.png)


Cloud cost optimization best practices in 2026 combine three layers: visibility, waste reduction, and commitment coverage to reduce cloud bills by 30–50% without degrading performance or requiring code changes. If your company spends $5 million a year on cloud infrastructure, there is a strong chance $1.25–$1.75 million of it is wasted. Cloud waste is structural and it compounds faster than most teams can manually correct it.
Public cloud spending grew 21.5% in 2025, according to Gartner, yet managing cloud spend remains the top challenge for 85% of organizations (Flexera 2026 State of the Cloud Report). Meanwhile, traditional optimization efforts take six to nine months to fully implement by which time hundreds of thousands of dollars in preventable overpayment have already accumulated.
In this guide, we break down 20 cloud cost optimization best practices covering visibility, waste reduction, and commitment coverage that move beyond dashboards and into measurable, sustained savings.
What Is Cloud Cost Optimization?
Cloud cost optimization is the practice of applying structured best practices to reduce on-demand cloud spend, increase discounted commitment coverage, and eliminate structural waste across AWS, Azure, and GCP without degrading performance or slowing engineering teams.
Most cloud bills divide into two categories: on-demand spend (flexible, pay-as-you-go with no commitment) and committed spend (discounted pricing in exchange for a usage commitment e.g., AWS Savings Plans, Reserved Instances, Azure Reservations, GCP Committed Use Discounts). Organizations that focus only on deleting idle resources typically reduce costs by 10–20%. Teams that also optimize commitment coverage while managing risk can often achieve 30–50% reductions without changing a line of application code.
What Is FinOps, and How Does It Relate?
FinOps is a cultural and operational framework that brings together finance, engineering, and operations teams to manage cloud spend as a shared business discipline. It is not a tool, it is a practice. Cloud cost optimization is the execution layer of FinOps: the specific actions and best practices that produce measurable savings within a FinOps-governed environment. The FinOps Foundation is the industry body that defines the FinOps Framework and its maturity model.
FinOps teams mature through three stages: Crawl (gaining visibility), Walk (acting on recommendations at scale), and Run (automating optimization and managing unit economics). The cloud cost management best practices in this guide apply equally to single-cloud, multi-cloud, and hybrid cloud environments.
Why Cloud Costs Spiral Out of Control
Cloud costs spiral because most organizations never revisit the pricing model they started with. Every new resource defaults to on-demand pricing, commitments feel risky without accurate usage data, and quarterly review cycles let coverage gaps compound for months before anyone acts.
The on-demand pricing trap. For predictable baseline workloads, on-demand pricing carries a 30–60% premium over committed rates and when teams provision new infrastructure and never revisit the pricing model, that premium compounds silently every billing cycle.
The commitment hesitation problem. Traditional AWS Reserved Instances and Savings Plans require 1- or 3-year lock-ins. For fast-moving organizations, that perceived lock-in creates hesitation that translates directly into structural overpayment. A 10% coverage shortfall on a $5M cloud bill represents $500,000 in annualized exposure.
