.png)


By 2026, the model question is largely settled. Claude, GPT-4o, and Gemini trade benchmark positions weekly. The real decision enterprises face is which managed LLM platform governs cost, compliance, and integration depth and then how to stop paying on-demand prices for workloads that have been running predictably for six months.
Most teams land on their LLM platform for the wrong reason: the data team chose Vertex AI because they were already on GCP, the engineering team chose Bedrock because AWS IAM was familiar, the enterprise architecture team chose Azure OpenAI because legal had approved Microsoft. Now finance is looking at three separate AI bills in three incompatible billing formats and nobody can explain the combined number.
This guide answers the question that none of the platform-specific posts address: what do AWS Bedrock, Vertex AI, and Azure OpenAI actually cost, what makes those bills 1.5-2x larger than the token pricing page suggests, and what can a FinOps team do to govern spend across all three without rebuilding their entire infrastructure stack.
The Verdict: Which Platform Should You Choose?
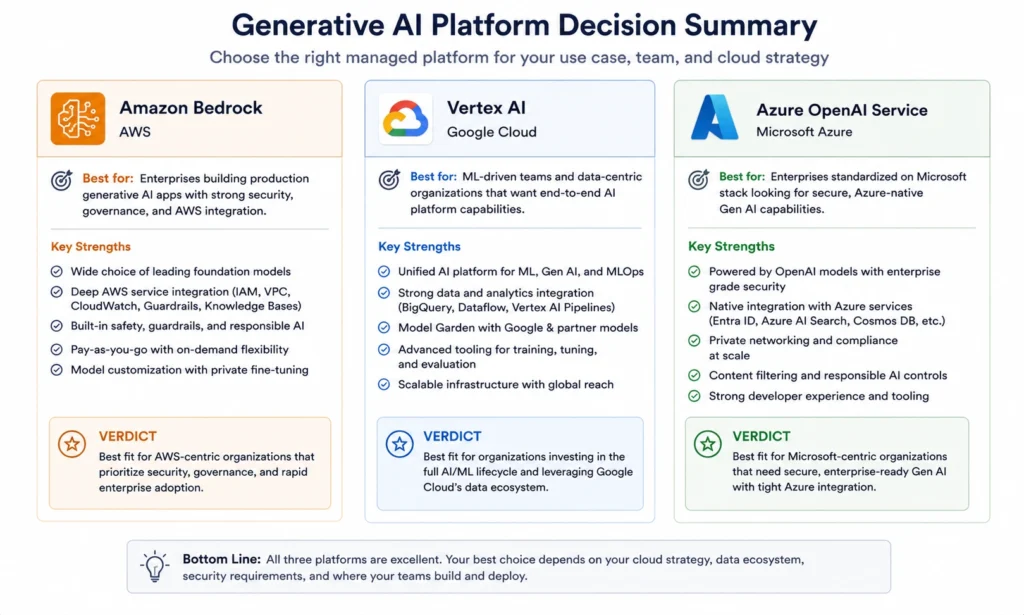
If you are evaluating all three platforms, start here. Platform choice is determined by ecosystem alignment first and cost second: the integration savings from staying in your existing cloud typically outweigh per-token price differences unless your token volume is extremely high.
Choose AWS Bedrock when your infrastructure is AWS-native, you need access to multiple model providers (Claude, Llama, Mistral, Nova) under a single API with AWS IAM controls, and compliance relies on existing AWS certifications. Bedrock wins on model breadth — 75+ models from 18+ providers and on AWS-ecosystem integration depth.
Choose Vertex AI when your data lives in BigQuery or Cloud Storage, your team runs ML pipelines on GCP, or you want Gemini’s native multimodal and long-context capabilities. Vertex AI wins on data-platform integration and on cost-per-token at the budget tier; Gemini 2.5 Flash-Lite at $0.10 per million input tokens is the cheapest production-grade model from any major provider.
Choose Azure OpenAI when your organization runs Microsoft 365, Teams, or Dynamics and needs seamless Entra ID integration, or when legal and compliance have approved Azure but not other AI providers. Azure OpenAI wins on GPT-family exclusivity and on Microsoft-stack enterprise governance.
The wrong choice costs 40-60% more per token in integration overhead alone, before you even count token prices. But platform fit matters less than most teams think, because once you have production traffic, the commitment purchasing layer is where the largest sustained savings live, regardless of which platform you are on.
Also read: What Does GPU Instance Cost Optimization Actually Look Like Across AWS, GCP, and Azure?
