.png)


Most teams modeling their AI spend are looking at the wrong number. Token pricing from the model provider is what gets quoted in every architecture decision, but for many production setups it represents only a portion of total AI infrastructure cost. GPU compute, vector database retrieval fees, storage, cross-region egress, and agentic amplification all sit on top of that number, and none of them appear on the LLM pricing page.
AI infrastructure cost allocation is knowing which team, product, or workflow generated which portion of that bill. It is the core unsolved problem in FinOps for AI, and the layer most organizations have not yet built. This breakdown covers all six cost layers with real 2026 numbers and answers the question engineering and finance teams are consistently stuck on: which team actually owns each line item, and how do you build the attribution layer to prove it?
What Is AI Infrastructure Cost Allocation?
AI infrastructure cost allocation is the process of attributing cloud AI spend to the specific teams, products, workloads, or business outcomes that generated it. Today, most organizations can see their total AI bill, but very few can break it down by team, feature, or cost-per-outcome.
Without allocation, AI spend looks like an undifferentiated infrastructure cost rather than a per-product investment. Engineering teams cannot justify AI budget increases they cannot attribute. Finance teams cannot forecast spend they cannot segment. And FinOps teams cannot optimize what they cannot see at the workload level.
The allocation problem is distinct from the cost reduction problem. You can reduce your token bill by switching models. You cannot answer “which team drove the $40K increase last month” without an attribution layer built on top of your infrastructure and that layer requires deliberate tagging decisions at the architecture stage, not after the bill arrives.
Layer 1: LLM Inference Costs & Who Owns the Token Bill
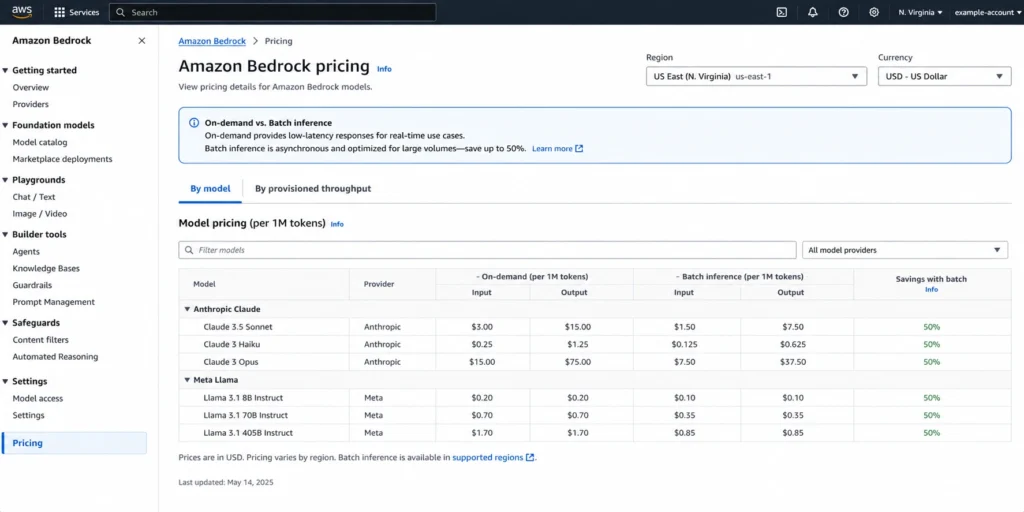
Token pricing is the most predictable layer once you understand a few mechanics and it is also the most visible, which is why teams over-index on it relative to other layers.
On-demand token rates as of 2026, us-east-1 are (verify at aws.amazon as rates change):
| Model | Input per 1M tokens | Output per 1M tokens |
| Claude Sonnet 4.6 (Bedrock) | $3.00 | $15.00 |
| Claude Haiku 4.5 (Bedrock) | $1.00 | $5.00 |
| Amazon Nova Micro | $0.035 | $0.14 |
| Amazon Nova Lite | $0.06 | $0.24 |
| Meta Llama 3.3 70B | $0.72 | $0.72 |
| Mistral Large 2 | $3.00 | $9.00 |
Output tokens cost 3x to 5x more than input tokens on most frontier models. For applications where the model generates verbose responses like summaries, code generation, and customer support, output tokens dominate the bill.