The quarterly review bottleneck. When commitment decisions are revisited every 90 days, coverage gaps remain unresolved for entire billing cycles. The solution is not a bigger spreadsheet, it is a daily recommendation cadence.
The 3 Categories of Cloud Cost Optimization Best Practices
In practice, cloud cost optimization falls into three distinct categories. Each builds on the previous one and each unlocks a different level of savings.
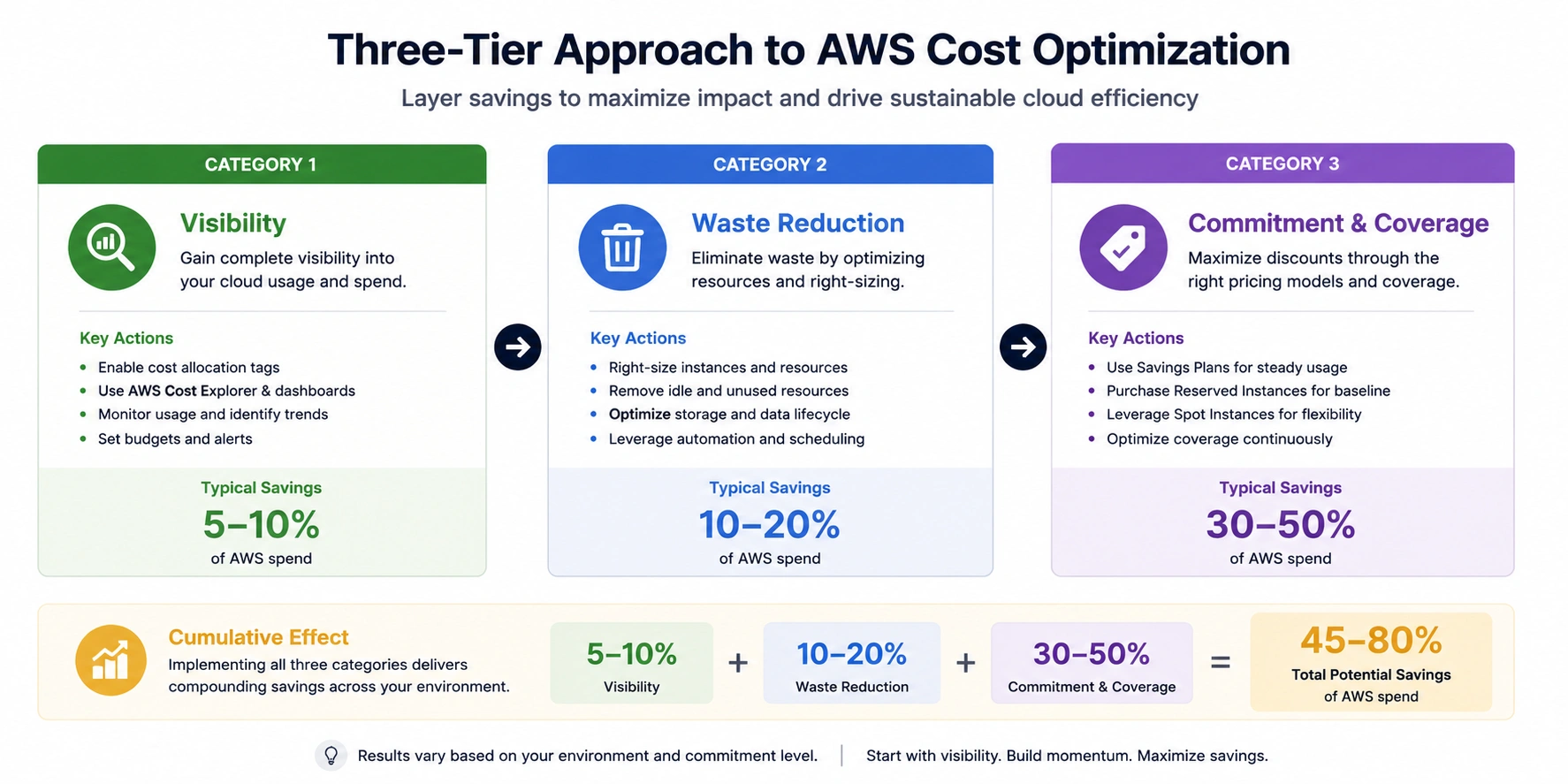
| Category | Focus | Typical Savings |
| Visibility | Cost allocation, tagging, spend tracking | 5–10% |
| Waste Reduction | Idle resources, rightsizing, non-prod scheduling | 10–20% |
| Commitment & Coverage | Savings Plans, RIs, CUDs, coverage rate management | 30–50% |
Category 1: Visibility Best Practices (Typically 5–10% Savings)
The first layer of cloud cost optimization best practices focuses on visibility and accountability. You cannot optimize what you cannot see.
Visibility best practices expose where structural overpayment lives. In most mid-market cloud environments ($1M–$10M annual spend), this layer unlocks 5–10% savings and prevents larger mistakes downstream.
Practice 1: Identify the Top 3 Services Driving 70–80% of Spend
Stop optimizing line items. Focus on optimizing concentration.
In nearly every multi-cloud environment, compute (EC2 / Azure VMs / GCE) dominate, databases (RDS, Azure SQL, Cloud SQL) follow, and Kubernetes or storage sits next. Any service representing more than 20% of total spend deserves dedicated optimization modeling.
If you cannot answer, what percentage of spend is compute? What percentage of computers are on-demand? Which region carries the largest baseline load? you are not ready for advanced optimization.
Practice 2: Enforce ≥90% Tagging Compliance
If tagging compliance falls below 90%, cost allocation reports become statistically unreliable.
At that point, chargeback breaks, accountability disappears, forecasting accuracy drops, and engineering shrugs at overruns.
Minimum viable tag set: Owner, Environment (prod/staging/dev), Application/workload, Cost center.
If tagging isn’t automated at provisioning time (via Terraform, ARM templates, or policy-as-code using OPA, Sentinel, or AWS SCPs), it will degrade within a quarter. Enforce deploy and block non-compliant resources no soft fails.
Practice 3: Track On-Demand Exposure, Not Just Total Spend
Most dashboards show total spend that is the wrong metric.
Instead, track what percentage of predictable workloads are still running on on-demand pricing. If 40–50% of baseline compute runs on-demand, you are structurally overpaying even if utilization looks healthy.
Example: $3M annual compute spend × 45% on-demand × 30–50% potential discount = a six-figure optimization opportunity before deleting a single instance.
Visibility must also include: commitment coverage %, on-demand vs. committed breakdown, and baseline vs. burst classification. If you are not tracking coverage weekly, you are already behind.
For multi-cloud environments, the FinOps Open Cost and Usage Specification (FOCUS) provides a vendor-neutral billing data schema that normalizes cost and usage data across AWS, Azure, and GCP into a consistent, queryable format making cross-cloud on-demand exposure analysis materially easier to implement.
Practice 4: Measure Unit Economics (Cost Per Workload)
Unit economics connect cloud spend to business outcomes and turn abstract billing data into actionable signals.