Platform Pricing at a Glance: The Comparison Table
All prices are approximate, as of 2026, for standard on-demand usage in primary US regions. Verify at aws.amazon, cloud.google, and azure.microsoft — rates change.
| Dimension | AWS Bedrock | Google Vertex AI | Azure OpenAI |
| Pricing model | Per token, on-demand or provisioned throughput | Per token, on-demand or CUD-backed | Per token (PAYG) or PTU (provisioned throughput units) |
| Flagship model (input / output per 1M tokens) | Claude Sonnet 4.6: $3.00 / $15.00 | Gemini 2.5 Pro: $1.25 / $10.00 | GPT-5: $1.25 / $10.00 |
| Budget model (input / output per 1M tokens) | Amazon Nova Micro: $0.035 / $0.14 | Gemini 2.5 Flash-Lite: $0.10 / $0.40 | GPT-5-nano: $0.05 / $0.40 |
| Batch discount | 50% off | 50% off | Available on select models |
| Prompt / context caching discount | Up to 90% off cached input (Claude models) | Up to 90% off cached input | Available on select models |
| Cross-region / multi-region surcharge | +10% on all tokens | +10% on non-global endpoints | Varies by region |
| Commitment discount | Savings Plans (30-66% off underlying compute) | Resource-based CUDs (up to 55% on compute) | Reserved Instances (30-50% off) |
| Lock-in on commitment | 1-3 year term | 1-3 year term | 1-3 year term |
| Hidden cost risk | Knowledge Base vector storage, agent token amplification, cross-region | Idle endpoints, egress, video generation | Fine-tune hosting, PTU over-commitment, egress to non-Azure |
| Multi-model access | 75+ models, 18+ providers | Gemini family + Model Garden (50+ models) | OpenAI family + limited third-party |
| FedRAMP High | Yes | In progress (not yet GA as of June 2026) | Yes |
| Best for | AWS-native, multi-model flexibility | GCP data stack, Gemini multimodal, budget inference | Microsoft-first, GPT-family dependency |
| Your LLM bill is probably 1.5x what it should be.
Usage.ai shows you exactly where across Bedrock, Vertex AI, and Azure OpenAI in 30 minutes with read-only billing access. |
AWS Bedrock Pricing: What the Pricing Page Does Not Tell You
AWS Bedrock’s official pricing page shows clean per-token numbers. The page is accurate. The bill is not what the page suggests.
On-Demand Token Rates (2026, us-east-1)
Representative models, all prices approximate (verify at aws.amazon.com/bedrock/pricing — rates change):
| Model | Input per 1M tokens | Output per 1M tokens | Notes |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Output is 5x input — output-heavy apps pay disproportionately |
| Claude Haiku 4.5 | $1.00 | $5.00 | Default for high-volume, quality-adequate tasks |
| Claude Opus 4.6 | $5.00 | $25.00 | Use only when Sonnet is measurably insufficient |
| Amazon Nova Micro | $0.035 | $0.14 | Cheapest production model on Bedrock; ~143x cheaper than Opus |
| Amazon Nova Lite | $0.06 | $0.24 | Best price-performance for classification and routing |
| Amazon Nova Pro | $0.80 | $3.20 | ~73% cheaper than Sonnet; quality gap matters for complex tasks |
| Meta Llama 3.3 70B | $0.72 | $0.72 | Note: 201% premium over dedicated providers (Together AI: $0.88) |
| Mistral Large 2 | $3.00 | $9.00 | Strong coding alternative to Claude at similar price point |
| DeepSeek v3.2 | $0.62 | $1.85 | Added Feb 2026; strong reasoning at budget price |
The output-to-input asymmetry is the first pricing trap. Claude Sonnet 4.6 charges $3.00 per million input tokens and $15.00 per million output tokens, a 5x ratio. For applications generating long responses (code generation, detailed analysis, document drafting), output tokens dominate the bill regardless of what the input price suggests.
The Four Pricing Tiers Beyond On-Demand
Bedrock introduced four service tiers in 2026 that most teams have not fully mapped:
Standard (on-demand): Pay-per-token, no commitment, subject to throttling at peak demand. Default for variable workloads.
Flex (1-hour TTL): 50% off on-demand pricing through the regular Converse and InvokeModel APIs. No restructuring required. Launched January 2026 for Claude Sonnet 4.5, Haiku 4.5, and Opus 4.5 families. If your workload tolerates slightly higher latency, this is the easiest cost optimization to implement on Bedrock.