Allocation owner: the product team or application that calls the API
Bedrock aggregates all token usage to a single line item by default. Without application-layer request tagging, there is no native way to separate the token spend of your internal knowledge assistant from the token spend of your customer-facing chatbot. The tagging decision must happen at the application layer, where you add team, environment, and feature metadata to every inference call before the first production deployment.
The two optimizations that move this number most:
Prompt caching delivers roughly 90% off cached input tokens on supported Claude models via Bedrock. A static system prompt repeated across millions of requests is the highest-cost inefficiency on this layer. Bedrock added 1-hour TTL caching for Claude Sonnet 4.5, Haiku 4.5, and Opus 4.5 in early 2026; verify current model availability at aws.amazon before architecting around it.
Batch API pricing is a flat 50% discount for non-real-time workloads. Nightly document processing, evaluation runs, and batch classification all qualify. If a workload is not latency-sensitive and is running on-demand, it is paying a 2x premium. Identifying and routing these workloads automatically is a core FinOps automation pattern.
| Spending on AI infrastructure but not sure where the waste is?
Usage.ai connects to your AWS, GCP, or Azure billing layer in 30 minutes and surfaces commitment savings of 30-50%. $0 Upfront, zero lock-in, buyback guarantee on every commitment purchased. |
Layer 2: GPU Compute: The Largest Cost Layer for Self-Hosted Workloads
For organizations running their own model training, fine-tuning, or self-hosted inference, GPU compute is the dominant cost driver. The per-hour rate does not stop when the GPU is idle, and utilization metrics frequently misrepresent actual spend efficiency.
AWS GPU instance on-demand pricing, us-east-1 are (verify at aws.amazon as rates change):
| Instance | GPU | GPUs | On-Demand/hr | Monthly (continuous) |
| g5.xlarge | NVIDIA A10G | 1 | ~$1.01 | ~$730 |
| p4d.24xlarge | NVIDIA A100 40GB | 8 | ~$32.77 | ~$23,595 |
| p5.48xlarge | NVIDIA H100 80GB | 8 | ~$98.32 | ~$71,770 |
Note: hourly rates above are sourced from third-party benchmarks and cross-referenced against community sources. Verify current rates directly at aws.amazon before budgeting. GPU instance pricing changes as AWS introduces new generations.
Allocation owner: the ML platform or infrastructure team
GPU compute is the hardest layer to allocate because instances are typically shared across multiple workloads and teams. A p4d cluster used by three different ML teams for different training jobs requires job-level tagging at the SageMaker or EKS layer to produce any per-team attribution. Without that instrumentation, the cost is invisible at the business unit level.
What Reserved Instances save and where the lock-in risk sits
A 1-year Reserved Instance on a p4d.24xlarge saves approximately 30-40% versus on-demand. A 3-year term saves approximately 55-62%. The commitment risk is real: AI workload requirements change faster than most 3-year terms can accommodate. Teams that locked into A100-based P4 capacity when P5 (H100) instances became relevant for new workloads absorbed either stranded reservation costs or on-demand premiums for the newer hardware.
How to cut GPU compute costs without committing to hardware generations
Spot instances save 60-70% on G5 instances and 50-70% on P4/P5 instances, with the trade-off of a 2-minute reclaim warning. For training workloads, checkpointing handles this cleanly as SageMaker Managed Spot Training automates checkpoint management. For inference serving, spot is not appropriate as a primary capacity layer without a fallback.
Right-sizing is the highest-return action that requires no pricing model change. A g5.2xlarge (1x A10G, 24 GB) handles models up to approximately 13B parameters for inference. Running a 7B parameter model on a p4d.24xlarge (8x A100) wastes most of the available GPU capacity while incurring the full instance cost. For a full breakdown of GPU right-sizing, Spot strategies, and cross-cloud GPU pricing, see our guide to GPU cost optimization across AWS, GCP, and Azure.