Cost per order, cost per API call, cost per inference, cost per GB transferred, these metrics reveal whether spending is scaling efficiently or simply growing. At the FinOps “Run” maturity stage, unit economics become the primary lens for all cloud financial decisions.
Start with one customer-facing service: divide its attributable cloud cost by the relevant output metric (orders, requests, jobs). That ratio is your unit cost baseline. Track it monthly.
Practice 5: Install Anomaly Detection with Action Ownership
An alert without ownership is noise.
Effective anomaly detection requires a threshold definition (e.g., 15% week-over-week increase), an assigned owner, and a defined remediation playbook. Watch for sudden regional expansion, Kubernetes node scaling anomalies, storage growth creep, and commitment coverage dips. Most anomalies are not catastrophic spikes; they are a slow creep of 3–5% monthly growth that compounds into six figures annually.
Category 2: Waste Reduction Best Practices (Typically 10–20% Savings)
The second layer focuses on actively eliminating structural waste. This is where most engineering-driven optimization happens and where many teams mistakenly believe they are “fully optimized.” Waste reduction removes inefficiency but does not address structural pricing; that comes in Category 3.
Practice 6: Eliminate Idle and Zombie Resources
Idle resources accumulate continuously in any active cloud environment.
Common offenders: instances with 0–5% utilization over 7+ consecutive days, detached EBS volumes, orphaned snapshots, load balancers without active targets, and Kubernetes nodes running without active pods. In mid-sized environments, idle resource cleanup alone often reveals mid-five-figure annual savings.
Practice 7: Rightsize Based on Sustained Baseline Utilization
Overprovisioning is one of the most persistent forms of cloud waste. Instances are frequently sized for theoretical peak traffic rather than actual sustained demand and because cloud infrastructure runs 24/7, you pay for that oversized capacity continuously.
When rightsizing:
- Analyze 30–60 days of historical data
- Review both CPU and memory utilization
- Focus on sustained averages, not rare peaks
- Evaluate p95 usage separately from steady-state baseline
In most production environments, average compute utilization falls below 40%. A practical target for steady-state production workloads is 50–65% utilization, with autoscaling absorbing bursts.
Practice 8: Optimize Kubernetes as a First-Class Cost Driver
Kubernetes environments frequently obscure waste because cost attribution is more complex than traditional VM workloads.
Effective Kubernetes cost optimization requires:
- Requests vs. actuals: Pod CPU and memory requests that significantly exceed actual usage inflate node sizes. Use a Vertical Pod Autoscaler (VPA) to tune requests against real p95 utilization.
- Namespace-level showback: Allocate Kubernetes spend by namespace, team, or workload using labels. Without namespace showback, engineers have no cost feedback loop on their deployment decisions.
- Bin-packing efficiency: Measure requested vs. allocatable capacity per node. Persistent node utilization below 50% is a red flag. Misconfigured resource requests (especially limits=0) often result in inflated cluster sizes.
- Idle node groups and PVC lifecycle: Enforce TTL-based cleanup on ephemeral PVCs and monitor idle node groups for scale-in opportunities.
Practice 9: Schedule Non-Production Environments Intentionally
Non-production environments rarely require continuous uptime, yet many organizations run development and staging workloads 24/7 by default.
Scheduling non-production environments for business hours only (a 40-hour week vs. a 168-hour week) reduces that runtime by more than 75%. Automated shutdown policies for nights and weekends produce immediate savings without performance trade-offs.
Practice 10: Actively Manage Storage, Data Transfer, and Egress Costs
Storage costs grow gradually, which makes them easy to ignore — and they compound into significant recurring spend.
Key actions:
- Set snapshot retention policies (delete snapshots older than 60–90 days unless tagged keep)
- Implement lifecycle policies that transition infrequently accessed object storage to lower-cost tiers (e.g., S3 Intelligent-Tiering or Glacier after 30–90 days of inactivity)
- Review cross-region and cross-AZ data transfer patterns; if inter-region traffic exceeds 5–10% of total spend, architecture review is warranted
- Use private links, VPC endpoints, and service-adjacent data placement to reduce egress charges by design, not retrospectively
Data pipelines are a frequently overlooked egress source. Cloud cost optimization best practices for data pipelines include co-locating compute and storage in the same region, using AWS PrivateLink or equivalent VPC endpoint services for internal traffic, and applying budget thresholds to high-volume data transfer jobs before they run. A single AI/ML training pipeline pushing data between regions without private networking can generate egress charges in one job that erase an entire month of commitment savings.
Practice 11: Optimize AI/ML and GPU Workloads
In 2026, AI/ML infrastructure is one of the fastest-growing cloud cost categories, and it requires dedicated optimization practices.
GPU instance costs are substantially higher than general-purpose compute. AWS Spot Instances including GPU-backed instances are available at discounts of up to 90% compared to on-demand pricing, though realized savings for GPU instance types typically vary by availability zone and instance family. Spot and preemptible GPU instances require fault-tolerant training pipelines with checkpointing (every 15–30 minutes for long training runs) to handle the 2-minute interruption notice that AWS issues before reclaiming capacity.