Batch: 50% off, asynchronous processing. Any workload that does not need real-time responses — document processing, data enrichment, content pipelines — should run batch. At scale, this is a significant lever: 50 million tokens per month at Claude Sonnet 4.6 on-demand costs $75,000 in output tokens. The same volume in batch costs $37,500.
Provisioned Throughput: Hourly rate, guaranteed capacity, no throttling. Required for sustained high-volume production workloads. Minimum commitment: 1 month. If your traffic drops below the provisioned level, you pay the full hourly rate regardless.
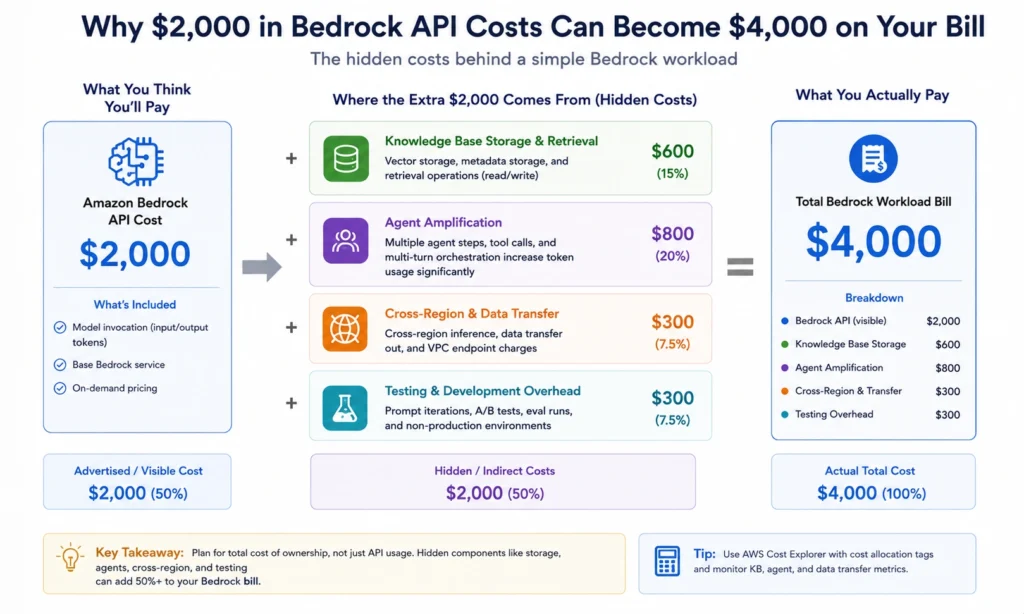
The Hidden Cost Multiplier: What Actually Inflates Your Bedrock Bill
Real companies spend 1.5-2x their initial Bedrock estimates. The overrun is not hidden fees — it is costs that are impossible to calculate before you have production traffic.
Knowledge Base vector storage ($345/month at zero traffic): The default vector store for Bedrock Knowledge Bases is Amazon OpenSearch Serverless. It has a minimum baseline of 2 OpenSearch Compute Units (OCUs) at $0.24 per OCU per hour — approximately $345 per month with zero query traffic. A 2026 alternative worth knowing: Amazon S3 Vectors (launched December 2025) costs up to 90% less than OpenSearch Serverless and supports trillions of vectors with sub-second latency. For new Knowledge Bases, S3 Vectors should be the default unless you have a specific OpenSearch dependency.
Agent token amplification (5-10x): A single user query to a Bedrock Agent can trigger multiple internal model calls — initial reasoning, tool selection, tool result interpretation, synthesis. Token consumption is typically 5-10x the tokens visible in the user prompt and final answer. An agentic workflow handling 5,000 monthly runs on Claude Sonnet 4.6 with Agents and Guardrails commonly lands at $2,500-$6,000 per month — not the $500 implied by the surface-level token math. Also see: Best AI Agents for FinOps
Cross-region inference (+10% on all tokens): Enabling cross-region inference on Bedrock adds a 10% surcharge to all token pricing. Claude Sonnet 4.6 input goes from $3.00 to $3.30 per million tokens. Output goes from $15.00 to $16.50. For a team spending $10,000/month on Bedrock inference, cross-region adds $1,000/month in pure overhead. Enable it only if you regularly experience capacity throttling in your primary region.
Legacy model pricing trap: Claude 3.5 Sonnet in Public Extended Access (legacy model ID) now costs $6.00/$30.00 per million tokens — double the current Sonnet 4.6 price at $3.00/$15.00. Teams that have not updated model IDs since late 2025 are paying 2x for equivalent or inferior performance.
