC2 pricing changes periodically always confirm current rates at aws.amazon.com/ec2/pricing/on-demand before making commitment decisions.