How Usage.ai addresses the GPU commitment problem
Usage.ai’s Insured Flex Commitments deliver SP/RI-equivalent discounts of 30-60% on AWS compute, including GPU instance families covered by EC2 Savings Plans without requiring multi-year lock-in or upfront payment. Every commitment is fully insured: if your GPU workload shifts, scales down, or moves to a different instance family, the underutilized portion is returned as cashback (real money, not credits). Commitments adjust quarterly. Cancel anytime.
This is the structural difference from standard Reserved Instances. If an AI team migrates from P4 to P5 hardware mid-year, a standard RI continues billing for unused P4 capacity. With Usage.ai’s Insured Flex Commitments, the underutilized portion is bought back.
See how Usage.ai handles GPU compute commitments without lock-in →
Layer 3: Vector Databases and Retrieval: The Hidden RAG Tax
RAG (Retrieval-Augmented Generation) architectures are now standard for enterprise AI. They also add two distinct cost layers that token pricing calculators do not capture: retrieval infrastructure and inflated input token counts from stuffed context.
Every RAG query sends retrieved document chunks into the prompt as input tokens. A query with 10,000 tokens of retrieved context on Claude Sonnet 4.6 costs $0.03 in input tokens alone, before the model generates a single output token. At 50,000 monthly queries, that is $1,500 in input token costs from context injection alone, separate from the query itself.
The infrastructure underneath looks like this:
- Bedrock Knowledge Bases (OpenSearch Serverless backend): AWS OpenSearch Serverless pricing carries a minimum OCU (OpenSearch Compute Unit) charge. Multiple third-party sources report effective minimum monthly costs of approximately $700-800 for low-volume deployments. This figure should be verified at aws.amazon before using it in a budget. AWS pricing structure for OpenSearch Serverless has changed previously and the floor cost is not prominently displayed in the pricing page headline.
- Pinecone, Weaviate, or self-managed alternatives: Pinecone’s Starter tier is free; production workloads typically run $70-500/month depending on vector count and query throughput. Self-managed Weaviate or Qdrant on EC2 shifts the cost to compute and operational overhead.
- Embedding costs: Amazon Titan Embeddings is priced at approximately $0.10 per million tokens (verify at aws.amazon). For a 10 million document corpus at an average of 500 tokens per document, the initial embedding run costs approximately $500. Re-embedding on document updates adds incrementally.
Allocation owner: the team or product that owns the knowledge base
A shared RAG knowledge base serving multiple product teams creates the same allocation problem as shared GPU infrastructure. Attribution requires tagging at the query layer where each retrieval call should carry metadata identifying which application or team initiated it.
Layer 4: Storage: The Cost That Compounds Quietly
Training datasets, model checkpoints, inference logs, and intermediate activations consume storage that teams frequently underestimate because it compounds over time rather than appearing as a single large line item.
Reference storage costs in AWS, us-east-1 are (verify at aws.amazon as rates change):
- S3 Standard: $0.023/GB/month
- EBS gp3: $0.08/GB/month
- S3 Intelligent-Tiering: varies by access frequency (starts at $0.023/GB for frequent access tier)
A 5 TB training dataset on S3 costs approximately $115/month. That same dataset on EBS for faster training I/O costs approximately $400/month. Model checkpoints for a 70B parameter model in BF16 format consume roughly 140 GB per checkpoint. Daily checkpointing over a 30-day training run adds approximately $336/month in EBS costs that rarely appear in initial AI budget models.
CloudWatch log ingestion in US regions is priced at approximately $0.50/GB ingested and $0.03/GB stored. Full prompt-and-response logging for compliance generates log volume that can meaningfully inflate the storage bill at high inference volume. Model this cost explicitly before enabling full logging in production.
Allocation owner: the team running the workload, instrumented via S3 bucket tagging
S3 bucket-level cost allocation tags are the most reliable method for storage attribution. Separate buckets per team or product line, combined with Cost Allocation Tags, make storage the easiest layer to allocate accurately, provided the tagging strategy is established before data lands.
Layer 5: Agentic Amplification: The Cost Multiplier Built Into Your Architecture
This is where AI budgets break down at scale. Agentic workflows do not consume tokens proportionally to what a user sees at the application layer. A single user question to an AI agent may trigger multiple internal inference calls, like tool use, self-correction, retry loops, and reasoning steps, each billed at standard per-token rates.