Testing and experimentation costs: Small-scale teams report hidden costs (failed requests, retries, experimentation, infrastructure) equal to 100%+ of their actual API costs. At medium scale, hidden overhead is approximately 47% of API costs. Budget 1.5-2x your calculated API cost for the first six months.
Vertex AI Pricing: Why Google’s Cheapest Models Still Surprise Finance Teams
Vertex AI has the cheapest budget-tier LLM pricing of the three platforms. It also has the most complex billing surface with 15+ separately metered services, some of which call each other under the hood without the developer explicitly invoking them.
Gemini Model Pricing on Vertex AI (2026)
All prices approximate, us-central1, on-demand (verify at cloud.google — rates change):
| Model | Input per 1M tokens | Output per 1M tokens | Notes |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Cheapest production model from any major provider |
| Gemini 2.5 Flash | $0.30 | $2.50 | Best price-performance for high-volume inference |
| Gemini 2.5 Pro | $1.25 | $10.00 | Long context (200K+) doubles to $2.50/$20.00 |
| Gemini 3 Flash | $0.50 | $3.00 | Frontier reasoning at Flash-tier speed |
| Gemini 3.1 Pro | $2.00 | $12.00 | Flagship for complex reasoning; 2M token context |
| Gemini 3.5 Flash | $1.50 | $9.00 | Launched May 2026; outperforms 3.1 Pro on coding at 25% lower cost |
The context window pricing cliff is the most common Vertex AI cost surprise. Gemini 2.5 Pro charges $1.25 per million input tokens for prompts under 200K tokens and $2.50 per million for anything above. RAG pipelines that include large documents can silently push every request into the higher bracket. A team modeling on the $1.25 rate and running 300K-token prompts is actually paying $2.50, a 100% underestimate.
Vertex AI Hidden Costs: What Inflates the Bill
Idle online prediction endpoints (accumulate by the hour): Online prediction endpoints on Vertex AI charge hourly fees even during idle periods, an e2-standard-2 endpoint costs approximately $0.077 per hour continuously. Endpoints remain active and billable until explicitly undeployed. Teams frequently forget to shut down development endpoints. A single forgotten endpoint running for a month costs approximately $56. Ten forgotten endpoints cost $560. The pattern is common enough that Vertex AI billing surprises from this source alone have been reported in the $400-$20,000 range by teams that did not audit idle resources.
Video generation at $0.50-$0.75 per second: Content generation with Imagen (images) and Veo (video) uses completely separate meters from token-based workloads. Video generation pricing has produced some of the most dramatic Vertex AI billing surprises — a pipeline generating 60 seconds of video per run, running 100 times per month, costs $3,000-$4,500 per month in video generation alone, independent of token charges.
Grounding with Google Search ($14 per 1,000 queries): Grounding with Google Search adds $14 per 1,000 queries for Gemini 3.x models (5,000 queries per month free, then paid). For high-volume applications that ground every response with Search, this can add several thousand dollars per month to a bill that the token pricing page does not capture.
Data egress ($0.12/GB to most destinations): Moving data out of Google Cloud incurs $0.12/GB to most destinations. Cross-cloud egress (Vertex inference results into AWS or Azure services) compounds this significantly. RAG pipelines that retrieve from GCP storage and send results to non-GCP services pay egress on every retrieval cycle.
Batch prediction cluster rounding: Vertex AI batch jobs bill for the full cluster runtime, including startup and teardown. A job requiring 15 minutes of actual compute on a 40-node cluster (at $0.544/hour per machine) costs $5.44 — but with 5 minutes of startup/teardown overhead, billed time extends to 20 minutes and the actual cost is $7.25.
Also read: Best GCP Cost Optimization Tools
The 200K Token Context Cliff in Practice
For teams running RAG pipelines, the 200K context cliff is a consistent billing discrepancy. A system prompt plus conversation history plus five retrieved document chunks can easily reach 250K tokens. Every request at that length bills at $2.50 per million input tokens instead of $1.25. A team processing 10 million input tokens per month at $1.25 expects an $12,500 monthly bill. If those tokens are consistently above 200K context, the actual bill is $25,000.
Fix: use prompt caching. Vertex AI context caching reduces repeat input costs by 90% — cached reads cost approximately 10% of the base input rate. Caching the 50K-token knowledge base used in every RAG request eliminates the context cliff cost for the cached portion.
