.png)


You are good at shipping fast. That is the whole point of DevOps. But somewhere between “move fast” and “scale automatically, the cloud bill starts to move faster than the product.
The irony is that DevOps teams are both the cause and the cure. The same CI/CD pipelines that make you fast also make it trivially easy to spin up infrastructure that nobody cleans up. The same automation that removes manual bottlenecks also removes the friction that used to slow down runaway spend.
This guide gives you nine DevOps best practices that treat cloud cost as a first-class engineering metric, not an afterthought for finance. Each practice includes what it does, how to implement it, and what it costs your organization to skip it. You will also get a vendor-neutral tool comparison, a decision tree to help you prioritize, a dedicated section on the emerging AI and ML cost challenge, and a maturity model to map where your team stands today.
What Are DevOps Best Practices for Cloud Cost Management?
DevOps best practices for cloud cost management are the engineering behaviors, automation workflows, and cultural norms that embed financial accountability directly into the software delivery lifecycle. In the cloud, every architectural decision has an immediate and measurable cost consequence. A misconfigured autoscaling group, a forgotten staging environment, or a batch job running on on-demand compute instead of Spot can cost thousands of dollars per month before anyone notices.
The intersection of DevOps and FinOps, the practice of applying financial accountability to cloud operations, is where these practices live. The FinOps Foundation defines three core phases: Inform (get visibility into spend), Optimize (reduce waste and right-size resources), and Operate (embed cost governance into recurring team workflows). The nine practices in this guide map directly to those phases.
Why “move fast” became “spend fast” and the DevOps cost paradox
CI/CD was designed to remove friction from the path from code to production. It does that brilliantly. The problem is that it also removes friction from the path between a terraform apply command and a $15,000 monthly infrastructure bill.
When any engineer can spin up a Kubernetes cluster, a managed database, and a load balancer in a single pull request with no cost review, and when that pull request merges automatically if tests pass, the financial blast radius of a bad architectural decision is enormous.
The practices below exist to restore financial visibility without restoring friction. The goal is to make cost visible before it becomes a problem, so that engineers can make better decisions with full information.
The 9 DevOps Best Practices That Cut Cloud Costs in 2026
Practice 1: Enforce Mandatory Tagging via Infrastructure as Code from Day One
What it is: Resource tagging is the foundation of cloud cost attribution. Without tags, spend is unattributable. You cannot show a team their costs, enforce chargeback, or even identify which environment a resource belongs to. Mandatory tagging means every resource in your cloud environment is labeled with a minimum tag set, such as team, environment, project, and cost-center, enforced automatically at deployment time via Infrastructure as Code.
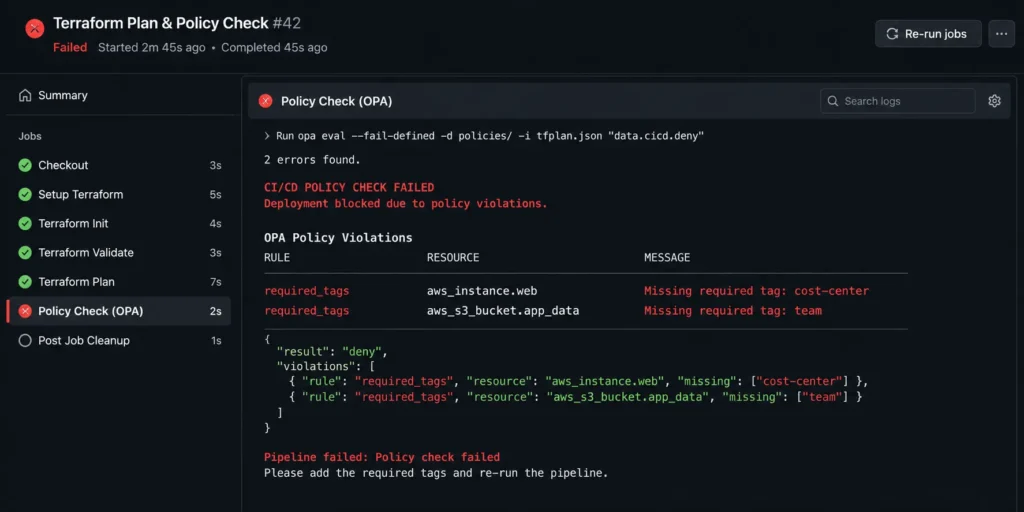
How to implement it: Use Open Policy Agent (OPA) or AWS Service Control Policies to block any Terraform apply that does not include required tags. A simple OPA policy can check every resource block for a defined tag set before the plan is approved in CI. For teams already using Terraform Cloud or Atlantis, tag enforcement can be added as a sentinel policy or a pre-plan hook.