Cost-per-inference tracking is the unit economics equivalent for AI workloads. If your inference endpoint costs $X per 1,000 requests today, that number must remain stable or decline as traffic scales otherwise the AI feature is not economically viable at scale.
Specific actions for AI/ML cost optimization:
- Use spot/preemptible instances for training jobs with checkpointing enabled
- Right-size inference endpoints using p95 request latency, not peak capacity
- Implement model serving efficiency improvements (batching, caching, quantization) before scaling compute
- Tag all AI/ML resources with a dedicated workload-type: ai-ml tag for separate tracking
Also read: GCP Cost Optimization Best Practices
Category 3: Commitment and Coverage Best Practices (Typically 30–50% Savings)
This is where true leverage lives. Instead of focusing on what to delete, this category focuses on how you purchase. Every cloud bill has a baseline of predictable usage steady-state compute, databases, and core workloads that run continuously. When that baseline runs on on-demand pricing, organizations overpay by design.
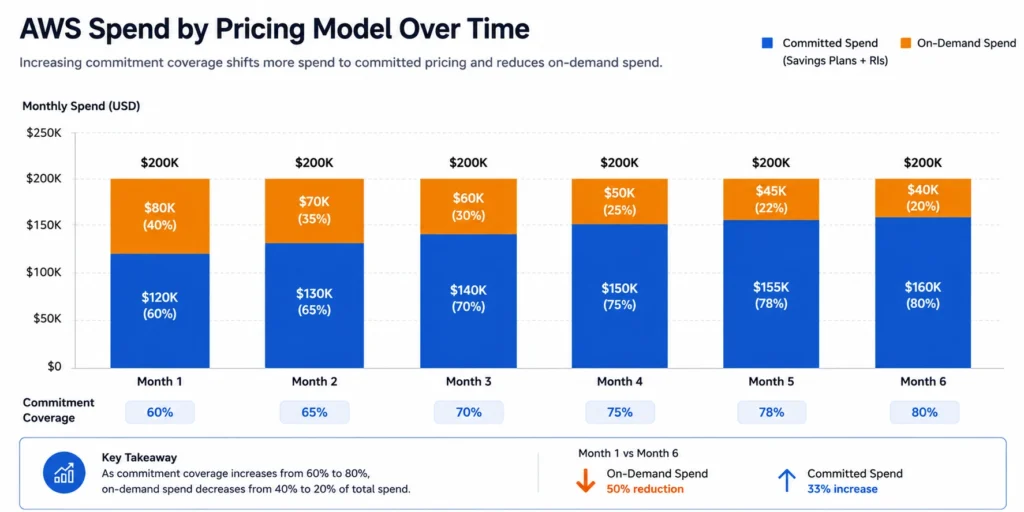
Practice 12: Understand All Commitment Instruments Before You Purchase
Before purchasing any commitment, map your workloads to the appropriate instrument. Not all commitments are created equal; they differ in scope, flexibility, and discount depth.
| Cloud | Instrument | Discount Range | Flexibility | Best For |
| AWS | Compute Savings Plans | Up to 66% | High (EC2, Fargate, Lambda, all regions) | Dynamic, mixed workloads |
| AWS | EC2 Instance Savings Plans | Up to 72% | Medium (single instance family, single region) | Stable, single-family fleets |
| AWS | Reserved Instances (Standard) | Up to 72% | Low-Medium | Specific, stable configurations |
| AWS | Spot Instances | Up to 90% | N/A (interruptible) | Fault-tolerant batch and training |
| Azure | Savings Plans for Compute | Up to 65% | High (all VM series, all regions) | Dynamic Azure VM workloads |
| Azure | Reserved VM Instances | Up to 65% (up to 72% with Hybrid Benefit) | Medium (exchangeable) | Stable VM configurations |
| GCP | Spend-based CUDs | 28–46% | High (any machine type, any region) | Mixed GCP compute |
| GCP | Resource-based CUDs | Up to 55–70% | Low (specific machine family, region) | Stable, single-family Compute Engine |
GCP resource-based CUDs offer up to 55% for most machine types and up to 70% for memory-optimized series (Google Cloud documentation).
AWS Compute Savings Plans vs. EC2 Instance Savings Plans: The Compute SP applies across all instance families, all regions, and includes Fargate and Lambda maximum flexibility, at up to 66% savings (AWS documentation). The EC2 Instance SP applies to a single instance family within a single region, offering a roughly 5–6 percentage point higher discount for that specificity, up to 72%.
Choose Compute SPs when workloads span multiple regions or you anticipate instance family changes. Choose EC2 Instance SPs when you have a highly stable, single-region, single-family baseline that has been consistent for 6+ months.
Practice 13: Model Baseline Usage Using Sustained Minimums
Commitments should cover predictable baseline, not average monthly peaks.
Baseline modeling requires 60–90 days of historical usage, hourly utilization analysis, separation of burst traffic from sustained load, and identification of minimum consistent demand. Example: if your monthly compute averages $250K but sustained minimum usage is $180K, target the $180K baseline commitment committing to the full average introduces unnecessary exposure.