Azure OpenAI Pricing: The Microsoft Tax and the PTU Trap
Azure OpenAI charges the same per-token rates as OpenAI’s direct API. The token prices match to the cent. The actual bill does not.
Azure OpenAI Token Pricing (2026)
All prices approximate (verify at azure.microsoft — rates change):
| Model | Input per 1M tokens | Output per 1M tokens | Notes |
| GPT-5-nano | $0.05 | $0.40 | Budget classification and routing |
| GPT-5 | $1.25 | $10.00 | Flagship; same price as GPT-4.1 but more capable |
| GPT-4.1 | $2.00 | $8.00 | Strong coding and reasoning; slightly cheaper output than GPT-5 |
| GPT-4o | $2.50 | $10.00 | Still widely deployed; verify latest rates |
| o4-mini | Available | Available | Reasoning model for agentic workloads |
GPT-5 launched August 2025 and is the current default production model on Azure OpenAI. It is cheaper on input ($1.25 vs $2.00) than GPT-4.1 while being more capable — making GPT-4.1 the wrong default for most new production workloads.
Azure OpenAI vs Direct OpenAI API: Where the 15-40% Premium Lives
Azure OpenAI is 15-40% more expensive than calling the OpenAI API directly. The token prices are identical. The premium comes from six auxiliary cost layers that stack on top:
- Support plans: $100-$1,000+ per month depending on tier
- Networking and Private Link: Required for regulated workloads, adds per-hour cost
- Fine-tune model hosting: $1.70-$3.00/hour per deployed fine-tune, regardless of traffic. No scale-to-zero. A fine-tuned model deployed for a month with zero traffic costs $1,224-$2,160.
- Log Analytics: Diagnostic logging recommended for production — adds storage and query costs
- Egress: Cross-region and cross-cloud data transfer
- Azure Cognitive Search or AI Search: Required for RAG pipelines on Azure OpenAI
A mid-size team modeling 50 million GPT-4o tokens per month expected $312.50 in token costs. Their first invoice was $485.30 — a 55% overshoot once support, egress, storage, and Log Analytics were included.
Provisioned Throughput Units (PTUs): The Commitment That Punishes Estimation Errors
Azure OpenAI offers PTUs as an alternative to pay-as-you-go pricing. PTUs provide guaranteed throughput capacity at a significantly lower effective per-token rate — and they are the right choice for sustained high-volume workloads.
The break-even point: PTU pricing makes economic sense at approximately 300,000 tokens per minute (TPM) running consistently for 8+ hours per day. Below this volume, on-demand pricing is cheaper. Most teams commit to PTUs before they have 30 days of production traffic data to confirm they actually hit that threshold.
PTU minimum: approximately $2,448 per month per unit. Azure AI Foundry PTU pricing is expensive relative to serverless options on Bedrock or Vertex for bursty workloads. Teams that do not have sustained high-throughput traffic consistently overpay on PTUs.
Azure Regional PTU offers up to 40% savings compared to standard pay-as-you-go rates for high-volume users — but requires accurate traffic forecasting and carries 1-month minimum commitments with no refund for underutilized capacity.
The Fine-Tune Hosting Trap
Fine-tuned model deployments on Azure OpenAI bill hourly as long as they exist, regardless of traffic. There is no scale-to-zero option. There is no idle discount.
Most teams reclaim 15-30% of their Azure OpenAI bill by auditing this single line item: listing every deployment, counting requests in the last 14 days, and decommissioning anything with zero requests unless an owner can justify the hold.
The Governance Problem: Three Bills, Three Languages, No Common Metric
The most expensive LLM cost problem in 2026 is not token prices — it is the fact that most enterprises are running all three platforms simultaneously and cannot explain the combined bill.
Enterprises are deploying generative AI across Azure OpenAI, AWS Bedrock, and Google Vertex AI simultaneously, not as a considered multi-platform strategy, but because different teams chose different platforms for different workloads, and finance cannot explain the combined bill.
The structural problem: three incompatible billing schemas. Azure OpenAI bills on PTUs or pay-per-token. AWS Bedrock bills per 1,000 input/output tokens with no provisioned option for most models. Vertex AI uses tiered token pricing with context caching discounts. None natively attribute costs to business units or applications.
A FinOps team trying to answer “how much did our AI spend cost us per customer interaction last month” cannot get that number from any native billing tool when workloads span all three platforms.
The result: teams optimize within each platform individually, never seeing the cross-platform view that reveals whether running Claude on Bedrock or Claude on Vertex AI (both options exist) is actually cheaper for their specific token mix and usage pattern.