Cost of skipping it: Without tags, you cannot attribute cloud spend to the teams generating it. Chargeback is impossible. Showback is inaccurate. Rightsizing recommendations cannot be mapped to owners. In practice, untagged resources accumulate because no one is accountable for them. A single forgotten database cluster can run for months at $800 to $3,000 per month before it appears in a cost review.
Practice 2: Embed Cost Estimation in Your CI/CD Pipeline
What it is: Cost estimation in CI/CD means that every infrastructure pull request automatically includes a projected monthly cost delta before it is merged. Engineers see the cost impact of their changes the same way they see test results and linting warnings: inline, before merge.
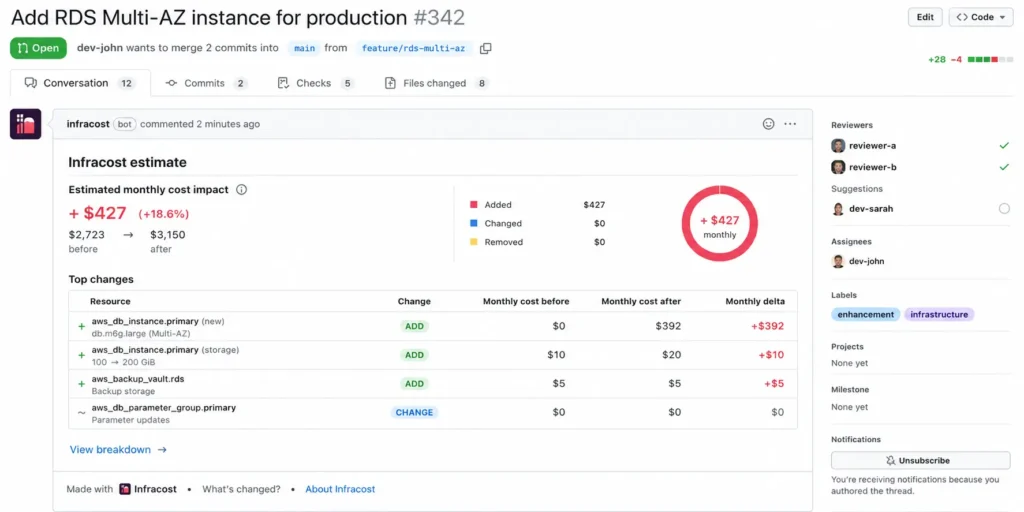
How to implement it: Infracost is the most widely adopted open-source tool for this. It integrates with GitHub Actions, GitLab CI, CircleCI, and most other CI systems. When a pull request changes Terraform code, Infracost comments on the PR with a before-and-after cost table. A change that adds an RDS Multi-AZ instance shows the projected $400 monthly increase before a reviewer approves the merge.
Cost of skipping it: Infrastructure cost surprises happen post-merge, when reverting is expensive and disruptive. Teams that lack pre-merge cost visibility routinely discover overprovisioned databases, unnecessary NAT gateway configurations, and bloated ECS task definitions only when the monthly bill arrives. By that point, the cost has already been incurred, and reverting requires engineering time, a new deployment cycle, and potential downtime risk.
Practice 3: Implement Showback Before Chargeback
What it is: Showback is the practice of reporting cloud costs to individual teams without financially penalizing them. Each team sees a dashboard that attributes spend to their services and environments. Chargeback goes one step further: actual cost is transferred to the team’s budget. Showback should always come first, because it builds cost literacy and buy-in before financial accountability creates friction.
How to implement it: AWS Cost Explorer, Azure Cost Management, and GCP Billing allow you to filter and group costs by tag. Tools like Kubecost provide Kubernetes-native cost attribution at the namespace and workload level. The key is building a regular reporting cadence, weekly cost reports per team, so that engineers develop an intuition for the cost of their infrastructure decisions.
For organizations looking to go beyond native cloud tools, Usage.ai provides cross-cloud visibility with team-level cost attribution built on your existing tag structure. Read their guide to AWS billing and cost management for a detailed walkthrough of the visibility layer.
Cost of skipping it: Without showback, engineers have no baseline for what their services cost. There is no psychological anchor that makes a $20,000 monthly jump feel alarming. Teams that skip the visibility phase and jump straight to optimization often optimize the wrong things because they lack the attribution data to identify where the real waste lives.