Practice 14: Maintain Target Coverage Between 70–80% for Stable Compute
Full 100% coverage is rarely optimal. For stable compute environments:
- 70–80% commitment coverage balances savings and flexibility
- Lower coverage may be appropriate for volatile or experimental services
- Highly stable databases may justify higher coverage
Coverage rate formula:
| Coverage Rate = Committed Spend ÷ Eligible Baseline Spend |
Most FinOps practitioners recommend starting at 70% coverage in the first purchase cycle, then increasing toward 85–90% as confidence in the baseline grows through incremental layering.
If coverage is consistently below 60% in a stable environment, on-demand exposure is likely excessive. If coverage exceeds 90%, reassess overcommitment risk.
Also read: 7 AWS Savings Plan KPIs for Better Cost Efficiency
Practice 15: Layer Commitments Across Services Strategically
Compute is typically the starting point, but it should not be the only focus. A structured layering approach:
- Compute workloads (EC2, VMs, GCE)
- Relational databases (RDS, Azure SQL, Cloud SQL)
- Caching services (ElastiCache, Azure Cache)
- Data warehouse platforms (Redshift, BigQuery)
Database commitments often involve greater modeling complexity, but they also represent consistent baseline usage in mature environments. Ignoring non-compute commitments can leave substantial savings unrealized.
Also read: AWS Savings Plans vs. Reserved Instances: A Practical Guide
Practice 16: Reassess Commitment Allocation as Architecture Evolves
Commitments should not be static. Changes that require reassessment include: instance family migrations, region expansion, containerization or Kubernetes adoption, database engine upgrades, and traffic growth or contraction. Coverage that was appropriate six months ago may be misaligned today.
Practice 17: Address Lock-In Risk Explicitly
Under-commitment is often driven by perceived lock-in risk, not by rational analysis of the downside. Traditional AWS Savings Plans require 1- or 3-year terms and for fast-moving organizations, that creates hesitation that leaves structural discounts unrealized.
Flex Commitments address this directly. Usage.ai’s Insured Commitments deliver savings comparable to 3-year AWS Savings Plan rates while limiting financial obligation to a monthly cadence. The Guaranteed Buyback program means any underutilized commitments can be sold back cashback or credits, every dollar so rational coverage targets can move from a conservative 40–50% to the 70–80% range where structural savings materialize.
Also read: How to Choose Between 1-Year and 3-Year AWS Commitments
Practice 18: Automate Commitment Analysis and Purchasing
Manual commitment management does not scale. It requires continuous baseline recalculation, coverage tracking, utilization monitoring, and timely purchasing decisions. When commitment analysis is performed quarterly, coverage drift accumulates silently.
Automated recommendation refresh on a daily cadence allows organizations to adjust to workload changes quickly, prevent sustained on-demand exposure, and maintain target coverage bands consistently. AWS’s own recommendations are typically 72+ hours old. A daily cadence means you save $6–12K per day on a typical $5M+ cloud bill that you would otherwise miss.
Also read: Google BigQuery Committed Use Discounts (CUDs) & Optimization Guide
Practice 19: Monitor Utilization of Active Commitments
Coverage alone is insufficient. Utilization matters too.
Key metrics:
- Commitment coverage % (are enough workloads covered?)
- Commitment utilization % (are active commitments being used?)
- On-demand spend ratio (what percentage remains uncovered?)
- Underutilized commitment exposure (are you paying for unused capacity?)
Low utilization indicates overcommitment or workload drift. High on-demand exposure indicates undercommitment. Both reduce realized savings.
Practice 20: Report Realized Savings in Financial Terms
Savings must be measurable and attributable. Reports should include: total realized savings vs. prior on-demand baseline, service-level breakdown, coverage and utilization metrics, net savings after fees or program costs, and month-over-month impact. Optimization initiatives that cannot demonstrate realized financial impact lose executive support.
Also read: Multi-Cloud Cost Optimization: AWS, Azure, and GCP
How to Calculate Your Cloud Cost Savings Opportunity
The most common question before starting a commitment optimization program is: how much are we actually leaving on the table?
There are three ways to calculate your cloud cost savings opportunity:
- On-demand exposure analysis (fastest): Identify what percentage of your baseline compute runs on on-demand pricing. Multiply that amount by the applicable discount rate for your workload type. Example: $3M annual compute × 45% on-demand exposure × 35% average discount = approximately $472,500 in annualized structural overpayment.
- Coverage rate gap formula: Calculate your current coverage rate (Committed Spend ÷ Eligible Baseline Spend). If you are at 50% coverage on a stable workload that should be at 75%, the gap 25% of the eligible baseline represents your structural savings opportunity.
- Bill-based savings calculator (most accurate): Upload your AWS invoice directly to Usage.ai’s free AWS Savings Calculator. It reads your actual spend patterns, not industry averages, and returns your overspend figure in under 60 seconds with no account access, no login, and no sales call required. It identifies the gap between what you are currently paying and what you would pay with the right commitment strategy applied to your actual usage.