Also read: FinOps for AI: The Practitioner’s KPI Playbook
The Commitment Layer: Where 30-66% Savings Are Being Left on the Table
Every team running sustained, predictable LLM workloads is leaving commitment discounts unclaimed. The hesitation is understandable, committing to a specific throughput level on a platform whose model catalog changes quarterly feels like a bet on an unknown future.
But the commitment purchasing layer on all three platforms operates at the infrastructure compute level, not the model level. This distinction matters.
AWS Bedrock: Savings Plans on Underlying Compute
AWS Compute Savings Plans apply to the EC2 compute underlying Bedrock’s provisioned throughput capacity. A Compute Savings Plan covering committed compute spend delivers up to 66% off on-demand rates, without committing to a specific model or instance type (verify at aws.amazon, rates change).
For teams running Bedrock Provisioned Throughput at scale, the combination of Provisioned Throughput pricing and underlying compute Savings Plans delivers the lowest sustainable per-token cost available on AWS.
GCP Vertex AI: Committed Use Discounts on Compute Nodes
Vertex AI online prediction endpoints run on GCP compute infrastructure. Resource-based Committed Use Discounts apply to the underlying machine types, delivering up to 55% savings on a 3-year CUD (verify at cloud.google.com/compute/pricing — rates change).
Note: GPU-backed Vertex AI endpoints use the same CUD structure as GCP GPU instances — A2/A3 family CUDs are available and deliver up to 65% savings on 3-year terms.
Azure OpenAI: Reserved Instances for Dedicated Compute
Azure Reserved Instances on the compute underlying Azure OpenAI dedicated deployments deliver 30-50% savings for teams with predictable sustained workloads. Regional PTUs also carry a commitment structure that reduces effective per-token rates for high-volume production workloads.
The Lock-In Problem That Keeps Teams on Pay-As-You-Go
All three platforms require 1-3 year commitments for maximum commitment discounts. For LLM infrastructure — where model generations cycle every 6-12 months and usage patterns shift with every new model release, multi-year lock-in feels like a 3-year bet on today’s architecture.
Most teams resolve this by staying on pay-as-you-go indefinitely, leaving 30-66% of their LLM infrastructure spend on the table every month.
This is the problem Usage.ai’s Insured Flex Commitments solve.
Insured Flex Commitment is SP/RI/CUD-equivalent discount structure that delivers commitment-level savings on cloud compute across AWS, GCP, and Azure without requiring multi-year lock-in or upfront payment.
Every commitment is fully insured and underutilized portions are returned as cashback in real money, not credits. Commitments adjust quarterly. Scale down? No penalty. Underutilize? Cashback paid in real money.
The mechanism: Usage.ai holds the commitment on its own balance sheet and passes the discount through to the customer. The customer receives 3-year savings rates without owning a 3-year obligation. Setup takes 30 minutes with billing-layer access only — no infrastructure changes.
Commitment Purchasing Comparison: Native vs. Usage.ai Insured Flex
| Dimension | AWS Savings Plans | GCP CUDs | Azure Reserved Instances | Usage.ai Insured Flex |
| Term | 1-3 years | 1-3 years | 1-3 years | Quarterly adjustments |
| Upfront cost | Upfront or monthly | Full upfront or monthly | Full upfront or monthly | $0 upfront |
| Underutilization protection | None | None | None | Cashback in real money |
| Cancel anytime | No | No | No | Yes, buyback guarantee |
| Recommendation refresh | 72+ hours (Cost Explorer) | Manual | Manual | 24-hour refresh |
| Multi-cloud coverage | AWS only | GCP only | Azure only | AWS + GCP + Azure |
| Fee model | Baked into discount | Baked into discount | Baked into discount | % of realized savings only |
| GPU instance coverage | Yes (p3, p4d, p5, g-series) | Yes (A2, A3, G2) | Yes (ND, NC series) | AWS, GCP, and Azure compute; contact Usage.ai to confirm coverage for specific AI service tiers |
How to Reduce LLM Costs Across All Three Platforms: The 5-Lever Framework
Lever 1: Model routing (40-60% reduction)
The single highest-impact lever on any platform. Defaulting to Claude Sonnet 4.6 ($3.00/$15.00) for tasks that Nova Micro ($0.035/$0.14) handles adequately costs 85x more per token. Map each use case to the cheapest model that meets your quality bar:
- Classification, routing, tagging: Nova Micro / Gemini 2.5 Flash-Lite / GPT-5-nano
- Chat, summarization, extraction: Claude Haiku / Gemini 2.5 Flash / GPT-5
- Complex reasoning, code generation: Claude Sonnet / Gemini 2.5 Pro / GPT-4.1
- Maximum capability: Claude Opus / Gemini 3.1 Pro / GPT-5 (use sparingly)
Lever 2: Prompt caching (up to 90% off repeated input)
All three platforms offer prompt caching that reduces costs by up to 90% on repeated input. Cached reads cost approximately 10% of the base input rate. If your application reuses system prompts, persona instructions, or document preambles across multiple requests — and most applications do — caching is the highest-ROI optimization available. Implement it before touching anything else.