Practice 4: Automate Environment Cleanup with Lifecycle Policies
What it is: Development, staging, and review environments are the single largest source of avoidable cloud waste. These environments are created on demand, often for a specific sprint or feature branch, and then left running indefinitely because no one owns the cleanup. Automated lifecycle policies schedule environment shutdown outside of business hours and destroy branch environments automatically when their associated pull request closes.
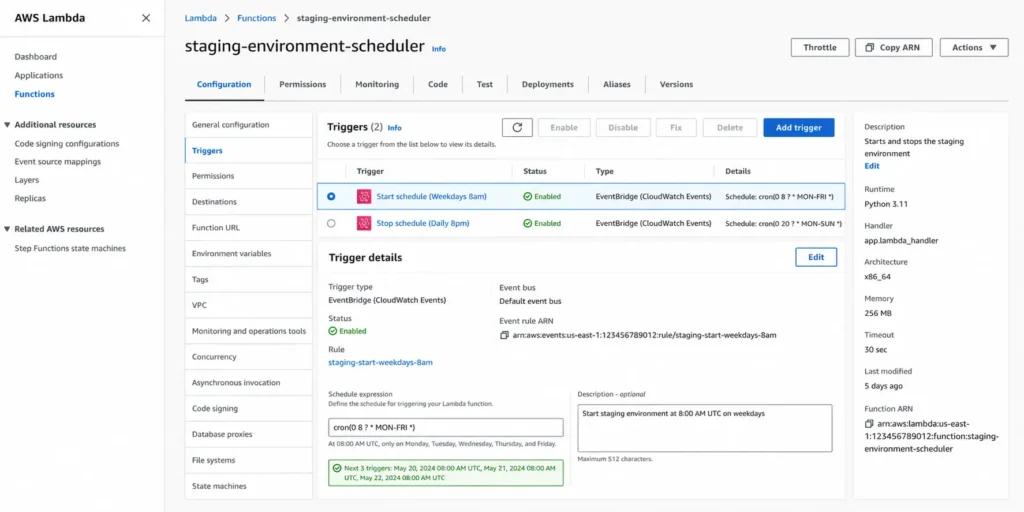
How to implement it: AWS Lambda schedulers can stop EC2 instances, RDS clusters, and ECS services on a defined schedule, such as 8pm to 8am on weekdays, plus all day Saturday and Sunday. Terraform destroy can be triggered automatically by a GitHub Actions workflow when a feature branch is merged or closed. For Kubernetes, tools like kube-janitor can delete namespaces that match a label after a configurable time-to-live.
A simple calculation: if a staging environment costs $3,200 per month running 24/7, shutting it down for 65 hours per weekend and 13 hours per weeknight saves approximately 57% of that cost, or roughly $1,800 per month per environment.
Cost of skipping it: A development environment running 24/7 consumes 720 hours of compute per month. A well-configured lifecycle policy cuts that to approximately 310 hours for a standard weekday-only schedule. Across five to ten environments, that is $5,000 to $20,000 in avoidable monthly spend.
Practice 5: Rightsize Continuously, Not Quarterly
What it is: Rightsizing is the process of matching compute instance size to actual workload requirements, rather than provisioning for theoretical peak capacity. Most cloud resources are provisioned generously at launch and never revisited. A server that handled 10,000 requests per hour at launch might now handle 2,000, but still runs on the same instance type.
How to implement it: AWS Compute Optimizer analyzes CloudWatch metrics for EC2, RDS, ECS, and Lambda, and generates rightsizing recommendations. Azure Advisor provides equivalent analysis for Azure Virtual Machines and databases. GCP Recommender covers Compute Engine instances and managed databases.
The DevOps best practice here is to treat rightsizing as a sprint ritual rather than an annual audit. Add a monthly step to your sprint retrospective: review the top ten rightsizing recommendations from your cloud provider, assign owners, and track completion. This connects directly to your monitoring practices. You cannot rightsize what you cannot observe, which is why devops monitoring best practices and rightsizing are inseparable.
Cost of skipping it: AWS reports that the average organization running EC2 workloads is significantly overprovisioned at baseline. Moving from a m5.4xlarge to a m5.2xlarge for a service averaging 25% CPU utilization saves approximately $1,400 per year per instance in us-east-1. At ten instances, that is $14,000 per year in avoidable spend from a single optimization pass.