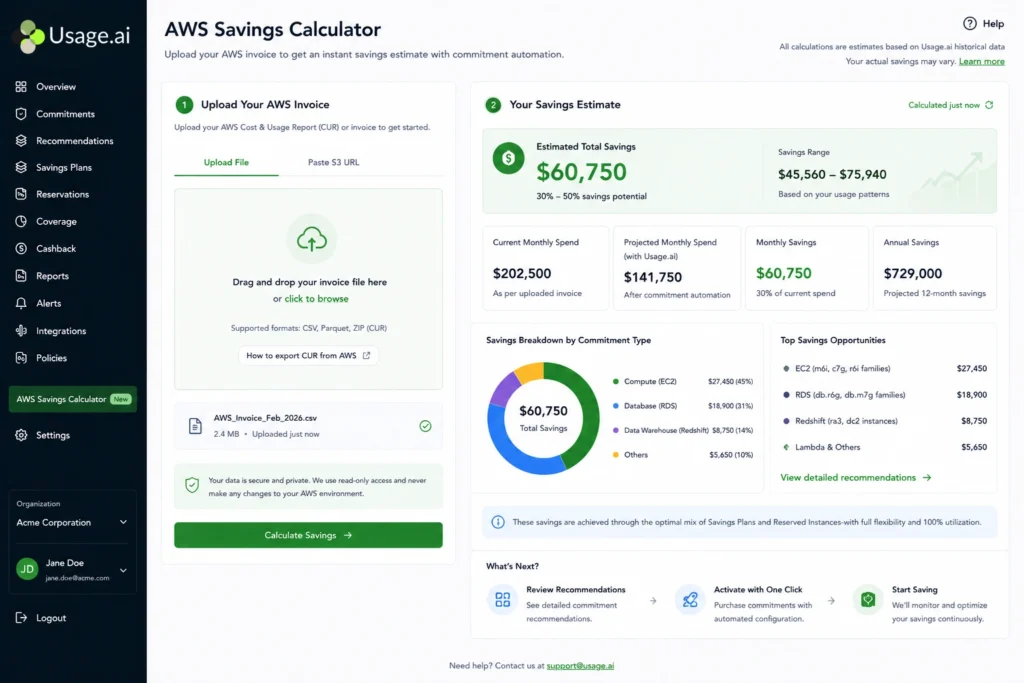
Most AWS teams run on-demand pricing for workloads that are predictable enough to qualify for Reserved Instance or Savings Plan discounts. The gap between on-demand rates and committed pricing is where 30–40% of the average AWS bill disappears every month silently, with no alert and no easy way to quantify it without a purpose-built tool.
Try the Usage.ai Savings Calculator for free →
The Cost of Delaying Commitment Optimization
By the time most teams begin actively correcting commitment coverage, structural overpayment has already accumulated. For a $5M annual cloud environment with a conservative 15% structural gap:
| Timeline | Cumulative Structural Overpayment |
| Month 1 | $62,000 |
| Month 3 | $186,000 |
| Month 6 | $375,000 |
| Month 9 | $562,000 |
| Month 12 (with automated correction) | $750,000+ recovered |
Cloud Cost Optimization Implementation Roadmap
Cloud cost optimization does not happen in a single sprint. Here is a practical implementation sequence:
| Phase | Timeline | Focus | Expected Outcome |
| Phase 1: Assessment | Week 1–2 | Tagging audit, spend analysis, on-demand exposure calculation | Baseline visibility; identification of top 3 cost drivers |
| Phase 2: Waste Elimination | Month 1 | Idle resource cleanup, rightsizing top 10 instances, non-prod scheduling | 10–20% cost reduction |
| Phase 3: Commitment Strategy | Month 1–2 | Baseline modeling, first commitment purchases at 70% coverage target | 30–50% reduction on covered workloads |
| Phase 4: Continuous Optimization | Ongoing | Daily recommendation cadence, utilization monitoring, coverage drift correction | Sustained savings as workloads evolve |
Usage.ai customers reach full coverage within 60 days compared to the 6–9 month industry average for manual implementation. That speed difference is worth $12,000 per day in recovered savings on a $5M cloud bill.