Lever 3: Batch inference (50% off)
Any workload that does not need real-time responses should run batch. Document processing, data enrichment, content generation pipelines, evaluation runs: all qualify. All three platforms offer 50% batch discounts. At 100 million tokens per month, the difference between on-demand and batch is $75,000 in annual savings on Claude Sonnet 4.6 alone.
Lever 4: Idle resource termination (15-30% recovery)
Most teams reclaim 15-30% of their LLM bill by auditing idle resources: undeployed Vertex AI endpoints, unused Bedrock Provisioned Throughput capacity, and Azure OpenAI fine-tune deployments with zero traffic. Run this audit monthly. Automate it with billing anomaly alerts at 50%, 75%, and 90% of monthly budget targets.
Lever 5: Commitment purchasing (30-66% sustained savings)
For workloads with predictable sustained usage — production inference endpoints, regular processing pipelines — commitment purchasing delivers the largest sustained cost reduction. The barrier is lock-in risk. Usage.ai’s Insured Flex Commitments remove that barrier with quarterly adjustments and cashback on underutilized capacity.
Choose AWS Bedrock When / Choose Vertex AI When / Choose Azure OpenAI When
Choose AWS Bedrock when:
- Your infrastructure is AWS-native (VPC, IAM, CloudWatch)
- You need multi-model flexibility accessing Claude, Llama, Mistral, and Nova through one API
- Your compliance story is built on existing AWS certifications (FedRAMP High, HIPAA BAA)
- You are building RAG applications and already have data in S3 or DynamoDB
- You need cross-model intelligent routing (Bedrock’s Intelligent Prompt Routing reduces costs up to 30%)
Choose Vertex AI when:
- Your data lives in BigQuery or Cloud Storage and you want minimal data movement
- You are running ML training pipelines and need ML Ops tooling beyond inference
- You need Gemini’s native multimodal capabilities (video, audio, images) at scale
- Your primary budget concern is inference cost — Gemini Flash-Lite at $0.10/million input tokens is unmatched on price
- You are building agents where long-context (1-2M tokens) Gemini capabilities are differentiated
Choose Azure OpenAI when:
- Your organization is standardized on Microsoft 365, Teams, or Dynamics
- Legal or compliance has approved Azure but not other AI providers
- You need the latest GPT-family models (GPT-5, o4-mini) on day-zero availability
- Your agentic workflows integrate with Microsoft 365 knowledge bases
- You need FedRAMP High with Microsoft’s contractual data protection commitments
Do not choose based on token price alone. At 10-50 million tokens per month, AWS Bedrock generally provides 15-25% lower all-in costs. Azure becomes more competitive at scale with PTUs. Vertex AI wins on budget-tier inference volume. The integration savings from ecosystem alignment typically outweigh per-token differences until volume exceeds 500 million tokens per month.
| Managing LLM spend across multiple clouds?
Usage.ai gives FinOps teams a single view of AWS Bedrock, Vertex AI, and Azure OpenAI commitment coverage with automated purchasing |

Frequently Asked Questions
1. What is the difference between AWS Bedrock, Vertex AI, and Azure OpenAI pricing?
All three use usage-based token pricing with no upfront commitment for on-demand inference, but their billing schemas are fundamentally incompatible. AWS Bedrock bills per 1,000 input/output tokens with separate meters for Knowledge Bases, Guardrails, and Agents. Vertex AI bills per million tokens with a 200K context pricing cliff that doubles input costs above that threshold. Azure OpenAI bills per token (matching direct OpenAI rates) plus six auxiliary cost layers that make it 15-40% more expensive than calling the OpenAI API directly. Model price and platform cost are not the same number on any of the three platforms.