Practice 6: Use Spot and Preemptible Instances for Fault-Tolerant Workloads
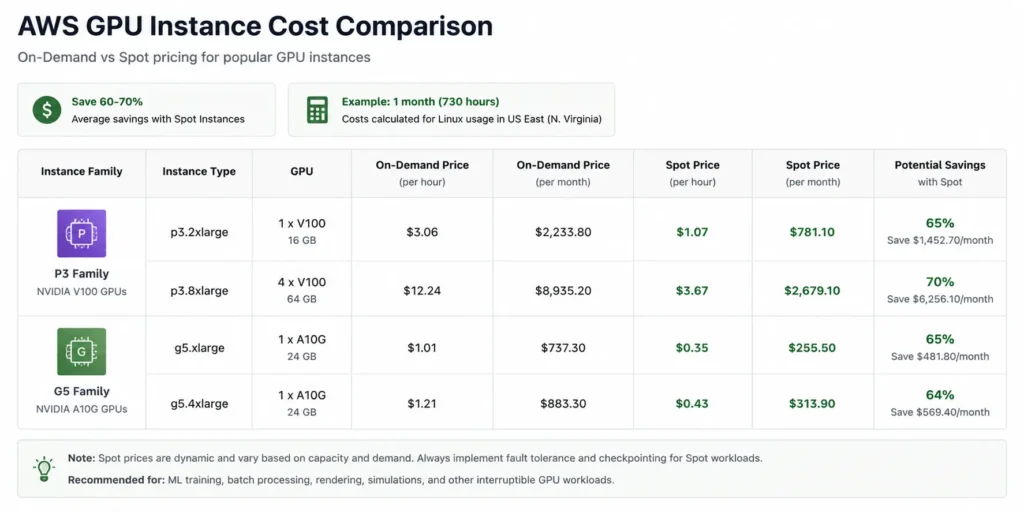
What it is: Cloud providers offer deep discounts of 60 to 90% on spare capacity through Spot Instances (AWS), Preemptible VMs (GCP), and Spot VMs (Azure). The trade-off is that these instances can be interrupted with short notice. For stateless, fault-tolerant workloads, this trade-off is entirely acceptable. For stateful or latency-sensitive production services, it is not.
How to implement it: The following workload categories are well-suited for Spot and Preemptible instances:
- CI/CD build agents and test runners
- Batch processing and ETL jobs
- AI and ML training jobs (see Section 5)
- Data pipeline workers
- Non-critical background processing
The following workloads should remain on on-demand or Reserved capacity:
- Production databases with synchronous replication requirements
- Single-AZ services without automatic failover
- Latency-sensitive APIs with SLA commitments
For CI/CD specifically, GitHub Actions with self-hosted runners on Spot instances, or tools like GitLab with auto-scaling Spot runners, can cut your CI compute bill by 60 to 80% with minimal engineering effort.
Cost of skipping it: A team running dedicated on-demand instances for CI/CD workloads that run 40 hours per week might spend $2,000 to $6,000 per month on build compute. The equivalent Spot capacity typically costs $400 to $1,200 per month.
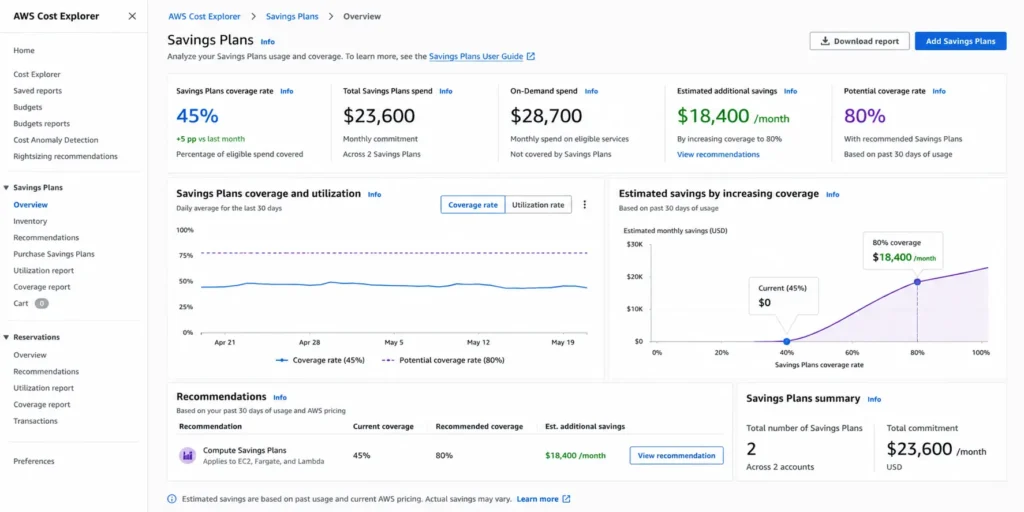
Practice 7: Commit Strategically with Reserved Instances and Savings Plans
What it is: Cloud providers offer significant discounts, up to 66% for Savings Plans and up to 72% for standard Reserved Instances, in exchange for a commitment to a defined usage level over one or three years. Savings Plans are flexible and apply across compute services regardless of instance type. Reserved Instances offer deeper discounts but require you to specify the instance family, region, and operating system.