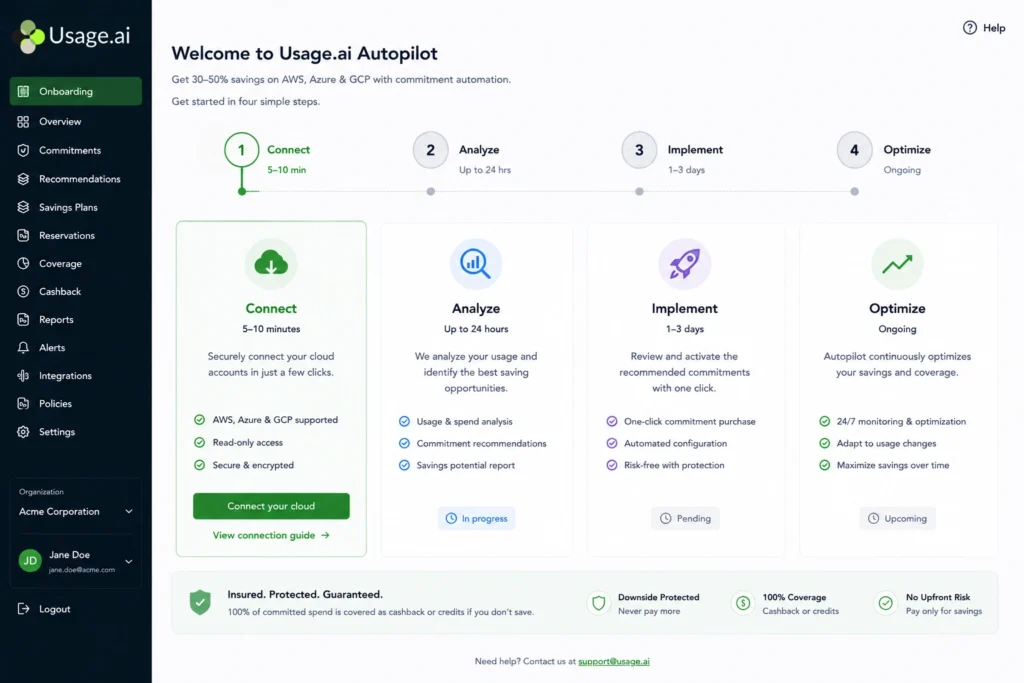
Usage.ai compresses the entire four-phase roadmap into 60 days through an automated process:
- Connect: billing-layer read access, no infrastructure changes (5–10 minutes)
- Analyze: AI identifies commitment gaps and models baseline usage against current spend
- Implement: commitments purchased automatically or with one-click approval; appear under Active Commitments
- Optimize continuously: daily recommendation refresh adjusts coverage as workloads evolve
Cloud Cost Optimization Tools
The right cloud cost optimization tool depends on whether you need visibility, automation, or both. Native provider tools provide the data foundation. Third-party platforms act on it.
Native Provider Tools
Every major cloud includes a cost management console at no additional charge:
- AWS Cost Explorer visualizes EC2 spending, generates Savings Plan and RI purchase recommendations, and tracks utilization. Billing data refreshes at least once every 24 hours; Savings Plan purchase recommendations specifically refresh on a 72+ hour cadence and do not execute automatically.
- Azure Cost Management and Billing provides budgets, alerts, and spending forecasts across Azure subscriptions. Azure Advisor surfaces rightsizing and reservation recommendations automatically.
- Google Cloud Cost Management includes billing reports, budget alerts, and Committed Use Discount recommendations within the Cloud Console. Supports label-based cost allocation across projects.
Native tools are free and well-integrated but descriptive, not autonomous; they surface recommendations but do not execute them, and Savings Plan recommendation cadences run 72+ hours behind current usage patterns.
Third-Party FinOps Platforms
Third-party platforms add automation, multi-cloud normalization, and in some cases financial guarantees on commitment performance:
| Category | Native Tools | Third-Party FinOps Platforms | Usage.ai |
| Cost visibility | ✓ Single cloud | ✓ Multi-cloud | ✓ Multi-cloud |
| Commitment recommendations | ✓ Slow cadence (72h+) | ✓ Varies | ✓ Daily (24h) |
| Autonomous execution | ✗ | Varies | ✓ Autopilot |
| Underutilization protection | ✗ | ✗ Most | ✓ Guaranteed Buyback |
| Coverage: AWS, Azure, GCP | Single cloud each | Most | ✓ All three |
| Pricing model | Free | Subscription or % of spend | % of realized savings only |
Usage.ai’s differentiation is the financial structure: it purchases commitments on your behalf, absorbs the underutilization risk, and charges only a percentage of the savings it actually delivers. If it does not save you money, you pay nothing. Setup requires billing-layer read access only no infrastructure changes, no code changes.
Conclusion
Cloud cost optimization best practices are often presented as checklists. The underlying pattern is more structural: cloud waste is rarely just unused infrastructure more often it comes from predictable workloads running on the wrong pricing model. Sustained savings come from aligning baseline demand with discounted commitments and maintaining that alignment as workloads evolve.
That level of consistency is difficult to maintain manually, especially in multi-cloud environments where usage shifts daily. This is the gap Usage.ai is designed to close by continuously analyzing usage across AWS, Azure, and GCP, refreshing commitment recommendations on a daily cadence, and automating execution within defined coverage targets.
Cloud infrastructure will continue to grow. The question is whether it grows on on-demand pricing or disciplined commitment coverage. The difference is measurable.
See how much you’re currently overpaying AWS. Run your free savings calculation in 60 seconds →

Frequently Asked Questions
1. What is cloud cost optimization?
Cloud cost optimization is the practice of reducing cloud spending while maintaining performance and business value by combining three layers: visibility into where spend goes, elimination of idle and oversized resources, and alignment of baseline workloads with discounted commitment instruments (Savings Plans, Reserved Instances, or Committed Use Discounts).
2. What are the most effective cloud cost optimization best practices?
The most effective cloud cost optimization best practices combine all three layers: (1) establish cost visibility with ≥90% tagging compliance and on-demand exposure tracking; (2) eliminate waste through rightsizing, idle resource cleanup, and non-production scheduling; and (3) align baseline workloads with commitment instruments AWS Savings Plans, Reserved Instances, Azure Reservations, or GCP Committed Use Discounts targeting 70–80% coverage. Teams that implement all three layers consistently achieve 30–50% total cost reductions.