The amplification mechanics:
A single agentic request that appears as one user-model exchange may actually generate:
- 1 initial inference call (user prompt + system prompt)
- 2-3 tool-use calls (knowledge base retrieval, API calls, database queries)
- 1-2 synthesis calls (combining tool results)
- 0-3 retry calls on tool failures
A workload described as 5,000 monthly requests at the application layer can produce 25,000 to 50,000 Bedrock inference calls. Teams that prototype with direct model calls and then deploy agents without revising their cost models regularly see bills 5x to 10x their initial projection.
How to reduce AI agent compute cost without changing model or architecture
Bedrock Agents supports maximum step limits per agent session. Setting a loop budget cap of 5-8 steps on agents that typically complete in 3 steps reduces the worst-case cost ceiling without affecting normal operation. This is an architectural decision and requires defining how much iteration is acceptable before the agent returns a partial result rather than continuing to retry.
Model cascading also applies here: route simple sub-tasks within an agentic workflow to cheaper models (Nova Micro, Haiku) and reserve frontier models for reasoning steps that require it. The routing cost is approximately $1.00 per 1,000 requests via Bedrock Intelligent Prompt Routing (verify at aws.amazon.com/bedrock/pricing); if it diverts even 30% of agent steps to cheaper models on a high-volume workflow, the net saving is significant. For tools that automate this routing layer, see our roundup of AI agents built specifically for FinOps workflows.
Allocation owner: the team that deployed the agent
Agent token amplification makes per-request cost attribution harder because the billing layer sees many more calls than the application layer. The fix is session-level tagging: tag every agent session with the initiating application and user cohort at session creation. This surfaces per-agent cost profiles that per-request attribution misses.
Layer 6: Egress and Data Transfer: The Charge Nobody Modeled
Data movement across regions, from AWS to the internet, and between services carries transfer charges that do not appear on any LLM or GPU pricing page.
Key data transfer rates are (verify at aws.amazon as rates change):
- Cross-region transfer: $0.02/GB (varies by region pair)
- Outbound to internet, first 10 TB/month: $0.09/GB
- Cross-AZ transfer: $0.01/GB per direction
For multi-node distributed GPU training across Availability Zones, inter-node data transfer runs $0.01/GB per direction. A training job moving 1 TB of gradient updates and checkpoints between nodes daily over 30 days adds approximately $600/month in transfer costs that appear nowhere in the GPU instance pricing.
Cross-region inference on Bedrock adds a 10% surcharge to all token pricing when enabled. A team spending $1,000/month on inference who enables cross-region routing for availability pays an additional $100/month. Always verify your Bedrock configuration as this setting is not always obvious in the console.
The AI Infrastructure Cost Allocation Framework: Who Owns Each Layer
Most engineering teams can see their total AI spend. Few can break it down by team, product, or workload. This section maps ownership and attribution method by layer.
| Layer | Default AWS Billing View | Allocation Owner | Attribution Method |
| LLM Inference (tokens) | Single Bedrock line item | Product/application team | Application-layer request tags (team, env, feature) |
| GPU Compute | EC2 line item by instance type | ML platform / infra team | SageMaker job tags or EKS namespace tagging |
| Vector Database | OpenSearch or third-party line | RAG application owner | Query-layer metadata; separate indexes per team |
| Storage | S3/EBS by bucket/volume | Workload owner | S3 bucket tags; Cost Allocation Tags per bucket |
| Agentic Amplification | Bedrock inference (inflated) | Agent-deploying team | Session-level tagging at agent session creation |
| Egress | Data Transfer line item | Infra / platform team | VPC Flow Logs + Cost Allocation Tags on NAT GW |
The four-step allocation build:
- Tag every Bedrock API call at the application layer with environment (prod/staging/dev), team name, and product feature. Bedrock does not auto-tag by caller, so this must be instrumented before deployment, not retrofitted.
- Use AWS Cost Allocation Tags at the account level to separate spend by business unit. For multi-team organizations, separate AWS accounts per team give the cleanest billing separation with the least tagging overhead.