How to implement it: The decision between Savings Plans and Reserved Instances depends on your workload stability and forecasting accuracy.
Use Savings Plans when:
- Your compute footprint changes frequently due to rightsizing, migrations, or architectural evolution
- You run a mix of EC2, Lambda, and Fargate
- You cannot forecast usage within 10% accuracy over 12 months
Use Reserved Instances when:
- Your instance type and configuration are highly stable
- You are running managed databases (RDS, ElastiCache) where Reserved Instances offer specific discounts
- You have accurate long-term capacity forecasts
For a deeper breakdown of the math, see Usage.ai’s AWS Savings Plans vs Reserved Instances comparison, which covers the exact scenarios where each approach delivers better outcomes.
One important nuance: a Reserved Instance running at 70% utilization delivers less real savings than a Savings Plan at 100% utilization, even if the RI carries a higher nominal discount rate. Underutilization erodes the benefit of deeper discount rates.
Cost of skipping it: Fewer than half of organizations use any given discount program across AWS, Azure, or GCP, according to Flexera’s 2026 data. An organization spending $50,000 per month on AWS on-demand compute that is eligible for Savings Plans coverage is leaving roughly $15,000 to $25,000 per month on the table.
Practice 8: Set Up Anomaly Detection Before You Need It
What it is: Cloud cost anomalies are not a matter of if, they are a matter of when. A misconfigured autoscaling policy, an accidental data transfer to a different region, or a forgotten large-scale batch job can generate thousands of dollars in unexpected charges within hours. Anomaly detection tools monitor your cloud spend continuously and alert you when spend deviates significantly from expected patterns.
How to implement it: AWS Cost Anomaly Detection is a native AWS tool that monitors spend by service, linked account, or tag group, and sends alerts when spend deviates from learned baselines. Configure it with percentage and absolute dollar thresholds, and route alerts to your engineering Slack channel or incident management system. Azure has Budget Alerts for threshold-based monitoring and Advisor for recommendation-based alerts. GCP provides Budget Alerts with percentage-based and fixed-amount triggers.
For teams that need cross-cloud anomaly detection with more granular attribution, Usage.ai continuously monitors spend patterns across AWS, GCP, and Azure and surfaces anomalies at a workload level, not just at the billing account level.
The devops monitoring best practices that govern service reliability, alerting thresholds, on-call escalation, and runbooks apply directly here. Cost anomaly detection should be treated as an operational signal with the same urgency as a performance degradation alert.
Cost of skipping it: A data transfer misconfiguration generating $800 per day takes 30 days to appear on a monthly bill review, resulting in $24,000 in avoidable spend. With anomaly detection and a 24-hour alert latency, the same incident costs $800. Alert fatigue is real, so configure thresholds thoughtfully: a 20% deviation alert on a $500/month service is noise; a 20% deviation alert on a $50,000/month service is critical.
Practice 9: Treat Cost as an Engineering Metric in Sprint Ceremonies
What it is: The most durable cost reduction comes from cultural change, not tooling. When cost is visible alongside latency, error rate, and uptime in engineering dashboards, it becomes part of the mental model that engineers use to evaluate trade-offs. When cost is discussed in sprint planning and retrospectives, architectural decisions with cost implications get surfaced before they become technical debt.
How to implement it: Add a 10-minute cost review to your monthly retrospective. Use showback data from Practice 3 to review the top three cost movers for the sprint. Ask two questions: “Did we expect this cost increase?” and “Is there an optimization opportunity we can schedule next sprint?” Embed cost metrics in the same observability dashboards your teams already monitor. A Grafana panel showing the estimated hourly cost of a service alongside its request rate and error rate is a simple and effective way to make cost visible without changing workflows.
This is the FinOps Foundation’s definition of the Operate phase: embedding financial accountability into the engineering culture so that cost optimization is a continuous practice, not a quarterly fire drill.
Cost of skipping it: Teams that never discuss cost in engineering contexts consistently overprovision because there is no cultural pressure to optimize. Overprovisioning at scale is expensive: a team consistently running at 30% of provisioned capacity across a $200,000 monthly cloud bill is paying for $140,000 worth of compute they are not fully using.