2. Why does my AWS Bedrock bill keep coming in higher than expected?
Real companies consistently spend 1.5-2x their initial Bedrock estimates. The gap is not hidden fees, it is costs that are hard to calculate before production. The four most common sources: Bedrock Knowledge Bases default to OpenSearch Serverless at approximately $345/month with zero query traffic; Bedrock Agents trigger 5-10x more tokens than the visible user prompt; cross-region inference adds a flat 10% surcharge; and legacy model IDs (Claude 3.5 Sonnet Extended Access at $6/$30) charge double current Sonnet 4.6 rates ($3/$15). Budget 1.5-2x your calculated API cost for the first six months.
3. Is Vertex AI cheaper than AWS Bedrock?
At the budget tier, yes. Gemini 2.5 Flash-Lite at $0.10 per million input tokens is the cheapest production-grade model from any major provider, significantly cheaper than Amazon Nova Micro at $0.035 for output but more expensive on input. At the flagship tier, Gemini 2.5 Pro ($1.25/$10.00) and Claude Sonnet 4.6 on Bedrock ($3.00/$15.00) are not directly comparable because they are different models. Vertex AI’s hidden cost risk is the 200K token context cliff (doubles input pricing above 200K tokens), idle endpoint charges, and data egress. Bedrock’s hidden cost risk is Knowledge Base vector storage, agent token amplification, and cross-region surcharges. For typical enterprise applications processing 10-50 million tokens monthly, AWS Bedrock generally provides 15-25% lower all-in costs than Azure, with Vertex AI competitive on pure token rates depending on model selection.
4. What are Azure OpenAI Provisioned Throughput Units (PTUs) and when do they make sense?
PTUs are Azure OpenAI’s commitment purchasing model; you pay an hourly rate for reserved inference capacity instead of per-token rates. PTU pricing delivers up to 40% savings over pay-as-you-go rates for high-volume users. The break-even point is approximately 300,000 tokens per minute running consistently for 8+ hours per day. Below this threshold, on-demand pricing is cheaper. Minimum commitment: approximately $2,448 per month per unit. PTUs are frequently over-purchased by teams that commit before they have 30 days of production traffic data. Underutilized PTU capacity carries no refund mechanism, you pay the committed rate regardless of actual usage.
5. How does prompt caching reduce LLM costs on Bedrock, Vertex AI, and Azure OpenAI?
Prompt caching stores repeatedly used input tokens (system prompts, persona instructions, document preambles) and charges only 10% of the standard input rate for cached content. All three platforms support prompt caching for flagship models. The savings compound for stateful applications: a chatbot that re-sends a 10,000-token system prompt with every request pays the full input rate on each call without caching. With caching, only the first call pays full input price, subsequent calls pay 10%. For a production endpoint handling 1 million requests per month with a 5,000-token system prompt, prompt caching saves approximately $14,500 per month at Claude Sonnet 4.6 rates. The 1-hour cache TTL for Claude models launched January 2026 on Bedrock makes this dramatically more effective for sustained production traffic.
6. What happens to my commitment if my LLM workload scales down?
With native AWS Savings Plans, GCP CUDs, or Azure PTUs/Reserved Instances, you pay the committed rate regardless of actual usage. There is no refund, buyback, or adjustment mechanism. Underutilized commitment charges accrue in full. Usage.ai’s Insured Flex Commitments work differently: commitments adjust quarterly, scale down with no penalty, and underutilized portions are returned as cashback in real money, not credits. This removes the primary financial risk of commitment purchasing for AI infrastructure workloads where usage patterns evolve as model architectures and application requirements change.
7. Can I get commitment discounts on LLM workloads across AWS, GCP, and Azure simultaneously?
Natively, no. AWS Savings Plans apply to AWS only. GCP CUDs apply to GCP only. Azure Reserved Instances apply to Azure only. Managing commitments separately across three clouds requires three separate FinOps workflows with three incompatible billing formats. Usage.ai covers all three clouds in a single platform, with Insured Flex Commitments that provide commitment-level discounts on cloud compute across AWS, GCP, and Azure with one interface, one recommendation refresh cycle, and one fee model (percentage of realized savings only).
8. Which platform is best for regulated industries with FedRAMP High requirements?
AWS Bedrock and Azure OpenAI both have FedRAMP High authorization for US federal and regulated industry workloads. Vertex AI’s FedRAMP High authorization is in progress but not yet generally available as of June 2026 — making it off the table for some US federal workloads. For HIPAA-covered healthcare workloads, all three platforms support BAA coverage with private VPC endpoint configurations. For financial services organizations with Azure-approved procurement lists, Azure OpenAI is the practical default regardless of per-token price comparisons.