- For shared GPU infrastructure, instrument job-level tagging in SageMaker training jobs or EKS namespace labels. Allocate cost proportionally by GPU-hours consumed per job type. Without this, all GPU cost is invisible at the team level.
- Build cost-per-outcome metrics, not just cost-per-request. Cost per completed support ticket. Cost per code review. Cost per document processed. These are the metrics that make AI spend legible to finance and product leadership and they are the metrics that distinguish productive AI investment from infrastructure waste.
Why allocation enables optimization, not just reporting
Organizations with proper cloud cost visibility can attribute AI spend by team and product, surfacing optimization opportunities that aggregate billing misses entirely. A team running a nightly batch job on on-demand pricing is visible as a distinct workload once tagged and is immediately identifiable as a batch-pricing candidate (50% discount). Without attribution, it disappears into the aggregate Bedrock line item.
| Your AI infrastructure has a GPU commitment problem.
Reserved Instances on GPU instances lock you in for 1-3 years. Usage.ai’s Insured Flex Commitments deliver the same 30-60% discount with quarterly adjustments, cancel-anytime, and cashback on any underutilized capacity. |
What Does a Full AI Infrastructure Stack Cost? A Worked Example
Scenario: A mid-market SaaS company running an AI-powered customer support assistant.
Setup:
- 50,000 monthly queries, average 3,000 tokens of retrieved context per query (RAG), 500 tokens output
- Claude Haiku 4.5 on Bedrock (on-demand)
- Bedrock Knowledge Base (OpenSearch Serverless backend)
- Full prompt-and-response logging via CloudWatch
- No batch processing or prompt caching enabled
Baseline monthly cost estimate (verify component pricing before budgeting):
| Layer | Component | Monthly Estimate |
| LLM Inference | 150M input tokens at $1.00/1M | $150 |
| LLM Inference | 25M output tokens at $5.00/1M | $125 |
| Vector Database | OpenSearch Serverless minimum | ~$700 (verify at aws.amazon.com/opensearch-service/pricing) |
| Storage | S3 for document corpus (500 GB) | ~$12 |
| Logging | CloudWatch (50 GB logs) | ~$26 |
| Total | ~$1,013/month |
Apply prompt caching and shift non-real-time queries to batch pricing:
- Prompt caching on the system prompt portion: approximately $15 in input tokens vs the previous $90 on cached portions (90% reduction).
- Batch pricing on asynchronous queries: approximately $62 in LLM inference vs previous $125 (50% reduction).
- Revised total: approximately $815/month, a 20% reduction from two configuration changes, no infrastructure change required.
Add agentic routing to 20% of queries:
10,000 queries routed through a Bedrock Agent generate approximately 5x the expected token volume from internal tool calls. LLM inference for those queries increases from approximately $28 to $140. Revised total with agents then becomes approximately $927/month. This is the number that surprises teams who modeled only direct inference.
How Do AI Infrastructure Costs Compare Across AWS, GCP, and Azure?
Managed inference rates are broadly comparable across Bedrock, Vertex AI, and Azure OpenAI for equivalent models. GPU compute pricing varies more meaningfully as GCP’s A100 instances have historically been priced approximately 15-20% lower per GPU-hour than the equivalent AWS offering, though this gap narrows when ecosystem, compliance, and managed tooling costs are factored in. For a full cost comparison across all three managed inference platforms, including why your LLM bill runs 1.5-2x the token pricing page suggests, see the Bedrock vs Vertex AI vs Azure OpenAI breakdown.
Reference comparison (verify all figures at official provider pricing pages before using in a budget as rates change):
| Dimension | AWS | GCP | Azure |
| Managed LLM inference | Bedrock; pay-per-token | Vertex AI; pay-per-token | Azure OpenAI; pay-per-token |
| A100 compute (8-GPU, on-demand) | ~$32.77/hr (p4d.24xlarge) | ~$26.24/hr (a2-highgpu-8g) | ~$29.40/hr (NC A100 v4) |
| Vector DB (managed) | OpenSearch Serverless | Vertex AI Vector Search | Azure AI Search |
| Commitment discount depth | Up to 62% (RI/SP, 3-yr) | 28-52% (CUD) | 20-40% (Reserved) |
The Azure NC A100 v4 hourly rate above is sourced from third-party benchmarks. Verify at azure.microsoft before budgeting.