DevOps Cloud Cost Management Tools: A Neutral Comparison
The table below compares tools commonly used by DevOps and FinOps teams for cloud cost management. This is not a ranking. Each tool has specific strengths, and the right choice depends on your cloud setup, team maturity, and existing toolchain.
| Tool | Best for | Cloud coverage | RI/SP optimization | Anomaly detection | CI/CD integration | Pricing model |
| AWS Cost Explorer | AWS-native visibility and rightsizing | AWS only | Savings Plans recommendations | Yes (Cost Anomaly Detection) | No native integration | Included with AWS |
| Azure Cost Management | Azure-native visibility and budgets | Azure + limited multi-cloud | Azure Reservations recommendations | Yes (Budget Alerts) | No native integration | Included with Azure |
| Usage.ai | Autonomous RI/SP optimization and cross-cloud commitment management | AWS, Azure, GCP | Yes, fully autonomous daily purchasing | Yes | No | Percentage of realized savings |
| Kubecost | Kubernetes cost attribution | Kubernetes on any cloud | No | Limited | No | Open source + paid tiers |
| Infracost | Pre-merge IaC cost estimation | AWS, Azure, GCP | No | No | Yes, native CI/CD | Open source + paid tiers |
| CloudZero | Unit economics and cost-per-customer attribution | AWS, Azure, GCP | No autonomous purchasing | Yes | No | Annual contract |
How to pick the right tool for your team’s maturity level
Crawl (beginning your cost management journey): Start with native cloud tools. AWS Cost Explorer and Azure Cost Management are free, already connected to your billing data, and sufficient to establish baseline visibility. Pair them with Infracost in your CI/CD pipeline to get pre-merge cost awareness.
Walk (building automation and attribution): Add Kubecost if you run Kubernetes workloads at scale. Begin exploring Reserved Instance or Savings Plan commitments manually using the recommendations from AWS Cost Explorer or Azure Advisor. Consider CloudZero if your primary need is unit economics and cost-per-feature attribution.
Run (optimizing commitments and cross-cloud governance): At this stage, manual commitment management becomes untenable. Usage.ai’s autonomous cloud management layer continuously purchases and rebalances commitments across AWS, GCP, and Azure based on actual usage, not forecasts. It operates with read-only billing access plus a scoped role to execute purchases, so your workloads and production infrastructure are never accessed. For teams that prefer manual approval before any commitment purchase, Usage.ai’s CoPilot mode surfaces recommendations for review before execution.
Decision Tree: Which DevOps Cost Practice Should You Implement First?
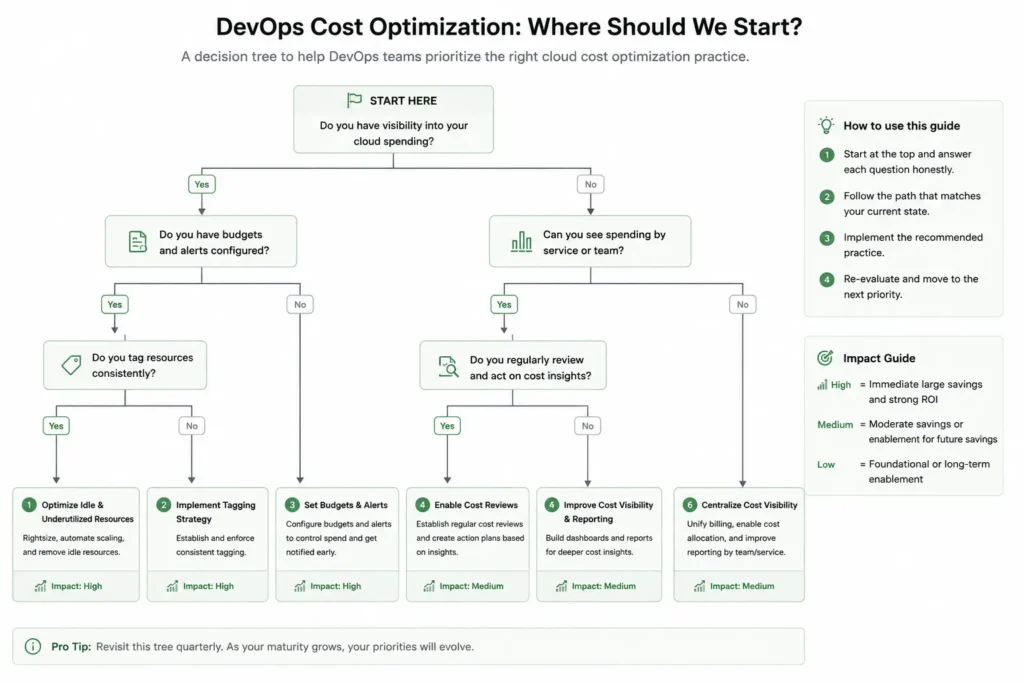
One of the most common questions from teams starting their cloud cost optimization journey is: “Where do we begin?” The answer depends entirely on your current maturity. Use this decision tree to find your starting point.