3. What is FinOps?
FinOps is a cultural and operational framework that aligns finance, engineering, and operations teams around shared accountability for cloud spending treating cloud costs as a financial discipline rather than a periodic cleanup exercise.
4. How much can you realistically save with cloud cost optimization?
Organizations that optimize only for waste reduction (idle resources, rightsizing) typically achieve 10–20% savings. Teams that also optimize commitment coverage ensuring predictable workloads run on discounted instruments achieve 30–50% total reductions. Usage.ai customers have collectively recovered over $91M in cloud savings, with individual customer outcomes including $5.2M, $2.3M, and $1.8M in verified annual savings.
5. What is the difference between AWS Reserved Instances and Savings Plans?
AWS Savings Plans commit to a consistent dollar amount of compute spend per hour (1- or 3-year term) and automatically apply discounts across EC2, Fargate, and Lambda across all regions and instance families up to 66% for Compute SPs and up to 72% for EC2 Instance SPs. Reserved Instances commit to a specific instance configuration and offer up to 72% discounts (Standard RIs, 3-year all-upfront). RIs are best for highly stable, unchanging workloads; Savings Plans for dynamic or evolving fleets. AWS does offer a 7-day return window for Savings Plans, but it applies only to plans with an hourly commitment of $100 or less, purchased within the same calendar month. Most mature FinOps teams use both.
6. What is the commitment coverage rate?
Commitment coverage rate is the percentage of eligible baseline cloud spend covered by discounted commitment instruments (Savings Plans, Reserved Instances, CUDs) rather than running at on-demand pricing. It is calculated as: Coverage Rate = Committed Spend ÷ Eligible Baseline Spend. A target of 70–80% is appropriate for most stable compute environments. Coverage consistently below 60% on predictable workloads signals structural overpayment.
7. How do you calculate cloud cost savings?
There are three methods:
- On-demand exposure analysis (fastest): Multiply your baseline on-demand spend by the average discount available for your workload type.
- Coverage rate gap analysis: Identify the gap between your current coverage rate and your 70–80% target, then calculate the dollar value of that gap.
- Bill-based savings calculator (most accurate): Usage.ai’s free AWS Savings Calculator reads your actual AWS invoice and returns your overspend figure in under 60 seconds with no account access required.
8. How often should you review cloud costs?
Anomaly detection should run continuously. Commitment coverage and utilization should be reviewed weekly. Comprehensive cost and optimization reviews work best monthly, with commitment strategy reassessments quarterly.
9. What tools are used for cloud cost optimization?
Native provider tools (AWS Cost Explorer, Azure Cost Management, Google Cloud Cost Management) provide baseline visibility but limited automation. Third-party FinOps platforms add multi-cloud normalization, rightsizing recommendations, and commitment purchasing. Usage.ai provides autonomous commitment optimization with a 24-hour recommendation refresh, Insured Commitments with Guaranteed Buyback on underutilization, and coverage across AWS, Azure, and GCP.
10. How do spot instances reduce cloud costs?
Spot instances (AWS) and preemptible VMs (GCP) offer discounts of up to 90% compared to on-demand pricing, in exchange for the possibility of interruption when the cloud provider needs that capacity back. They are well-suited for fault-tolerant batch processing, data pipeline jobs, and AI/ML training workloads with checkpointing enabled. They are not appropriate for latency-sensitive or stateful production workloads that cannot tolerate interruption.
11. What is a FinOps maturity model?
The FinOps maturity model describes three stages of cloud financial management capability. In the Crawl stage, teams focus on gaining basic visibility tagging, cost allocation, and identifying top spend drivers. In the Walk stage, teams act on optimization recommendations at scale rightsizing, commitment purchasing, and anomaly management. In the Run stage, optimization is automated and the focus shifts to unit economics: cost per customer, cost per inference, cost per deployment.
12. How long does cloud cost optimization take to implement?
Waste reduction (idle resource cleanup, initial rightsizing) produces results within the first two to four weeks. Commitment optimization typically requires 60–90 days to reach full coverage manually during which time structural overpayment continues to accumulate. Using an automated platform like Usage.ai, most customers reach full coverage within 60 days, compared to the 6–9 month industry average. The average daily cost of delay on a $5M cloud bill is approximately $12,000.
13. What is Usage.ai and how does it help with cloud cost optimization?
Usage.ai is an automated cloud cost optimization platform that purchases and manages Savings Plans, Reserved Instances, and Committed Use Discounts on your behalf across AWS, Azure, and GCP. It uses AI/ML-powered recommendations refreshed on a 24-hour cadence, purchases commitments autonomously via Autopilot mode (or with one-click approval in manual mode), and provides a Guaranteed Buyback cashback or cloud credits for any underutilized commitments. Pricing is a percentage of realized savings only; if Usage.ai does not save you money, you pay nothing. Setup takes 30 minutes with billing-layer access only no infrastructure changes.