Usage.ai covers AWS, GCP, and Azure commitment automation under a single platform. Teams running multi-cloud AI workloads can apply Insured Flex Commitments across all three providers without managing separate reservation strategies per cloud.
| Stop paying on-demand rates for predictable AI compute.
Usage.ai automates commitment purchasing across AWS, GCP, and Azure with a buyback guarantee if your usage changes. Setup takes 30 minutes. You pay only a percentage of realized savings. If Usage.ai saves you nothing, you pay nothing. |

Frequently Asked Questions
1. What is AI infrastructure cost allocation?
AI infrastructure cost allocation is the process of attributing cloud AI spend like tokens, GPU compute, storage, vector databases, and egress to the specific teams, products, or workloads that generated it. Most cloud providers aggregate AI costs to a single billing line item. Allocation requires tagging at the application layer, separate instrumentation for shared GPU infrastructure, and cost-per-outcome models that connect infrastructure spend to the business results it produces.
2. What does AI infrastructure cost per month for a production workload?
Production AI infrastructure costs range widely depending on architecture. A RAG-based customer support assistant handling 50,000 monthly queries runs approximately $800-1,200 per month on managed inference with a vector database backend. An organization running continuous GPU training on A100 instances may spend $20,000-70,000 per month on compute alone before applying reserved pricing. The range is that wide because GPU compute costs far more per unit of AI capability than managed token inference and most teams underestimate non-inference layers like vector databases and agentic amplification.
3. Why is my AI bill higher than my initial estimate?
The most common causes are agentic workflows amplifying token consumption 5x-10x beyond initial projections; minimum infrastructure charges for managed vector database services regardless of usage volume; cross-region inference surcharges on Bedrock adding approximately 10% to all token costs when enabled; and system prompt repetition without prompt caching. Production AI bills frequently exceed initial estimates. Prompt caching, batch pricing, and tighter agent loop budgets are the three fastest levers to close the gap.
4. How do you reduce AI token costs in cloud computing?
The highest-return actions: enable prompt caching on any static or semi-static system prompt (approximately 90% off cached input tokens on supported models); shift non-real-time workloads to Batch API pricing (50% discount); use smaller models for routing and classification tasks that do not require frontier reasoning. Amazon Nova Micro at $0.035/1M input tokens costs approximately 85x less than Claude Sonnet 4.6 for structured extraction. Combine these three and most teams see 40-60% reduction in managed inference costs without changing their core model or architecture.
5. How much can Reserved Instances reduce AI GPU costs on AWS?
A 1-year Reserved Instance on a p4d.24xlarge saves approximately 30-40% versus on-demand pricing. A 3-year term saves approximately 55-62%. The meaningful risk is that AI workload requirements change faster than most 3-year commitment terms accommodate. Usage.ai’s Insured Flex Commitments deliver comparable discounts without multi-year lock-in, where commitments adjust quarterly, and underutilized portions are returned as cashback.
6. Does Usage.ai support GPU instance commitments?
Yes. Usage.ai’s Insured Flex Commitments apply to EC2 Savings Plans, which cover GPU instance families used for AI workloads. The platform automates commitment purchasing based on actual usage patterns. Usage.ai covers multi-cloud AI workloads across AWS, GCP, and Azure under a single platform, with $0 upfront and a buyback guarantee on every commitment purchased. For specific GPU instance family coverage, verify with the team directly at usage.ai.
7. What is the difference between AI infrastructure cost and AI infrastructure cost allocation?
AI infrastructure cost is the total spend across compute, inference, storage, and data transfer. AI infrastructure cost allocation is the process of attributing that spend to the specific team, product, or workflow that generated each portion. Cost without allocation is a budget item. Cost with allocation is an operational signal, as it tells you which workloads are efficient, which teams are over-provisioned, and where optimization actions produce measurable business outcomes rather than just lower aggregate bills.