1. Do you have mandatory resource tagging enforced in CI/CD?
No: Start with Practice 1 (mandatory tagging via IaC). Without tagging, every downstream practice is limited. You cannot attribute costs, enforce showback, or identify waste by owner. Tagging is the prerequisite for everything else.
Yes: Continue to the next question.
2. Can you see which team or service is generating each dollar of cloud spend?
No: Start with Practice 3 (showback dashboards). Build cost attribution using your existing tags and a reporting tool. You need this baseline before you can identify where waste lives.
Yes: Continue to the next question.
3. Do you have idle or over-provisioned resources (development environments left on, instances at under 30% CPU)?
Yes: Address Practice 4 (environment lifecycle automation) and Practice 5 (continuous rightsizing) in parallel. These two together typically reduce cloud waste by 15 to 25% within 30 days.
No: Continue to the next question.
4. Do you experience unexpected cost spikes or significant month-to-month variance?
Yes: Implement Practice 8 (anomaly detection) immediately. Unexpected variance is the most expensive cloud cost problem because it is invisible until the bill arrives.
No: Continue to the next question.
5. Do you have a stable, predictable compute baseline that runs 24/7?
Yes: This is the right time to implement Practice 7 (Reserved Instances and Savings Plans). Commitments make sense when you have stable, observable baselines. Committing before this point creates underutilization risk.
No: Focus on Practice 6 (Spot instances for fault-tolerant workloads) and revisit commitments once your baseline stabilizes.
DevOps Best Practices for AI and ML Cloud Costs: The 2026 Addition
No DevOps best practices guide written in 2026 is complete without addressing AI and ML workloads. The Flexera 2026 State of the Cloud Report identifies AI cost management as the primary driver of the uptick in cloud waste this year, and the FinOps Foundation’s 2026 State of FinOps report names it the top emerging priority for FinOps teams at every spending level.
The problem with AI and ML workloads is that they break the assumptions underlying most traditional cloud cost optimization strategies.
The GPU idle time problem: GPU idle time averages 77% across measured workloads. GPU instances on AWS (P3, P4, G5 families) and GCP (A100, H100 nodes) are among the most expensive compute resources available. Paying on-demand rates for GPU capacity that sits idle 77% of the time is the equivalent of leaving high-end servers in a datacenter powered on with nothing running.
What DevOps teams should do for AI/ML costs:
Use Spot and Preemptible instances for AI training jobs. Training runs are batch workloads: they have a defined start and end, they can checkpoint progress, and they tolerate interruption. This is precisely the workload profile Spot was designed for. The savings are 60 to 90% compared to on-demand GPU pricing. Also read: On-Demand vs Reserved vs Spot Instances.
Keep inference workloads on on-demand or Reserved capacity. Inference serving is latency-sensitive and continuous. It is not a good fit for Spot. For stable inference workloads, Reserved GPU instances or Savings Plans coverage is appropriate.
Instrument model inference cost per query. This is the AI/ML equivalent of cost-per-request attribution. Teams running large language model inference or image generation APIs should track the cost of each inference call alongside its latency and error rate. This data is essential for product pricing decisions and architecture trade-offs between model size and cost efficiency.
DevOps FinOps Maturity Model: Crawl, Walk, Run
The nine practices in this guide are not all equally urgent. Your starting point depends on where your organization sits in the FinOps maturity model. The framework below maps each practice to a maturity tier so you can sequence your implementation realistically.
Crawl: Establish Visibility (Months 1 to 3)
At the Crawl stage, the goal is to get basic cost visibility in place and stop the most obvious bleeding.
Priority practices:
- Practice 1: Mandatory tagging (prerequisite for everything)
- Practice 3: Showback dashboards (so teams can see their costs)
- Practice 4: Environment cleanup automation (highest immediate ROI)
Teams at this stage typically find 15 to 25% in addressable waste just by implementing tagging and cleaning up idle environments.
Walk: Build Automation (Months 3 to 9)
At the Walk stage, you have baseline visibility and you are building the automation layer that makes cost optimization a continuous process rather than a periodic effort.
Priority practices:
- Practice 2: CI/CD cost estimation with Infracost
- Practice 5: Continuous rightsizing as a sprint ritual
- Practice 6: Spot instances for CI/CD and batch workloads
- Practice 8: Anomaly detection with alerting
Run: Optimize Commitments and Culture (Months 9 and Beyond)
At the Run stage, your infrastructure is lean, your costs are visible and attributed, and you are ready to capture the largest single source of savings available: commitment-based discounts on your predictable baseline.
Priority practices:
- Practice 7: Reserved Instances and Savings Plans (or Usage.ai’s automated commitment optimization for teams that prefer not to manage this manually)
- Practice 9: Cost as an engineering metric in sprint ceremonies
- AI/ML cost governance (Section 5 practices)
The FinOps Foundation’s 63% FinOps team adoption rate from the Flexera 2026 report suggests that most organizations are in the transition between Crawl and Walk. If that describes your team, Practices 1 through 4 are your immediate priority.
Conclusion
Cloud cost management is not a FinOps team problem. It is a DevOps problem, because the teams deploying infrastructure are the teams generating spend. The nine practices in this guide embed cost accountability into the workflows engineers already use: pull requests, sprint ceremonies, CI/CD pipelines, and infrastructure automation.
The path from where most organizations are today (Crawl: basic visibility, lots of idle waste) to where they need to be (Run: automated commitments, cost-aware culture) is not a single project. It is a sequence of improvements, each building on the last. Start with tagging and environment cleanup. Build showback dashboards. Add CI/CD cost estimation. Introduce rightsizing as a sprint ritual. Then, once your baseline is stable and visible, capture the commitment discounts that turn a good cloud cost posture into an excellent one.
For organizations ready to automate the commitment layer, Usage.ai continuously purchases and rebalances Reserved Instances, Savings Plans, and Committed Use Discounts across AWS, GCP, and Azure, based on actual usage patterns rather than manual forecasts. Most teams see 30 to 50% savings on covered workloads. See how it works.

Frequently Asked Questions
1. What are the most important DevOps best practices for reducing cloud costs?
The highest-ROI DevOps best practices for cloud cost reduction are: mandatory resource tagging enforced via Infrastructure as Code, automated cleanup of idle development and staging environments, continuous rightsizing of compute resources, and Spot instance usage for fault-tolerant workloads like CI/CD pipelines and batch jobs. These four practices together typically reduce cloud waste by 20 to 35% within the first 90 days.
2. What is the difference between FinOps and DevOps?
DevOps is an engineering methodology focused on shortening the software delivery cycle through automation, collaboration, and continuous delivery. FinOps is a financial operations practice focused on embedding cost accountability into cloud engineering workflows. The two are complementary: DevOps provides the automation capabilities, and FinOps provides the financial discipline. In practice, a mature cloud engineering organization applies both, treating cost as a first-class engineering metric alongside availability, latency, and reliability.
3. How do I implement cost visibility in a DevOps pipeline?
Start with two tools: Infracost for pre-merge infrastructure cost estimation in CI/CD, and your cloud provider’s native cost management tool (AWS Cost Explorer, Azure Cost Management, or GCP Billing) for post-deployment visibility. Tag every resource with team, environment, and project identifiers so that costs can be attributed by owner. Build a weekly cost report for each team using tag-based filtering. This combination gives you both forward-looking cost awareness at the PR level and retrospective attribution for continuous improvement.
4. When should I use Spot instances vs Reserved Instances?
Use Spot instances for stateless, fault-tolerant workloads that can tolerate interruption: CI/CD agents, batch processing jobs, AI/ML training, and background processing workers. Spot instances typically save 60 to 90% compared to on-demand pricing. Use Reserved Instances for your stable, predictable baseline compute: persistent databases, production API servers with consistent load, and any workload where interruption causes customer-facing impact. For a detailed comparison of Savings Plans vs Reserved Instances, see Usage.ai’s breakdown.
5. What DevOps tools help with cloud cost management?
The core toolkit for DevOps cloud cost management is: Infracost (pre-merge IaC cost estimation), OPA or AWS Service Control Policies (tag enforcement), AWS Cost Explorer, Azure Cost Management, or GCP Billing (native visibility), Kubecost (Kubernetes-specific cost attribution), and a commitment optimization layer for RI and Savings Plans management. See the full tool comparison at Usage.ai for a current vendor-neutral breakdown covering AWS, Azure, and GCP options across each optimization category.